
PROMOZIONE
Lavori con dati e software?
Vuoi essere sicuro di fare le scelte giuste?
Ci sono 4 corsi per te, scoprili e con il codice DATAX50 risparmi 50€ sull’iscrizione a: Big Data Executive, Big Data Analytics, Data governance, Strategie e modelli contrattuali per cedere e acquisire software.
Quando il nostro modello funziona bene solo per i risultati passati
Il matematico statunitense John Nash ha rivoluzionato l’economia proponendo la teoria dei giochi e meritando per questo il premio Nobel per l’economia nel 1994. La sua figura è stata resa popolare dal film A beautiful mind del 2001: impersonato da Russell Crowe, John Nash viene ritratto nel film a combattere la schizofrenia, malattia diagnosticatagli all’età di 31 anni e con la quale avrebbe convissuto per oltre un trentennio.
In una scena del film, Nash è intento a rintracciare presunti messaggi cifrati nascosti da spie russe (siamo in piena guerra fredda) tra gli articoli di riviste e giornali. Questa condizione, tipica dello stadio iniziale della schizofrenia, è chiamata dagli psichiatri apofènia e si riferisce alla visione immotivata di connessioni nelle quali il paziente immagina di rintracciare un significato profondo che, in realtà, non esiste.
In effetti quando si hanno a disposizione tantissimi dati e potenti macchine per analizzarli è possibile trovare pseudoevidenze che offrono un’apparente spiegazione per quasi qualunque fatto. Come in una sorta di schizofrenia analitica, la disponibilità di tanti (troppi) numeri può ingannarci e farci credere di aver individuato un pattern di validità generale quando, in realtà, abbiamo semplicemente trovato una connessione insignificante tra le innumerevoli disponibili.
Proviamo ad analizzare un esempio per chiarire questa situazione: partendo da una tabella che raccoglie una serie di dati su chi ha acquistato i biglietti della lotteria nazionale negli ultimi due anni, vogliamo costruire una macchina capace di predire i vincitori delle prossime edizioni, identificando le caratteristiche del vincitore modello.
Facciamo analizzare tutti i dati da un algoritmo di supervised learning il quale, imparando da milioni di numeri e avendo a disposizione due vincitori, cerca quella che secondo lui è la regola che contraddistingue il vincitore-tipo. Il modello ottenuto dall’algoritmo trova una serie lunghissima di attributi del vincitore: ha un nome di battesimo di 6 lettere, ha un numero di biglietto che include le cifre 2, 5 e 8, vive in una città in cui la temperatura media ad agosto è di 34 °C e così via.
In effetti l’algoritmo ha solo trovato una serie di caratteristiche che sono in comune fra i due vincitori e diverse da tutti gli altri. Questo modello non è di validità generale: è caratterizzato, invece, da un livello di complessità ingiustificata. Ci siamo solo fatti prendere la mano e siamo caduti in quella situazione, simile all’apofènia, per cui diamo importanza a connessioni esistenti ma insignificanti. Una conseguenza tipica di un modello del genere è che sembra funzionare molto bene sui risultati passati (i due vincitori precedenti) ma non funziona per nulla su quelli futuri: non ha capacità predittiva, che era, invece, il nostro obiettivo primario.

Ma come evitare questo problema? Occupiamoci di una materia più verosimile, la predizione dei prezzi degli immobili: creiamo diversi modelli alternativi nei quali curve di complessità superiore rispetto a quella di una linea retta (ovvero polinomi di grado superiore a 1) cercano di interpolare i nostri dati. Senza entrare nel dettaglio della formula matematica, andiamo a vedere che cosa succede se diamo in pasto dati a un algoritmo di gradient descent per trovare le migliori curve interpolanti i nostri prezzi al variare del parametro N, ovvero del grado del polinomio.
Queste curve per valori di N pari a 1, 3 e 5 sono riportate nella prossima figura. Il caso di N = 1 (la linea rossa in figura) equivale al risultato della regressione lineare semplice: nella sua semplicità questo modello descrive efficacemente l’evidenza che all’aumentare della distanza dal centro il prezzo diminuisce, ma non riesce a catturare bene il fatto che nei pressi del centro storico la pendenza sia maggiore che in periferia.
