

In questo articolo:
- Qualcuno ha detto coltellino svizzero?
- Che cos’è Python
- Python può essere usato per imparare a programmare
- I pregi principali per imparare a programmare su Python (più un difettuccio)
- Perché scegliere proprio Python rispetto ad altri linguaggi
- Imparare Python con la geometria della tartaruga
- Con Python si programma senza confini
- Costruire un chatbot in meno di un’ora con Python
- Creare una rete neurale con Python
- Che cos’è una rete neurale nella pratica
- Organizzare un flusso di dati incessante con Python
- Fare web scraping con Python
- Analizzare il linguaggio con Python e librerie open source
- Python per creare un’interfaccia di programmazione applicativa per ebook
- Python alla frontiera della data science e del machine learning
- Python: linguaggio ideale per applicarsi nel machine learning
- Perché vari esperti di data science preferiscono Python ad altri linguaggi, anche specializzati
- Data science con Python: cominciare dalle cose semplici
- Analisi con Python e pandas della casualità delle classifiche in un torneo di calcio
- Analisi con Python dei commenti su un forum di appassionati della serie televisiva The Good Wife
- La forza di Python sta nella comunità. Anche in Italia
- Django Girls: ragazze che usano Python con orgoglio
- Firenze, l’ombelico di Python in Italia: benvenuti a PyCon
Qualcuno ha detto coltellino svizzero?
Quale strumento può risolvere ogni situazione, prevista o inaspettata, senza mai essere il meglio in assoluto ma sempre con una risorsa più degli altri?
Per moltissimi che programmano, a tutti i livelli di capacità e ambizione, la risposta è Python. Abbiamo dato numerose spiegazioni ed esempi di questo fatto, come si può vedere nei prossimi paragrafi.
Che cos’è Python
La partenza più elementare: Python è un linguaggio di programmazione, libero e aperto, adatto a ogni età e livello di apprendimento, condiviso da una comunità globale e italiana di appassionati ed esperti, utilizzabile su qualsiasi computer, compresi tablet e smartphone.
Python può essere usato per imparare a programmare
Scrive Naomi Ceder, presidente del consiglio di amministrazione della Python Software Foundation e autrice di Python – Guida alla sintassi, alle funzionalità avanzate e all’analisi dei dati:
Delle molte cose che mi piacciono di Python, probabilmente la migliore è il modo in cui si adatta al tuo cervello… in generale puoi ragionare attorno al linguaggio senza doverti preoccupare di incoerenze e eccezioni.
Ceder arriva dallo studio delle lingue antiche e qualche volta dice di essersi spostata da una lingua all’altra. Lo studio delle lingue antiche richiede pazienza, pensiero attento ai dettagli e capacità di dare un significato coerente a più dettagli riuniti assieme. Poi bisogna voler imparare e mettere alla prova differenti sintassi, modi diversi di esprimere un’idea. Tutte queste abilità sono molto utili per la programmazione e in effetti molti anni fa le aziende informatiche reclutavano gli studiosi di lingue antiche.
I pregi principali per imparare a programmare su Python (più un difettuccio)
Maurizio Boscaini, autore di Imparare a programmare con Python e ricco di esperienza di insegnamento della programmazione nelle scuole, riassume così i vantaggi di questo linguaggio dal punto di vista dell’apprendimento:
- La concisione e la chiarezza: in Imparare a programmare con Python i programmi più lunghi hanno meno di 85 linee di codice, sono (abbastanza) comprensibili e riescono a produrre un risultato di calcolo e grafico non banale.
- La fantastica community che ruota attorno al linguaggio.
Nessuno è perfetto, neanche Python ed è bene saperlo prima di cominciare: tra i punti critici si trova l’ambiente di sviluppo ufficiale IDLE, incluso nell’installazione standard, che sarebbe bello vedere più professionale; e poi alcuni aspetti del linguaggio sono migliorabili per chi si accosta per la prima volta, come per esempio __main__ che è un po’ criptico con quel doppio underscore iniziale e finale.
Un altro vantaggio, forse decisivo, è che ci sono strumenti per imparare a programmare con Python anche via cellulare o tablet, grazie a strumenti come Kivy.
Perché scegliere proprio Python rispetto ad altri linguaggi
L’offerta di linguaggi di programmazione è sterminata, per quale motivo varrebbe la pena di adottare proprio Python e non altro? Sempre Naomi Ceder offre spunti di riflessione sulla convenienza di programmare con Python:
- È un linguaggio di concezione moderna, nato negli anni novanta.
- I programmatori abituati a linguaggi più tradizionali si trovano comunque a casa loro, perché hanno a disposizione tutti i costrutti tradizionali.
- Il linguaggio è internamente molto libero nel trattare contemporaneamente dati di natura differente (numeri, sequenze di caratteri, liste eccetera).
