

Alcune persone non amano veramente l’interazione umana. Ogni volta che sono costretti a socializzare o andare ad eventi che coinvolgono molte persone, si sentono fuori posto e imbarazzati. Personalmente, ho attraversato quella fase e ne sono uscita sana e salva, e ora non disprezzo più la socialità. Molte persone sono esattamente il mio opposto e probabilmente non cambieranno mai visione.
Mi viene in mente un film uscito qualche anno fa, Lei. Il protagonista è Joaquin Phoenix, tornato alla ribalta lo scorso anno con l’uscita di Joker, che gli ha fruttato l’Oscar. Il protagonista è un impiegato che soffre di solitudine e depressione, con un divorzio imminente che lo sta logorando. Finisce per innamorarsi di un’intelligenza artificiale alla quale lavora e con cui inizia ad avere un rapporto non esattamente platonico.
Com’è possibile che una intelligenza artificiale sia in grado di avere un rapporto con un essere umano? Può realmente provare emozioni? Possibile che il protagonista abbia preferito un sistema ad un rapporto umano? A volte, temo che le persone rinuncino a trovare l’amore (o persino l’interazione sociale) con altri esseri umani e che siano in grado di cercarlo solo nel regno digitale.
In compagnia di un chatbot
Senza scendere troppo nel filosofico ed essendo prossimi alla festa di San Valentino (e dei single), creeremo un chatbot che, tramite rete neurale, ci permetta di avere delle interazioni. Il nostro assistente sarà in grado di rispondere a complimenti, ascoltare e tenere compagnia.
L’esempio che vedremo ha una serie di debolezze: per rispettare il vincolo di un’ora di lavoro, non potremo lavorare molto sulla pre-elaborazione dei dati, né sull’addestramento della rete neurale: evidenzieremo però i punti in cui migliorare il modello, così da poter riprendere il lavoro fatto in un secondo momento e valorizzarne le potenzialità.
Per prima cosa creiamo un file, chiamato train.py, in cui importare le librerie da utilizzare:
import nltk
nltk.download('punkt')
nltk.download('wordnet')
from nltk.stem import WordNetLemmatizer
import json
import pickle
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import SGD
Nel dettaglio:
- NLTK è una libreria perfetta per l’analisi linguistica e per elaborare i dati di input dell’utente;
- pickle è utile per serializzare e deserializzare oggetti in Python;
- Keras ci aiuterà a costruire la rete neurale.
Prima di cominciare, importiamo nel nostro progetto i seguenti file (che troverai anche su questo repository):
- *.pkl: oggetti che aiuteranno a modellare il chatbot;
- Intents.json: una serie di pattern che utilizzeremo per recuperare la risposta più adeguata dell’utente.
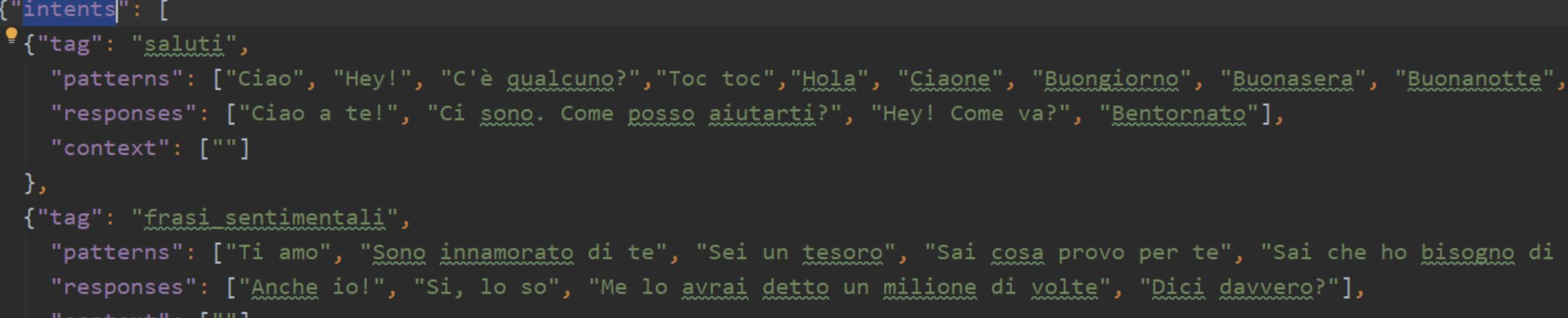
L’interno del chatbot che ci accingiamo a realizzare.