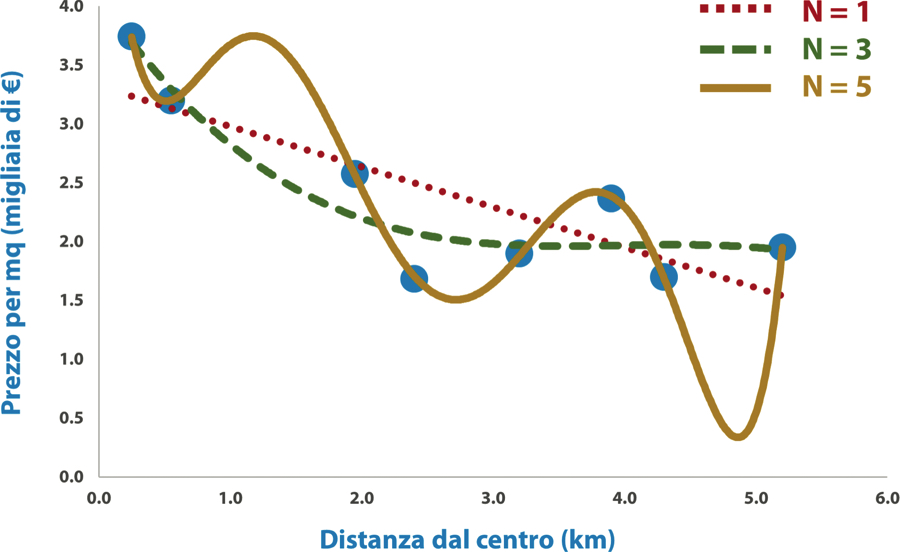
Regressione polinomiale al variare del grado del polinomio N. All’aumentare di N aumenta la complessità e il modello perde di validità generale.
Nel caso N = 5 (colore ambrato) abbiamo una situazione molto particolare: il gradient descent ha trovato quei parametri che, associati a un polinomio abbastanza complesso di quinto grado, riescono a passare vicinissimi a tutti e 8 i punti a nostra disposizione. Dopo l’emozione iniziale ci accorgiamo però come questo modello, pur aderendo perfettamente al passato, sia di fatto inutile. Per forzare il passaggio attraverso tutti i punti, la curva ha assunto una forma bizzarra fatta di dossi e valli costruiti ad hoc per gli 8 punti dati in input.
Di conseguenza, se dovesse rendersi disponibile un nuovo immobile da valutare potremmo prendere una bella cantonata: una casa a 1 chilometro dal centro costerebbe oltre 3.500 euro al metro quadrato, più di una in pieno centro, solo perché la curva del polinomio ha dovuto introdurre un dosso artificiale molto ripido per poter unire al meglio i punti sulla sinistra. Invece una casa a poco meno di 5 chilometri dal centro è quasi regalata solo perché questo complesso polinomio prevede un avvallamento improvviso che permette di legare i punti sulla destra. Insomma, questo polinomio è un disastro.
Nell’intorno da noi considerato (ovvero entro i 5 chilometri dal centro) siamo invece piacevolmente sorpresi da come la curva di terzo grado N = 3 (colore verde) esibisca un andamento molto incoraggiante. Infatti, questa curva si abbassa più velocemente sulla sinistra (in prossimità del centro) e meno ripidamente in periferia, adagiandosi molto bene alla realtà intravista dai punti a disposizione. All’arrivo di nuovi punti, ovvero di ulteriori immobili da valutare, non avremmo sorprese: questo risultato ci sembra a occhio quello migliore per la nostra predizione.
Sono due gli aspetti ricorrenti che mette in luce questo esempio e che conviene, quindi, puntualizzare.
- I modelli di machine learning dopo il loro apprendimento possono ricadere in due estremi a seconda del loro livello di complessità:
– se il modello è troppo semplice, ricadrà nell’inevitabile conseguenza di non capire appieno la realtà. Si dice che in questo caso la macchina ha imparato troppo poco e si parla di modello undertrained o underfitted;
– se il modello è troppo complesso, rischia di rimanere accecato dalla sua ambizione di sofisticatezza e di acquisire una visione distorta della realtà. La macchina penserà di aver capito tutto quando in realtà ha trovato solo un modo contorto di collegare i puntini, adattandosi eccessivamente ai dati a disposizione: in questo caso si parla di modello overtrained o overfitted. - È grazie al giusto compromesso tra semplicità e complessità che possiamo capire (e quindi descrivere o predire) la realtà. Infatti, in entrambi gli estremi visti sopra, la macchina non sarà in grado valutare accuratamente i nuovi dati o perché non ha capito per nulla la realtà (underfitted) o perché ne ha un’immagine distorta (overfitted).