- Python lavora a un livello di astrazione molto elevato: moltissime operazioni complicate sono già pronte in una libreria specializzata. Basta usare quelle e contornarle con il codice necessario: un programma che scarica pagine web può essere scritto in due righe. Lo stesso vale per un server che condivide in rete i file di una cartella:
import http.server
http.server.test(HandlerClass=http.server.SimpleHTTPRequestHandler) - La sintassi è semplice e consente a un principiante di iniziare molto velocemente a scrivere codice, anche se come sempre diventare un programmatore esperto richiede tempo e fatica.
- Python è espressivo: una riga di codice può fare più di una riga di codice in altri linguaggi.
Un esempio: proviamo a scambiare i valori di due variabili (come dire scambiamo il contenuto di due cassetti). Nella vita reale e nei linguaggi di programmazione tradizionali serve più di un passaggio, perché il contenuto di un cassetto può essere spostato nel secondo cassetto solo che quest’ultimo sia stato svuotato. Invece Python riesce a effettuare lo scambio in contemporanea, come se gli oggetti saltassero spontaneamente da un cassetto all’altro nello stesso momento, con un codice di questo tipo:
cassetto2, cassetto1 = cassetto1, cassetto2
Imparare Python con la geometria della tartaruga
Uno dei primi approcci all’insegnamento della programmazione fu Logo di Seymour Papert, linguaggio di programmazione nel quale una piccola tartaruga presente sullo schermo riceve ordini di movimento. La tartaruga può lasciare una scia nel muoversi e così disegnare agli ordini dell’aspirante programmatore.
L’estensione turtle di Python permette di scrivere programmi basati sulla geometria e sul piano cartesiano, che disegnano grazie a robot virtuali (o tartarughe digitali) istruiti a muoversi lasciando una traccia del percorso compiuto.
Quanto è facile iniziare a dirigere una tartaruga via Python? Maurizio Boscaini lo spiega così.
Nell’interprete di IDLE, l’ambiente più classico per partire con la programmazione Python, scrivi il seguente codice:
>>> import turtle
>>> ninja = turtle.Turtle() # Crea una "Turtle" di nome "ninja"
Dopo aver eseguito la seconda riga, appare una nuova finestra intitolata Python Turtle Graphics. Al centro di uno sfondo bianco, chiamato canvas, o tela, che rappresenta l’area di disegno, appare una tartaruga rappresentata dall’immagine di una punta di una freccia.
Affianca le due finestre come mostrato nella figura qui sotto; in questo modo puoi scrivere istruzioni nella finestra dell’interprete e contemporaneamente vedere il loro effetto nell’altra finestra.
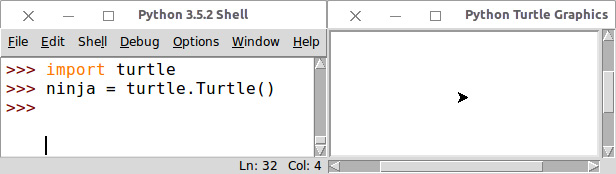
La finestra dell’interprete Python affiancata alla finestra grafica di Turtle.
La seconda istruzione crea un oggetto di tipo Turtle, richiamando il suo costruttore (una specie di stampino) contenuto in turtle (attenzione: il nome del costruttore inizia con la maiuscola mentre quello del modulo è tutto minuscolo), e gli dà un riferimento, o un nome con cui chiamarlo, costituito dalla variabile ninja (un piccolo omaggio alla serie a fumetti e televisiva Tartarughe ninja, nata negli Stati Uniti nel 1984).
Ora fai muovere ninja con le seguenti istruzioni:
ninja.forward(100) # Procedi in avanti di 100 passi (o pixel)
ninja.left(90) # Ruota a sinistra, cioè in senso antiorario, di 90 gradi
ninja.forward(100) # Procedi in avanti di 100 passi (o pixel)
Quando si muove, ninja lascia una scia del percorso che compie (in effetti potevano chiamarla lumaca invece che tartaruga…). Osserva nella prossima figura il risultato dell’esecuzione dei singoli passaggi: la tartaruga può essere vista anche come una penna che, se è appoggiata al piano, vi scrive sopra.
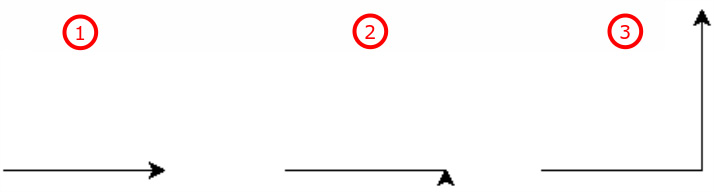
La tartaruga, che andava a destra, va avanti, ruota di 90° e poi ancora avanti.
Con Python si programma senza confini
Python, abbiamo detto, è universale, espressivo, completo e gratuito. Viene adottato da insegnanti, matematici, data scientist, ingegneri, ricercatori, studenti universitari, programmatori di videogiochi, hobbisti, giornalisti tecnici… chiunque. Vediamo qualche possibilità concreta.
