
PROMOZIONE
Lavori con dati e software?
Vuoi essere sicuro di fare le scelte giuste?
Ci sono 4 corsi per te, scoprili e con il codice DATAX50 risparmi 50€ sull’iscrizione a: Big Data Executive, Big Data Analytics, Data governance, Strategie e modelli contrattuali per cedere e acquisire software.
Di che cosa parliamo
- Che cosa si intende per Big Data
- Qual è il significato di Data Analytics
- Quali conseguenze porta con sé la Data Transformation
- Come cambia il management nell’era dei Big Data
- Che cos’è veramente il machine learning
1. Che cosa si intende per Big Data
Intorno al 2013 non si poteva parlare di dati in azienda senza riferirsi, seppure in modo improprio, ai Big Data. Un’osservazione molto indovinata e divertente è stata che i manager trattavano in quel periodo l’argomento Big Data con lo stesso mix di goffaggine e sfrontatezza con il quale gli adolescenti trattano l’argomento sesso:
tutti ne parlano, nessuno sa davvero come farlo ma tutti pensano che chiunque altro lo stia facendo e, di conseguenza, tutti dichiarano di farlo.
Questa indovinata e arguta similitudine è stata fatta nel 2013 da Dan Ariely, professore di psicologia ed economia comportamentale alla Duke University.
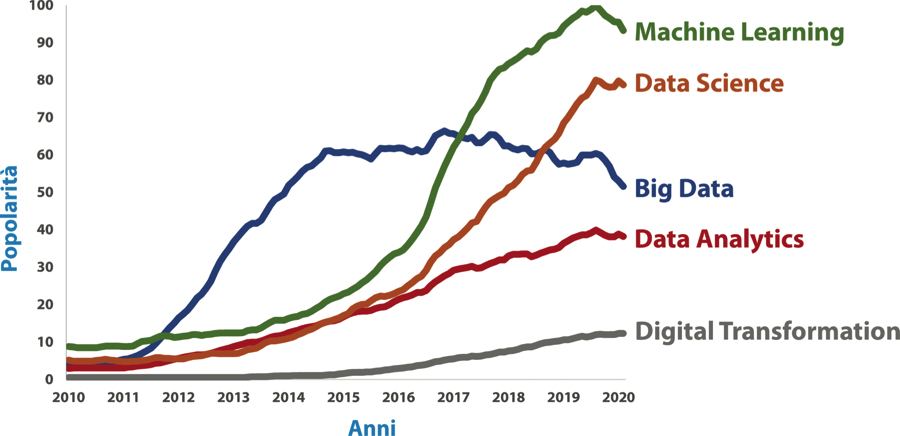
Evoluzione della popolarità di vari termini legati a Big Data nelle ricerche su Google. L’indice di popolarità riporta in termini relativi il numero di ricerche effettuate sul motore di Google ogni mese.
Per mettere a fuoco questo concetto in tutta la sua ampiezza e complessità converrà affidarci a una tra le definizioni formali disponibili e costruire su di essa:
I Big Data rappresentano una raccolta di dati così estesa in termini di volume, velocità e varietà da richiedere tecnologie e metodi analitici specifici per l’estrazione di valore.
In pratica i Big Data sono descrivibili attraverso le 3 V, ovvero il loro notevole Volume (sono in grande quantità), la loro alta Velocità di generazione (e quindi di elaborazione) e l’ampia Varietà nel loro formato (non più dati numerici incolonnati in tabelle ma testo, audio, video in forma variabile).
Questi dati speciali, proprio a causa delle loro particolarità in termini di volume, velocità e varietà, hanno bisogno di strumenti tecnologici e di metodi analitici a loro volta speciali. Per quanto riguarda la tecnologia, in effetti, non ci basterà più utilizzare un semplice computer e con ogni probabilità avremo bisogno di servirci di hardware speciali e infrastrutture distribuite alle quali accedere tramite cloud.
Inoltre, i metodi analitici tradizionali (basati su aggregazioni e semplici calcoli statistici) non saranno più sufficienti per l’analisi di questi dati così speciali, i quali offrono, nella loro diversità e ampiezza, l’occasione di rintracciare strutture molto complesse nel momento in cui ci serviamo di algoritmi di intelligenza artificiale in generale e di apprendimento automatico in particolare.