Dopo aver inizializzato una serie di variabili che ci aiuteranno nel lavoro, usiamo il modulo json per caricare il file e salvarlo come intents della variabile:
words = []
classes = []
documents = []
ignore_words = ['?', '!']
data_file = open('intents.json').read()
intents = json.loads(data_file)
Se osservi attentamente il file json, puoi vedere che ci sono oggetti secondari all’interno degli oggetti principali. Ad esempio, patterns è un attributo all’interno di intents; useremo un ciclo innestato per estrarre tutte le parole all’interno di patterns e aggiungerle al nostro elenco di parole. Aggiungiamo quindi al nostro elenco di documenti (variabile documents) ogni coppia di pattern all’interno del loro tag corrispondente. Aggiungiamo anche i tag nel nostro elenco di classi e utilizziamo una semplice istruzione condizionale per evitare ripetizioni.
for intent in intents['intents']: for pattern in intent['patterns']: # tokenizzo ogni parola w = nltk.word_tokenize(pattern) words.extend(w) # aggiungo all'array documents documents.append((w, intent['tag'])) # aggiungo classi al nostro elenco if intent['tag'] not in classes: classes.append(intent['tag'])
Inizializziamo anche un lemmatizzatore, ovvero un oggetto che ci permetterà di ridurre in lemmi gli input; ogni parola contenuta in words sarà ridotta in minuscole e verranno rimossi eventuali simboli di interpunzione.
lemmatizer = WordNetLemmatizer()
words = [lemmatizer.lemmatize(w.lower()) for w in words if w not in ignore_words]
Comincia l’addestramento
Ora è tempo di preparare i dati per l’addestramento della rete: inizializziamo i nostri dati di training con una variabile chiamata – ovviamente – training. Stiamo creando un gigantesco elenco nidificato che contiene le cosiddette bag of words per ciascuno dei nostri documenti. Abbiamo una matrice chiamata output_row che funge semplicemente da chiave per l’elenco: inseriremo infatti un 1 per ogni parola inserita dall’utente che corrisponde a quelle presenti nei nostri pattern.
Dopo aver quindi elaborato i dati in maniera del tutto analoga alla precedente, ovvero riducendo a lemmi le parole e rimuovendo caratteri maiuscoli, predisponiamo la matrice aggiungendo 1 alla variabile bag se la parola è presente tra i patterns, o altrimenti zero:
training = []
output_empty = [0] * len(classes) for doc in documents: # bag of words bag = [] # lista di token pattern_words = doc[0] # lemmatizzazione dei token pattern_words = [lemmatizer.lemmatize(word.lower()) for word in pattern_words] # se la parola corrisponde inserisco 1, altrimenti 0 for w in words: bag.append(1) if w in pattern_words else bag.append(0) output_row = list(output_empty) output_row[classes.index(doc[1])] = 1 training.append([bag, output_row])
Ora che abbiamo i nostri dati pronti, useremo un modello di deep learning del pacchetto Keras chiamato Sequential. Si tratta di una rete neurale abbastanza semplice che prende il nome dalla gestione degli output dei vari neuroni: ognuno di essi produce un output e lo passa al successivo come input, in modo lineare.
Questa particolare rete avrà 3 strati, di cui il primo con 128 neuroni, il secondo con 64 neuroni e il terzo con il numero di intents pari al numero di neuroni. Ricorda, il punto di questa rete è essere in grado di prevedere quale intent scegliere tra quelli dati.