Costruire un chatbot in meno di un’ora con Python
Serena Sensini ha costruito a scopo dimostrativo un chatbot essenziale in meno di sessanta minuti di lavoro.
(Un chatbot è software in grado di chiacchierare con un umano, entro limiti dettati dalla sofisticazione e dalla genialità del programma). Vediamo come si comincia.
Per prima cosa creiamo un file, chiamato train.py, in cui importare le librerie da utilizzare:
import nltk
nltk.download('punkt')
nltk.download('wordnet')
from nltk.stem import WordNetLemmatizer
import json
import pickle
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import SGD
Nel dettaglio:
- NLTK è una libreria perfetta per l’analisi linguistica e per elaborare i dati di input dell’utente;
- pickle è utile per serializzare e deserializzare oggetti in Python;
- Keras ci aiuterà a costruire la rete neurale.
Prima di cominciare, importiamo nel nostro progetto i seguenti file (che troverai anche su questo repository):
- *.pkl: oggetti che aiuteranno a modellare il chatbot;
- Intents.json: una serie di pattern che utilizzeremo per recuperare la risposta più adeguata dell’utente.
L’interno del chatbot che ci accingiamo a realizzare.
Dopo aver inizializzato una serie di variabili che ci aiuteranno nel lavoro, usiamo il modulo json per caricare il file e salvarlo come intents della variabile:
words = []
classes = []
documents = []
ignore_words = ['?', '!']
data_file = open('intents.json').read()
intents = json.loads(data_file)
Per il resto delle operazioni da compiere, rimandiamo all’articolo completo.
Creare una rete neurale con Python
Si può definire una rete neurale come una struttura che imita il funzionamento del cervello umano per elaborare dati. Oggi le reti neurali sono molto usate nelle applicazioni di intelligenza artificiale, per esempio per riconoscere immagini, forme, testo, numeri, volti. Gli assistenti vocali come Siri o Alexa si basano su reti neurali.
Le reti neurali complesse hanno bisogno di grandi capacità di calcolo, ma quelle semplici si costruiscono con relativa facilità anche sul computer di casa e sono uguali come struttura base. Imparare a creare una rete neurale può costituire un primo passo verso una carriera di data scientist. E si comincia in questo modo.
Che cos’è una rete neurale nella pratica
Una rete neurale può essere vista come una funzione matematica che produce un output desiderato a partire da un dato input. I componenti principali possono essere riassunti in:
- un layer di input;
- un numero x di layer nascosti;
- un layer di uscita.
A questi tre vanno certamente aggiunti determinati pesi per ogni collegamento tra un layer e l’altro, nonché una funzione di attivazione per ciascun layer.
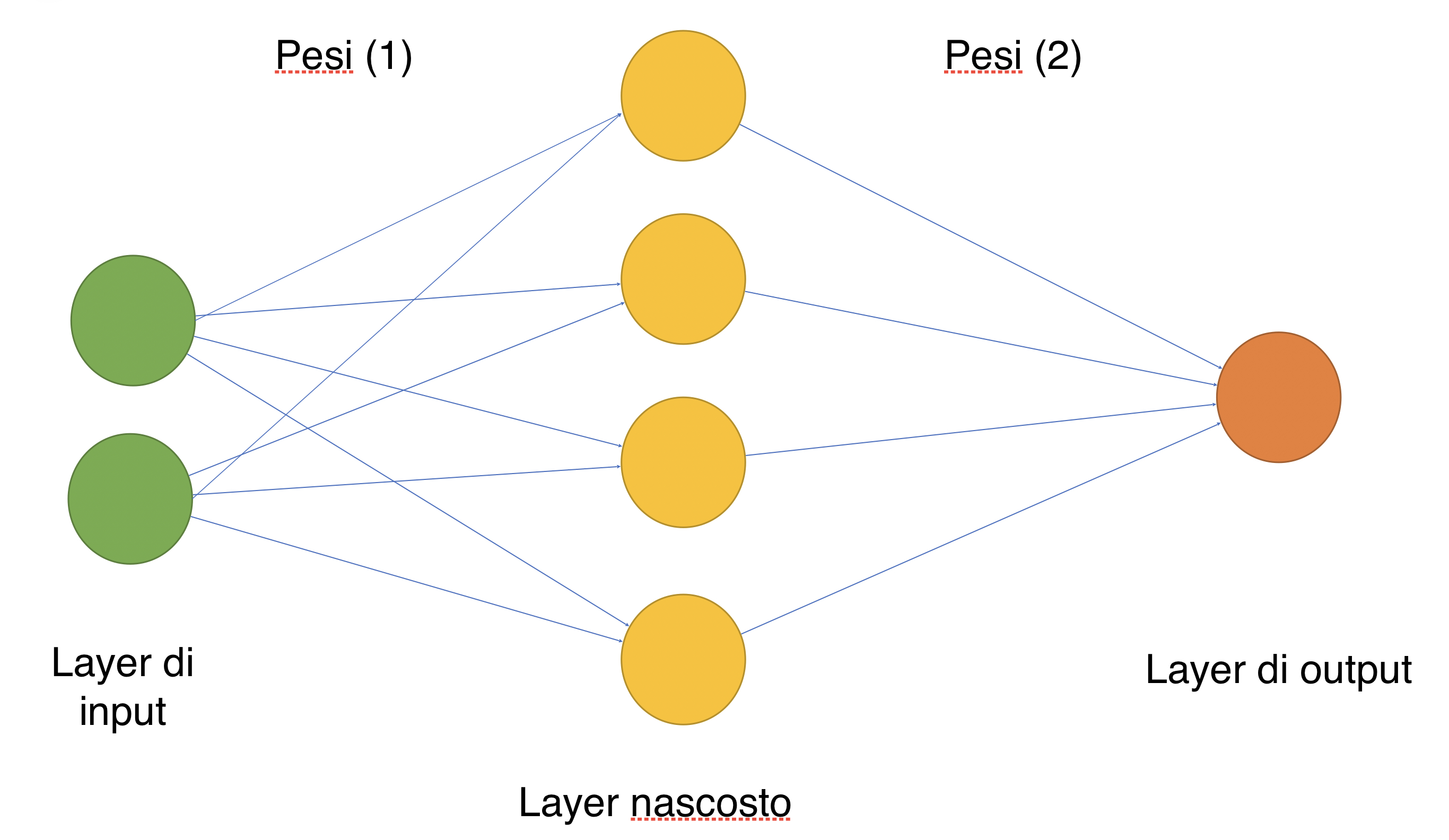
Un esempio molto semplice di rete neurale a due strati.
Qui sopra appare un esempio di rete neurale a due strati (lo strato di input non viene considerato nel conteggio); a partire da uno strato di input, tramite diversi collegamenti con lo strato nascosto che hanno un set di pesi, viene prodotto un risultato che verrà restituito dal layer di output.