Come tiene a rimarcare la definizione, questi Big Data sono utili nel momento in cui creano valore economico. Questa definizione ci ha permesso di mettere a fuoco le quattro proprietà essenziali dei Big Data: Informazione (dati con caratteristiche speciali), Tecnologia (all’altezza della particolarità di questi dati), Metodi (per il loro efficace sfruttamento) e Impatto (portando a un’abbondante creazione di valore). Dalle iniziali di queste proprietà otteniamo il nome ITMI del modello rappresentato nella prossima figura.
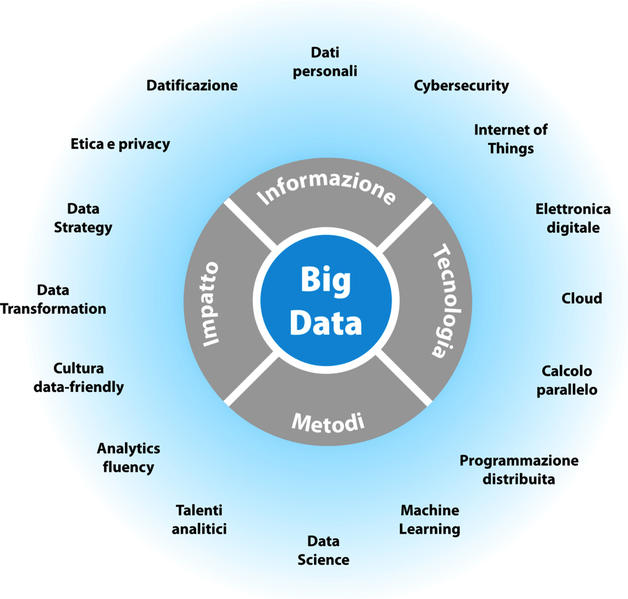
Il modello ITMI (Informazione, Tecnologia, Metodi, Impatto) dei Big Data. Le parole intorno rappresentano gli argomenti più popolari connessi a ciascuna delle quattro componenti di ITMI.
Alcuni fatti specifici possono aiutarci a intuire la scala delle dimensioni dei Big Data.
-
- In una sola ora su YouTube vengono caricate circa trentamila ore di nuovi video: impiegheremmo tre anni e mezzo per guardarli tutti!
- Ogni sessanta secondi Google provvede a rispondere a oltre tre milioni e mezzo di ricerche, mentre su Facebook arrivano tre milioni di nuovi like e tremila nuovi utenti installano TikTok.
- Ai dati generati dai sette miliardi e mezzo di persone che abitano oggi il mondo dobbiamo aggiungere tutti quelli provenienti dai circa trenta miliardi di oggetti intelligenti, in grado di creare con le loro interazioni una vera e propria rete di dispositivi interconnessi, detta l’Internet of Things (IoT, ovvero l’Internet delle cose).

- I dati generati negli ultimi due anni dall’umanità sono equivalenti a quelli generati in tutta la storia dell’uomo dalla sua comparsa sulla Terra fino a due anni fa. In pratica ogni due anni dobbiamo fare i conti con il doppio dei dati a disposizione. Inoltre, si stima che di tutti questi dati venga effettivamente utilizzato solo lo 0,5 percento: è ovvio che l’opportunità di beneficiare dei dati di cui già disponiamo è tutta davanti a noi!
Nella figura che segue si trova l’accostamento delle foto riferite alle elezioni consecutive di due Papi a distanza di otto anni. Se nel 2008 erano in pochi a immortalare l’evento con una foto digitale, che sarebbe perlopiù stata stampata o conservata su un hard disk, nel 2013 quelli che non avrebbero immortalato e, di lì a poco, condiviso sui social network quel ricordo così emozionante costituivano l’eccezione.
In pochi anni è cambiato profondamente il modo di rapportarci con le tecnologie digitali: il nostro interagire con istituzioni, aziende e altre persone è avvenuto sempre più spesso attraverso strumenti informatici, lasciando tracce e registrazioni che hanno ingrandito il bagaglio di dati a disposizione di computer e algoritmi.