Il modello verrà addestrato con la discesa stocastica del gradiente, un argomento molto complicato. Si tratta di una funzione che lavora nei modelli iterativi di molti algoritmi di deep learning. Dopo che il modello è stato addestrato, il tutto verrà elaborato e salvato come chatbot_model.h5:
# creazione del modello
model = Sequential()
model.add(Dense(128, input_shape=(len(train_x[0]),), activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(len(train_y[0]), activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
#fitting and saving the model
hist = model.fit(np.array(train_x), np.array(train_y), epochs=300, batch_size=5, verbose=1)
model.save('chatbot_model.h5', hist)
print("Modello creato!")
Mettiamo il chatbot in… funzione
Per poter utilizzare il nostro chatbot, creeremo 4 funzioni che ci aiuteranno ad utilizzare il modello e elaborare l’input dell’utente: una prima funzione che pulisce qualsiasi frase inserita (clean_up_sentence()), una seconda che creerà una bag of words con le parole dell’utente per prevedere la classe di risposte (bow()), una terza che calcolerà le possibili risposte, in cui utilizziamo una soglia di errore di 0,25 per evitare un eccesso di adattamento al modello addestrato e che produrrà un elenco di intents e probabilità (calcola_pred()) e infine un’altra che restituirà una delle possibili risposte al pattern (getRisposta()).
# pre-elaborazione input utente
def clean_up_sentence(sentence):
sentence_words = nltk.word_tokenize(sentence)
sentence_words = [lemmatizer.lemmatize(word.lower()) for word in sentence_words]
return sentence_words
# creazione bag of words
def bow(sentence, words, show_details=True):
sentence_words = clean_up_sentence(sentence)
bag = [0]*len(words)
for s in sentence_words:
for i,w in enumerate(words):
if w == s:
bag[i] = 1
if show_details:
print ("found in bag: %s" % w)
return(np.array(bag))
# calcolo delle possibili risposte
def calcola_pred(sentence, model):
p = bow(sentence, words,show_details=False)
res = model.predict(np.array([p]))[0]
ERROR_THRESHOLD = 0.25
results = [[i,r] for i,r in enumerate(res) if r>ERROR_THRESHOLD]
# sort by strength of probability
results.sort(key=lambda x: x[1], reverse=True)