L’articolo originale di Serena Sensini contiene tutto il codice e le spiegazioni per completare la nostra prima rete neurale.
Organizzare un flusso di dati incessante con Python
Molti sistemi generano una serie continua di file di dati. Possono essere file di log prodotti da un server di commercio elettronico o da un normale processo; feed di informazioni sui prodotti inviati da un server; feed automatizzati di elementi per la pubblicità online; dati storici su scambi commerciali eccetera. Spesso si tratta di normali file di testo, non compressi, contenenti dati grezzi ma con un valore potenziale, che quindi non è possibile semplicemente eliminare a fine giornata. I file si accumulano giorno per giorno fino al punto che gestirli manualmente diventa impossibile, per non parlare dello spazio che occupano.
Naomi Ceder mostra come automatizzare con Python la lavorazione di un flusso di dati continuo in modo da avere tutto sotto controllo e tenere a zero le attività manuali; pensa a tutto il software.
Il suo articolo prende in considerazione creazione di cartelle, rinomina di file e di estensioni dei file, ordinamento di file, archiviazione di informazioni vecchie, compressione e potatura degli archivi eccetera. Fa quasi impressione quanto tempo ci si possa liberare con poche righe di codice non complesso che lavorano al posto nostro!
Fare web scraping con Python
Le informazioni presentate sul web, come un elenco di libri o le previsioni del tempo, non sono organizzate per consentire facilmente di scaricarle localmente in modo ordinato. Per questo si è sviluppata l’arte e la scienza di fare scraping, cioè letteralmente grattare dai siti l’informazione in essi contenuta, per raccoglierla e ordinarla secondo i nostri scopi, certo sempre nel rispetto del copyright:
Si tratta di dati che chiunque può leggere su Internet, ma sono polverizzati su decine o migliaia di pagine distinte e quel che servirebbe è una magia che le legga tutte, e di tutte raccolga il valore in un database o un foglio elettronico. In modo da comparare e ordinare e fare medie e serie storiche e chi più ne ha più ne metta.
Grazie alla sua flessibilità e immediatezza, Python è un linguaggio ideale per fare scraping, come mostra Serena Sensini in un suo articolo che si prefigge come esempio di raccogliere informazioni sui film più belli dell’anno.
Esistono tantissime librerie in Python che permettono questo tipo di attività: per esempio, per estrarre dal sito www.filmtv.it i film usciti nel 2019, con titolo, genere, durata e votazione, si può usare Beautiful Soup. Questo pacchetto contiene centinaia di funzioni utili per l’analisi di documenti in formato HTML e XML, come appunto le pagine web, sfruttando la struttura ad albero dei documenti per dedurre informazioni.
Analizziamo velocemente, usando l’ispezione di Chrome, la pagina web per individuare le informazioni che ci interessano: digitiamo allora nel campo di ricerca del browser https://www.filmtv.it/film/migliori/anno-2019/ e premiamo il tasto F12: dovremmo vedere una cosa simile a quella di seguito.