L’aumento massivo di disponibilità informativa ha creato nuove opportunità e prospettive di utilizzo, fino a quel momento inesplorate. Pensiamo per esempio ai dati derivanti dalle ricerche effettuate su Google.
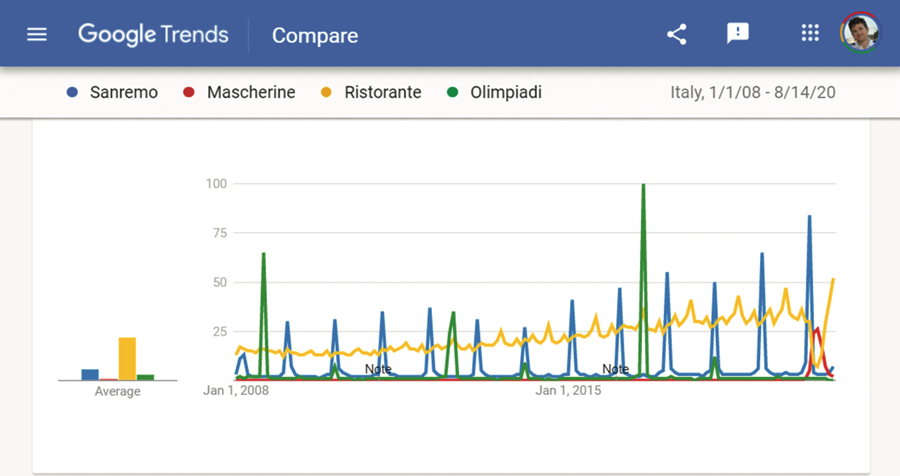
La frequenza di ricerca su Google di alcune parole chiave in Italia.
Questi dati sono in grado di rilevare schemi inaspettati, come per esempio quelli osservati durante il periodo del lockdown che il nostro Paese ha affrontato nel marzo del 2020: le ricerche riguardanti i ristoranti si sono interrotte bruscamente (per poi riprendere alle prime riaperture) proprio mentre la legittima attenzione nei confronti delle mascherine conosceva il suo picco di sempre.
Conviene a questo punto fare una considerazione sugli autentici elementi di novità portati da questi Big Data nel mondo del business. In effetti, a pensarci bene, i dati in azienda ci sono sempre stati: ancor prima dell’arrivo delle tecnologie informatiche, le esigenze di rendicontazione contabile e di analisi dei fattori critici di successo hanno fatto in modo che i numeri costituissero la naturale base del linguaggio economico. Malgrado l’arrivo dei Big Data sia spesso descritto sfruttando la parola rivoluzione, penso sia più opportuno vederlo per quello che è: una rapidissima evoluzione dei modi e delle finalità dell’utilizzo dei dati in azienda. Come rappresentato nella tabella seguente, negli ultimi anni abbiamo assistito alla veloce progressione a senso unico lungo tre direttive fondamentali.
- I dati in sé hanno cambiato pelle davanti ai nostri occhi e la loro estesa disponibilità li ha resi praticamente onnipresenti.
- La potenza tecnologica a disposizione di ormai quasi tutte le aziende era fantascienza per i più, anche solo vent’anni fa.
- Sempre più spesso e in sempre più rami industriali l’uso del dato costituisce l’evidente spartiacque tra successo e fallimento.
| Aspetto | Pre Big Data | Post Big Data |
|---|---|---|
| Varietà dei dati | Strutturati, organizzati in tabelle | Non strutturati (includono linguaggio naturale, immagini, video ecc.) |
| Volume dei dati | Gestibili in maniera centralizzata/locale | Richiedono spesso un’infrastruttura decentralizzata e remota |
| Velocità dei dati | Di natura perlopiù statica, variano nei giorni/settimane/mesi | Di natura dinamica, variano real-time |
| Metodi analitici | Statistica tradizionale, aggregazioni, descriptive analytics | Apprendimento automatico, advanced analytics |
| Utilizzo primario | Miglioramento decisioni interne, tramite reporting descrittivo | Impatto diretto su prodotti, servizi e processi, tramite algoritmi per predizioni e prescrizioni |
| Questa tabella è stata riadattata da quella proposta in: Davenport T., Big data @l lavoro. Sfatare i miti, scoprire le opportunità, Franco Angeli, 2015. | ||
Queste direttive disegnano l’intrinseca complessità della trasformazione ampia, continua e – senza dubbio – ancora in corso che accompagna l’arrivo dei cosiddetti Big Data.