return_list = []
for r in results:
return_list.append({"intent": classes[r[0]], "probability": str(r[1])})
return return_list
# restituzione della risposta def getRisposta(ints, intents_json): tag = ints[0]['intent'] list_of_intents = intents_json['intents'] for i in list_of_intents: if(i['tag']== tag): result = random.choice(i['responses']) break return result
L’ultima funzione che creeremo è quella principale, che richiama le altre e che fa sì che l’interazione tra utente e chatbot sia possibile: verrà chiamata ogniqualvolta l’utente scrive qualcosa; per chiudere la conversazione, basterà scrivere esci.
def conversa(msg):
ints = calcola_pred(msg, model)
res = getRisposta(ints, intents)
print(res)
return res
utente = ''
print('Benvenuto! Per uscire, scrivi "Esci"')
while utente.lower() != 'esci':
utente = str(input(""))
res = conversa(utente)
print('AI:' + res)
Il risultato è il seguente:
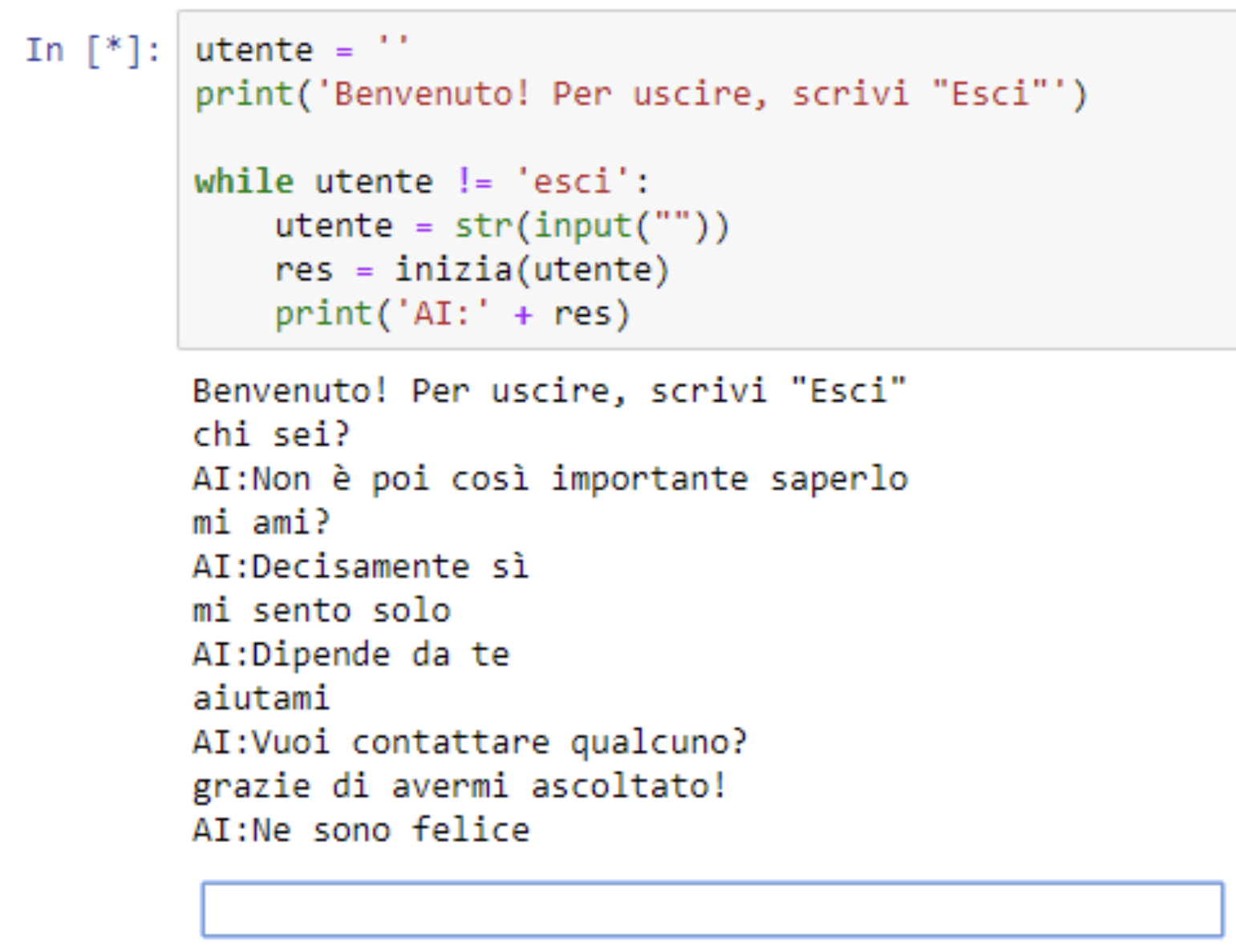
Il chatbot è perfetto per una breve conversazione prima di uscire a festeggiare San Valentino in compagnia, o, perché no, anche soli!
C’è sicuramente margine di miglioramento: molte delle operazioni svolte finora possono essere lavorate per dare risultati di ottima qualità. Qualche esempio:
- Provare altri modelli di reti neurali: Abbiamo usato la rete neurale Keras più semplice, quindi c’è MOLTO spazio per miglioramenti. Perché non provare una rete convoluzionale o una rete ricorrente?
- Utilizzare un dataset più ricco: Il nostro file json era estremamente piccolo in termini di varietà di possibili intents e risposte.
- Spazio ai framework: In Python esistono molti framework di deep learning, oltre a quelli utilizzati: ci sono TensorFlow, Apache Spark, PyTorch, sonnet e altro. Non c’è limite a quello che puoi realizzare!
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Corsi che potrebbero interessarti

Language design: progettare con le parole

Big Data Analytics - Iniziare Bene

Scrivere per lavoro
Libri che potrebbero interessarti

Analisi del linguaggio con Python
Imparare a processare testo e audio con le librerie open source
Python
Guida alla sintassi, alle funzionalità avanzate e all'analisi dei dati