Per utilizzare il machine learning in modo diligente dobbiamo dunque riuscire a identificare quel livello di complessità che permette alla macchina di imparare il giusto, implementando un modello di validità generale che funzioni non solo sui dati utilizzati per l’apprendimento ma anche sugli eventuali nuovi arrivi. Questo modello equilibrato si dice well-trained o well-fitted.
Prima di proseguire, ragioniamo su come il pericolo dell’overfitting o underfitting riguardi tutte le tecniche di machine learning. Quando c’è il rischio di interpretare erroneamente la variabilità casuale presente nei dati (una sorta di rumore stocastico) come una regola generale, c’è la possibilità di provocare overfitting. Anche, per esempio, nei problemi di classificazione si può commettere over o under fitting.
La figura seguente illustra come una macchina possa classificare elementi su un piano cartesiano (cerchi e croci in figura) tracciando una linea di separazione più o meno complessa (è un caso generico di macchina a vettori di supporto o SVM, Support Vector Machine). 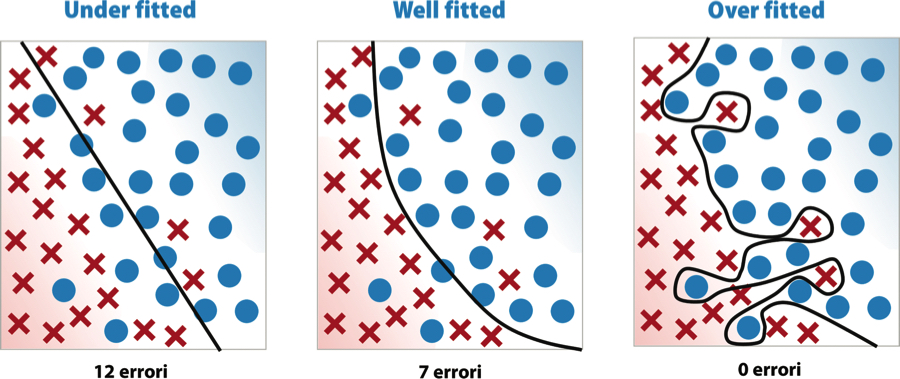
Modelli di complessità crescente per un problema di classificazione. Quale modello sarà verosimilmente più efficace per classificare nuovi dati?
Il primo modello è molto semplice (una linea retta) ma non sembra essere altrettanto efficace in quanto commette 12 errori di classificazione. Il terzo modello è estremamente complesso e si adatta eccessivamente ai punti che verosimilmente costituiscono l’eccezione (outlier) e non la regola. Il modello centrale sembra essere intuitivamente il più bilanciato dei tre.
| Underfitted | Well-fitted | Overfitted | |
|---|---|---|---|
| Complessità | Bassa | Media | Alta |
| Accuratezza su casi passati | Bassa | Media | Alta |
| Accuratezza su casi futuri | Bassa | Medio-alta | Bassa |
| Descrizione | Il modello è troppo naïf: non impara abbastanza e di conseguenza non riesce a spiegare bene nulla. | Il modello ha il giusto livello di complessità: impara a riconoscere quelle connessioni di validità generale che gli permettono di essere abbastanza accurato con casi futuri. | Il modello è troppo complesso: è costruito in modo tale da adattarsi perfettamente ai casi passati ma non generalizza sui futuri. |
Ora che abbiamo inquadrato il problema possiamo pensare a come risolverlo in modo sistematico, valutando efficacemente l’equilibrio tra complessità e semplicità per ottenere modelli bilanciati e di valore generale. Come si evince nella descrizione sintetica riportata nella tabella appena vista, il modello well-fitted si differenzia dagli altri nell’accuratezza mostrata su dati futuri, non utilizzati come esempi da cui imparare durante la fase di apprendimento.