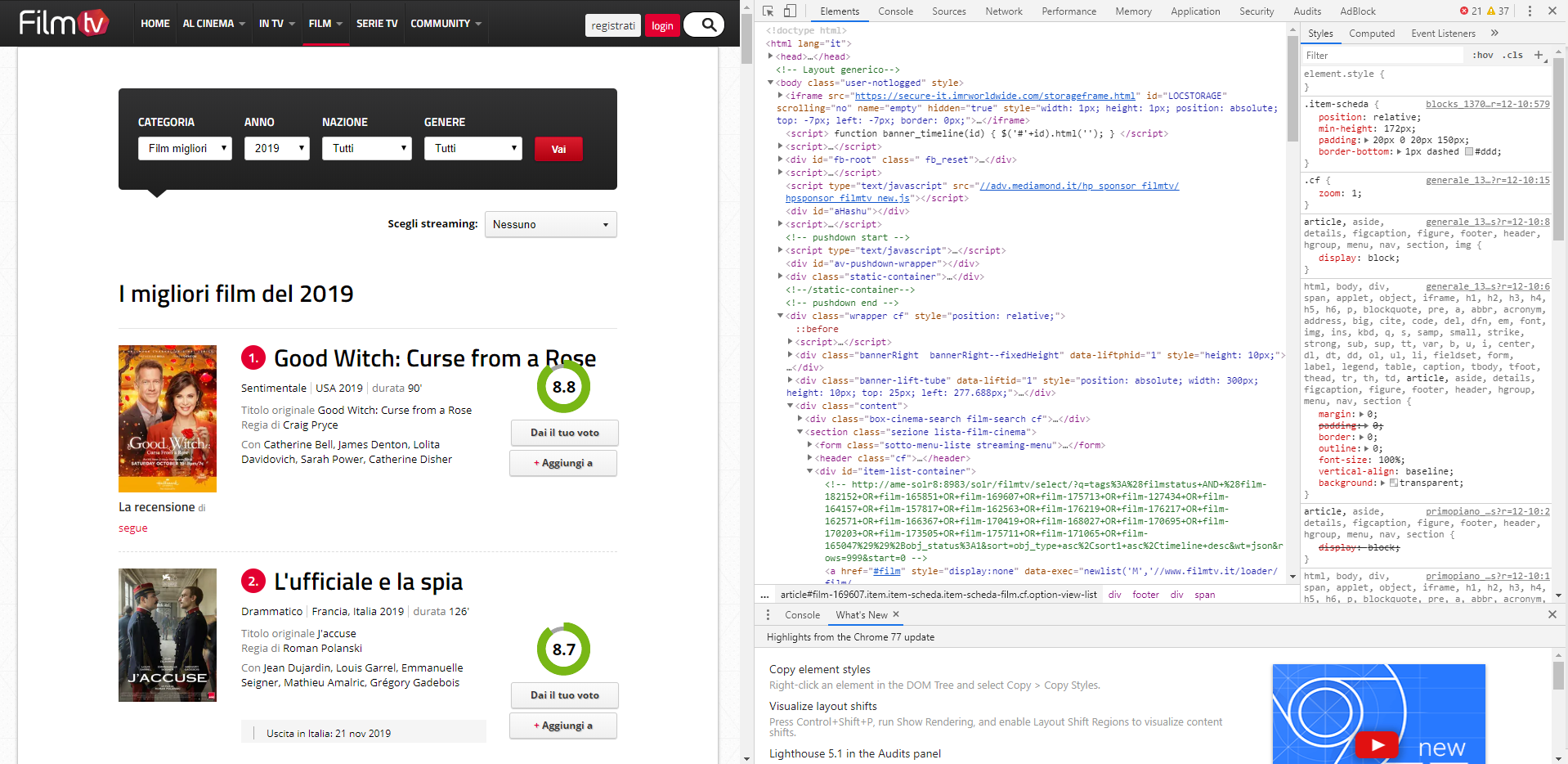
Analisi delle informazioni dentro una pagina web.
Lo studio della struttura delle schede dei film mostra come essa, a un certo punto, diventi ripetitiva: un tag article delimita la sezione del film in questione e al suo interno compare una serie di div che contengono i dati che vogliamo, perlopiù all’interno di una tabella o delle intestazioni. Il modello che dobbiamo sfruttare è il seguente:
<article class="item item-scheda item-scheda-film cf option-view-list" id="film-182152" data-position="1"> <div class="item-scheda-wrap"> <header> <h2 class="title-item-scheda"><span class="num">1.</span> <a href="//www.filmtv.it/film/182152/good-witch-curse-from-a-rose/" title="Good Witch: Curse from a Rose">Good Witch: Curse from a Rose</a></h2> </header> <div class="info-wrap"> <ul class="info cf"> <li>Sentimentale</li> <li>USA <time>2019</time> </li> <li><span>durata</span> 90'</li> </ul> <p class="titolo-originale"><span>Titolo originale</span> Good Witch: Curse from a Rose</p> <p class="regia"><span>Regia di</span> Craig Pryce</p> <p class="cast"><span>Con</span> Catherine Bell, James Denton, Lolita Davidovich, Sarah Power, Catherine Disher</p> </div> […] <footer> <div class="ring ring65p voto9" data-updcls="voto-ftv-film-182152"> <span data-updcnt="voto-ftv-film-182152">8.8</span> […] </article>
Creiamo un oggetto di tipo BeautifulSoup che ci permetterà di navigare all’interno del documento HTML:
# creazione di un oggetto "soup" soup = BeautifulSoup(data) print(soup)
Per recuperare il titolo, possiamo utilizzare la funzione find() che accetta come input diversi parametri, tra cui il nome del tag di interesse ed eventuali attributi dello stesso, come classe, ID e così via. In questo caso dobbiamo sfruttare la classe titolo-originale, per poter prendere il contenuto del tag; all’interno del paragrafo c’è però un tag span che non ci interessa. Con il metodo decompose() lo eliminiamo e con l’attributo text recuperiamo invece il testo del paragrafo, ovvero il titolo del film:
paragrafo = soup.find('p', attrs = {'class': 'titolo-originale'})
print(paragrafo)
paragrafo.find('span').decompose()
titolo = paragrafo.text
print(titolo)
Il procedimento per la regia e il cast è analogo:
# REGIA
paragrafo = soup.find('p', attrs = {'class': 'regia'})
print(paragrafo)
paragrafo.find('span').decompose()
regia = paragrafo.text
print(regia)
# CAST
paragrafo = soup.find('p', attrs = {'class': 'cast'})
print(paragrafo)
paragrafo.find('span').decompose()
cast = paragrafo.text
print(cast)
Per quanto riguarda il genere, la produzione e la durata, questi sono contenuti all’interno di un ul, ovvero una lista non ordinata di elementi. Dal momento che l’ordine di comparizione dei tre è sempre lo stesso, possiamo pensare semplicemente di iterare all’interno della lista di elementi li e di salvarne il contenuto in un array, che poi scompatteremo nelle diverse variabili:
# GENERE, PRODUZIONE, DURATA
elements = soup.find('ul')
print(elements)
arr = []
genere = ''
prod = ''
durata = ''
for li in elements.findAll('li'):
arr.append(li.text)
print(arr)
genere = arr[0]
prod = arr[1].rstrip()
durata = arr[2]
print(genere)
print(prod)
print(durata)
Non è il metodo migliore, ma è comunque quello più veloce! 😊
L’articolo originale contiene il resto delle informazioni necessarie per ottenere lo scopo.
Analizzare il linguaggio con Python e librerie open source
Le prime applicazioni di analisi del linguaggio risalgono agli anni ’50 grazie ad Alan Turing ma solo negli anni ’80 si iniziano a intravedere le prime applicazioni che ne fanno uso, come il lavoro di IBM sulla traduzione a macchina che ha semplificato la gestione multilingua dei testi legislativi per l’Unione Europea.
Python è sicuramente uno dei linguaggi di programmazione che più si presta all’analisi dei dati, grazie alla moltitudine di librerie open source per l’apprendimento automatico e il deep learning. Qualunque esperto del settore può confermare che le librerie maggiormente utilizzate in questo settore sono NLTK, OpenCV, spaCy e NetworkX, tutte operative con Python.
Per analizzare il linguaggio, Serena Sensini consiglia in un proprio articolo un computer con almeno 8 gigabyte di RAM e un processore che abbia una frequenza superiore ai 2,5 gigahertz. Per quanto riguarda gli ambienti di sviluppo, come spiega anche nell’ultimo capitolo di Analisi del linguaggio con Python, sono frutto di scelte soggettive: un po’ come uno scrittore che prediliga una penna stilografica, piuttosto di una Bic. Tra le alternative a disposizione, per uso professionale e non, esiste per esempio la suite Jetbrains, che fornisce una serie di ambienti per l’utilizzo di diversi linguaggi di programmazione; il codice presente nel libro è stato scritto con PyCharm.
Il lavoro da fare in questo campo è ancora moltissimo e c’è spazio per costruirsi una carriera promettente: a testimoniarlo è il video seguente, che mostra gli assistenti vocali Siri, Alexa e Google Home nel tentativo di comprendere correttamente richieste provenienti da bambini. Il risultato è esilarante!
Python per creare un’interfaccia di programmazione applicativa per ebook
Gli ambiti di applicazione di Python non devono necessariamente restringersi al già noto e includono anche ciò che è sperimentale e innovativo. Un esempio (per giunta italiano) è py-clave, interfaccia di programmazione applicativa (API) per ebook creata da Gabriele Alese e resa disponibile come open source, migliorabile da chiunque voglia cogliere l’opportunità.
Ivan Rachieli ha intervistato Alese sul tema, che è specialistico, riservato agli editori e a chi lavora nell’industria del libro elettronico. Proprio per questo è interessante vedere le specifiche tecniche dichiarate da Alese:
Tecnicamente, si tratta di un applicativo web scritto in Python e fondato sul framework Tornado. Mi sono imposto di non utilizzare librerie estranee alla standard library di Python; le conoscenze richieste sono modeste e rientrano nel bagaglio di qualsiasi sviluppatore.