Ma come facciamo a valutare preventivamente l’accuratezza usando dati che non sono ancora a nostra disposizione? Per fortuna esiste un trucco per risolvere questa situazione apparentemente difficile. Per prima cosa, selezioniamo a caso tra i dati disponibili un sottoinsieme di elementi che chiamiamo di test (test set) ed escludiamoli dalla fase di apprendimento. La macchina imparerà dunque da tutti gli altri elementi (training set) e costruirà il suo modello solo sulla base di quelli.
Dopo la fase di apprendimento, utilizzeremo gli elementi inizialmente tenuti fuori per valutare il modello: se le predizioni effettuate sul test set sono accurate, il modello ha imparato qualcosa di validità generale (well-fitted). Se, invece, le predizioni sul test set sono sbagliate, il modello si è solo adattato artificiosamente al training set, dimostrandosi inadeguato a fare previsioni su dati futuri (overfitted). Questo escamotage, ovvero la ripartizione preventiva fra training e test set, si chiama partizionamento o partitioning (nella figura qui sotto) e costituisce uno dei passi cardine di un buon processo di machine learning, ovvero la sua validazione (model validation).
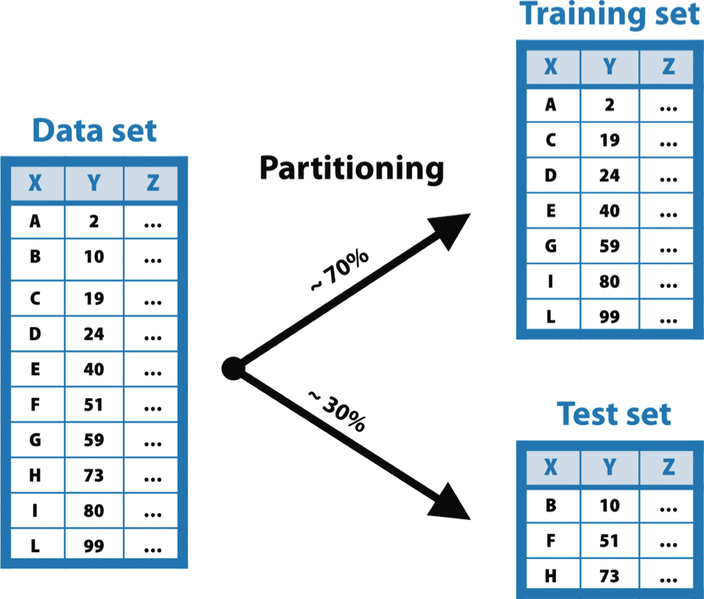
Il funzionamento del partitioning. Gli elementi della tabella in ingresso vengono suddivisi casualmente in due gruppi distinti: training e test set.
Se avessimo la possibilità di far variare la complessità del modello a piacere, potremmo individuare il giusto livello di complessità, ovvero quello per cui il modello è well-fitted.
Infatti, noteremmo che all’aumentare della complessità l’errore di predizione generato dal training set (quello su cui si apprende) e il test set (quello tenuto fuori dall’apprendimento) inizia a divergere da un certo punto in poi. Prendendo la prossima figura, per esempio, osserviamo l’andamento delle due curve: un modello underfitted (a sinistra nel grafico), non riuscendo a interpretare la complessità del fenomeno che genera i dati, produrrà errori considerevoli nel training set e, di conseguenza, anche nel test set. 
Errore di predizione ottenuto sul test e training set all’aumentare della complessità del modello. Nel training set possiamo minimizzare l’errore aumentando la complessità ma perdiamo presto di generalità.
Un modello overfitted, invece, produrrà errori molto bassi sul training set (adattandosi artificialmente alle sue specificità) e molto alti sul test set (in quanto non ha identificato quali connessioni possano essere riapplicate alla generalità dei casi). Il modello well-fitted sarà quello per cui l’errore sul test set si mantiene basso: possiamo considerare quindi l’accuratezza ottenuta sul test set come una valida prova per identificare i modelli well-fitted.