Si può valorizzare la propria creatività, un’invenzione, una innovazione, anche con Python modello base.
Python alla frontiera della data science e del machine learning
La versatilità e la facilità di approccio di Python lo hanno reso da subito il linguaggio beniamino di quanti hanno iniziato a occuparsi delle nuove branche dell’intelligenza artificiale; il settore era praticamente vergine e Python si è imposto alla svelta tra i linguaggi più utilizzati. Il resto lo ha fatto la comunità, con la messa a punto di librerie ed estensioni del linguaggio che lo mettono in condizione di affrontare al meglio qualsiasi problema, in tempi brevi anche per chi abbia più esperienza di laboratorio, o statistica, che di programmazione.
Python: linguaggio ideale per applicarsi nel machine learning
Il machine learning è diventato negli ultimi anni una delle applicazioni più promettenti nell’ambito dell’intelligenza artificiale e Python ha acquisito una certa preminenza nel campo. Python è facile da avvicinare, completo, con il supporto di una forte comunità.
Per fare machine learning con Python non serve una laurea in Scienze dell’informazione e per partire è sufficiente seguire i percorsi delineati in un buon libro, come per esempio Machine Learning con Python di Sebastian Raschka.
Per come funziona il machine learning, un progetto piccolo funziona perlopiù come uno grande e si può imparare a partire da modelli piccoli e maneggevoli, magari da una passione personale, come scrive Raschka stesso:
Sono un grande appassionato di calcio e ho applicato il machine learning alla costruzione di modelli per predire gli esiti dell’equivalente inglese del Fantacalcio. È stato un progetto divertente che mi ha permesso di imparare molto. I miei modelli non erano perfetti ma, nella media, certamente più precisi delle mie previsioni improvvisate.
In Machine Learning con Python, per parlare di passioni, Raschka mostra come estrarre dati da Internet Movie Database (IMDB), l’archivio più completo al mondo esistente sul mondo del cinema. È un libro con una storia particolare e particolare è anche la sua copertina.
Perché vari esperti di data science preferiscono Python ad altri linguaggi, anche specializzati
La data science consiste nell’investigare l’informazione nascosta in volumi di dati spesso di dimensioni ingenti, di solito con una idea precisa del risultato che si vuole ottenere e una certa vaghezza sulle difficoltà che potrebbero presentarsi durante il cammino.
Python vince in molte situazioni perché consente facilmente all’esperto di improvvisare una soluzione ingegnosa a un problema improvviso e inaspettato. In un certo senso Python e data science sono fatti per stare insieme.
Dmitry Zinoviev, autore di Data Science con Python e svariati articoli apparsi su Apogeonline, è un sostenitore autorevole di Python su alternative più tradizionali come il linguaggio R e anche uno che in argomento non fa sconti a nessuno, con affermazioni come questa:
La prima [ragione per scegliere Python su R] è che R è un brutto linguaggio, progettato e implementato da statistici, per i propri scopi, più che da informatici. La sua sintassi e la sua semantica sono antiintuitive. È lento e inefficiente. (La prossima volta parliamo di un dataset Yelp che R ha letto in venti minuti, e Python in uno). Se sei cresciuto come programmatore di computer, imparare R può avvicinarsi alla tortura. Se R è il tuo primo linguaggio di programmazione, sarà una tortura impararne altri dopo. La seconda ragione è che R comunque brilla in qualche modo nell’elaborazione standard dei dati: individuazione di dati anomali, regressioni, classificazioni, machine learning… in altre parole, quando i dati sono già ordinati in comode tabelle. Convertire in tabelle dati provenienti da rappresentazioni misteriose e intricate, non tabellari, invece, è un compito dove i linguaggi generici [come Python] non hanno rivali.
Questo invece è il parere di Sinan Ozdemir, autore di Data Science:
Un linguaggio generico come Python consente di portare in qualunque altro ambito la conoscenza acquisita nella data science. Python permette di creare soluzioni valide per portare le proprie applicazioni ad altre persone in modo che esse le possano usare facilmente.
Un’altra ragione dell’emergere di Python è che oggi il corso di studi di un data scientist può essere imprevedibile e Python è molto facile da maneggiare anche per chi non era abituato a farlo. Zinoviev, guarda caso, è per formazione un fisico; in una intervista ci ha parlato del corso di studi più comune per gli odierni data scientist. In effetti sono due, uno che parte dallo studio della statistica e un altro fondamentalmente corrispondente a un sottoinsieme di Science dell’informazione. Dal primo si va verso R, dal secondo in direzione di Python; e il secondo è più trasversale e accessibile.