La buona notizia è che esistono quasi sempre dei modi per modulare il livello di complessità di un modello di machine learning, agendo sulle caratteristiche del modello utilizzato in fase di learning (detti iperparametri) e verificandone la generalità attraverso le misure di accuratezza applicate al test set:
- nel caso della regressione polinomiale con il gradient descent potevamo far variare l’iperparametro N, ovvero il grado del polinomio: aumentandolo, il modello diventava più complesso, quindi più accurato sul training test e, allo stesso tempo, prono all’overfitting;
- lo stesso vale per le reti neurali: modificando il numero di nodi e di hidden layer possiamo variare la complessità del modello, riportandola opportunamente sotto il livello di overfitting;
- anche negli alberi decisionali possiamo giocare sul livello di complessità: potando in maniera più o meno decisa l’albero e rinunciando ai rami periferici, possiamo ambire a toccare il massimo dell’accuratezza sul test set.
Avere a disposizione queste leve per variare la complessità del modello ci permette di ottenere strumenti analitici predittivi che garantiscono di essere accurati e robusti, ai quali possiamo quindi affidare con tranquillità alcune porzioni del nostro modello operativo. Il consiglio, però, è di mantenersi sempre consapevoli di quelle complessità implementative che non possono essere sottovalutate. Le riassumiamo brevemente.
- Gli algoritmi di machine learning non sono in grado di trasformare magicamente e autonomamente qualsiasi dato in valore economico alla semplice pressione di un bottone. Come abbiamo visto in queste pagine, le macchine sono sempre pronte a svolgere senza sosta il loro lavoro (anche se talvolta ripetitivo e noioso) ma sono le donne e gli uomini che le maneggiano a indirizzarle a dovere. Gli attori principali rimangono infatti quelli dell’analista-operatore, vero addestratore delle macchine, e dei decision maker, i quali, comprendendo limiti e opportunità di questi strumenti, accettano di fidarsi e dar loro lo spazio che meritano. Non possiamo, insomma, nascondere la mano di fronte all’utilizzo dell’intelligenza artificiale: l’uomo è sempre lì, con i suoi compiti e le sue responsabilità.
- Abbiamo imparato a riconoscere che esistono diversi trade-off tra i quali districarsi per individuare l’approccio analitico giusto per noi. Per esempio, c’è bisogno di trovare un compromesso tra complessità e semplicità per evitare l’abbaglio dell’overfitting, mantenendo però prestazioni predittive accettabili. Inoltre, bisognerà anche bilanciare accuratezza e interpretabilità, soprattutto nel momento in cui abbiamo l’esigenza pratica di dover spiegare a noi stessi e ai nostri colleghi ciò che la macchina ha imparato.
- In effetti, la predisposizione di una macchina che impara è un processo intrinsecamente iterativo: sono necessarie continue correzioni e passi indietro per migliorare le prestazioni del modello (agendo sulle varie leve parametriche a nostra disposizione) e renderle robuste. Inoltre, la macchina può svelarci alcuni aspetti del business case sul quale stiamo lavorando che richiedono delle rivisitazioni in corsa dei propri obiettivi e della metodologia da utilizzare. Di conseguenza, questo processo coinvolgerà non solo gli operatori che si sporcano le mani direttamente con i dati ma tutti gli stakeholder del progetto, in maniera trasversale rispetto al livello e alla funzione aziendale.
- In generale, l’utilizzo dell’apprendimento automatico è legato a filo doppio con la necessità di mettere continuamente in discussione quello che presumiamo di aver capito e chiederci se si può fare di meglio, procedendo anche, se necessario, per tentativi. Questo modo di operare (che può rendere il nostro lavoro ancora più divertente e appassionante) ci obbliga a fare nostra la forma mentis tipica dell’esploratore, che unisce un’insaziabile curiosità all’applicazione consistente di un processo strutturato di investigazione. Dobbiamo, in parole povere, allenare la nostra mente alla sperimentazione continua e mantenerla aperta a farsi sorprendere dalle intuizioni dell’intelligenza artificiale.
Questo articolo richiama contenuti dal capitolo 4 di Big Data per il Business.
Immagine di apertura di Chris Liverani su Unsplash.
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Corsi che potrebbero interessarti

Big Data Executive: business e strategie

Strategie e modelli contrattuali per cedere e acquisire software

Data governance: diritti, licenze e privacy
Libri che potrebbero interessarti

Big Data per il Business
Guida strategica per manager alle prese con la trasformazione digitale
Big Data Analytics
Analizzare e interpretare dati con il machine learning