Data science con Python: cominciare dalle cose semplici
Sembra non esserci un limite alla semplicità delle tematiche che è possibile affrontare con Python e una mentalità da data scientist. Il che significa che cominciare è facile; non c’è bisogno che i dati siano infiniti né padroneggiare strumenti eccessivamente sofisticati. D’altronde, come dice Dmitry Zinoviev,
La vita è una esperienza incessante di data science. Qualsiasi previsione, da “arrivo tra cinque minuti” a “sta per piovere”, è un esempio di machine learning, dove la machine è il nostro cervello. Sono attività basate su dati di addestramento (la nostra esperienza) e una vasta raccolta di modelli di dati cablati sempre dentro la nostra testa. Lo stesso vale per la classificazione. La data science in senso formale è una misera simulazione delle nostre procedure quotidiane di apprendimento e decisione.
Analisi con Python e pandas della casualità delle classifiche in un torneo di calcio
Nell’articolo Calcio, Python e data science Dmitry Zinoviev mostra come l’interesse per la manipolazione dei dati – affidandosi a Python – possa applicarsi anche a insiemi di dati anche molto piccoli, nella fattispecie i gironi a quattro squadre del classico torneo di calcio tra squadre nazionali come gli Europei o i Mondiali.
Il tifoso e contemporaneamente appassionato di data science potrebbe chiedersi quanto le classifiche dei gironi si avvicinino alla casualità ossia siano imprevedibili. La libreria pandas entra… in gioco e trasforma Python in uno strumento perfetto per fornire un esempio di analisi facilmente replicabile da chiunque, vista l’esiguità dei dati di partenza.
Analisi con Python dei commenti su un forum di appassionati della serie televisiva The Good Wife
I dati per fare data science con Python possono essere pochi; ma se vogliamo impratichirci lavorando su volumi di dati più importanti, dove li troviamo? Dmitry Zinoviev ha raccolto i commenti degli appassionati di una serie televisiva pubblicati su un forum dedicato.
Con questo pretesto ha potuto lavorare sulle tecniche fondamentali di analisi di dominî culturali e su librerie di Python specifiche per questo tipo di lavoro sui dati come Pandas, NetworkX o community, fino ad arrivare a risultati concreti dal campione di dati raccolto, pulito e ordinato.
La forza di Python sta nella comunità. Anche in Italia
Linguaggio semplice ma senza limiti; e allora come si fa, quando esploriamo i nostri limiti per crescere e arriviamo al punto di avere bisogno di una dritta? Come detto più sopra, Python ha una comunità enorme che naturalmente si può contattare in mille situazioni online. Tuttavia sappiamo benissimo come a volte il faccia a faccia possa essere molte volte più produttivo di una esperienza mediata dalla rete.
Django Girls: ragazze che usano Python con orgoglio
Uno dei modi di incontrare persone che insegnano – e imparano – Python è seguire l’agenda delle Django Girls: un gruppo internazionale che prende il nome da un framework molto diffuso di Python e organizza in tutto il Paese incontri per diffondere la passione della programmazione tra le ragazze.
Abbiamo intervistato Emanuela Dal Mas, una tra le Django Girls veterane, che ci ha rivelato come i loro workshop siano aperti a donne di tutte le età e tutti i livelli di competenza informatica, da mille a zero. E anche di come la loro missione al femminile sia più che aperta alla collaborazione dei maschi:
Per le partecipanti [ai workshop] la presenza maschile è rassicurante, fa comprendere loro che non tutto il settore è permeato dal maschilismo. In buona sostanza fa sparire lo spauracchio dello sviluppatore brutto e cattivo. Agli uomini, specie gli sviluppatori che contribuiscono come coach, possiamo dire: siate onesti e rispettosi, ma senza vezzi o esagerazioni.
Firenze, l’ombelico di Python in Italia: benvenuti a PyCon
In ogni caso l’apice del fermento della comunità Python in Italia si raggiunge durante PyCon, la conferenza annuale dedicata al mondo Python che si tiene tradizionalmente a Firenze e in programma per il 2020 (undicesima edizione) dal 5 all’8 novembre (per inciso, teniamo aggiornato un calendario degli eventi italiani per il mondo della programmazione che magarti può tornare utile).
Ci siamo collegati con PyCon per raccontarlo o anticiparlo più volte: in occasione di PyCon Nove per esempio, e tornando indietro nel passato a PyCon Otto, PyCon Sette e anche quella volta, nel 2009, che a PyCon ha partecipato Guido van Rossum, creatore del linguaggio e fino a poco tempo fa benevolent dictator dello sviluppo di Python.
Insomma, è possibile scoprire Python e anche tanti nuovi amici e amiche nello stesso momento. Facile, se si parla un linguaggio così condiviso e fruibile.
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Corsi che potrebbero interessarti

Big Data Analytics - Iniziare Bene

Data governance: diritti, licenze e privacy

Agile, sviluppo e management: iniziare bene
Libri che potrebbero interessarti

Python
Guida alla sintassi, alle funzionalità avanzate e all'analisi dei dati
Analisi del linguaggio con Python
Imparare a processare testo e audio con le librerie open source