2. Qual è il significato di Data Analytics
Data Analytics indica in senso generico l’insieme delle tecniche e dei metodi analitici che si possono applicare ai dati per trasformarli in qualcosa di utile; un ambito scientifico intrinsecamente multidisciplinare (un mix originale di informatica, matematica, statistica e altre discipline) chiamato data science, ovvero scienza dei dati.
Possiamo immaginare tre macrogruppi di Data Analytics, ciascuno caratterizzato dall’abilità a rispondere a domande di business diverse.
- Descriptive analytics: questi strumenti sono in grado di utilizzare i dati per descrivere ciò che è avvenuto in passato restituendo un’immagine dello stato del business e rispondendo, in pratica, alla domanda che cosa è successo?.
- Predictive analytics: questi metodi analitici utilizzano i dati prevenienti dal passato per predire quello che presumibilmente avverrà in futuro, rispondendo, così, alla domanda che cosa succederà?.
- Prescriptive analytics: questi strumenti sono in grado di sfruttare i dati per generare una lista di azioni da eseguire per raggiungere un determinato obiettivo, rispondendo, quindi, alla domanda che cosa fare?.
Come si ritrova nella figura sottostante, i tre livelli di Data Analytics delineano una crescente opportunità in termini di impatto economico ottenuta al prezzo di una maggiore complessità di esecuzione, ovvero di un bisogno di risorse via via più specializzate e di sponsorship del management sempre più presente.
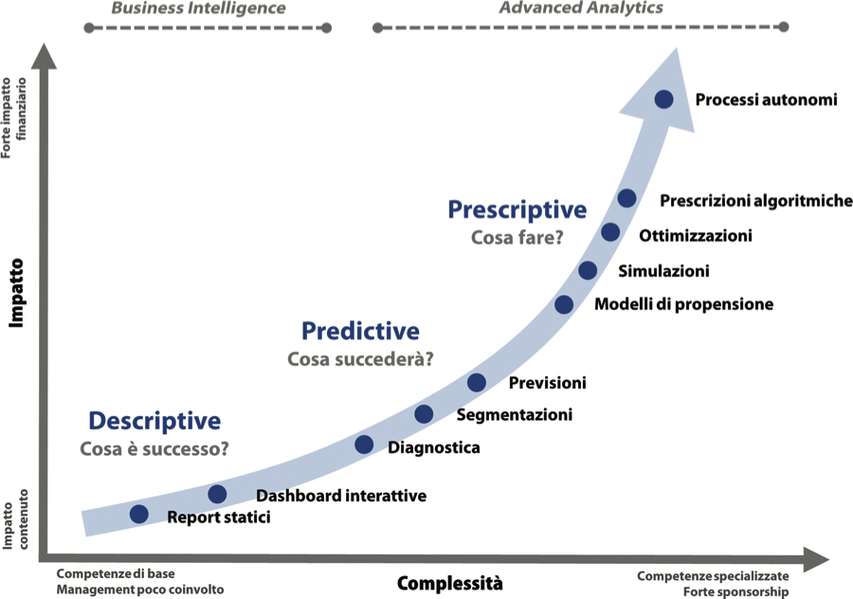
I tre livelli di Data Analytics. vuoi spingerti nella creazione di valore e quale prezzo sei disposto a pagare per ottenerlo?
Immaginiamo di lavorare per un’azienda italiana di medie dimensioni che produce macchine per il caffè e cialde. L’azienda sta conoscendo una grande crescita e negli ultimi mesi sta sperimentando una serie di innovazioni basate sull’utilizzo di dati e algoritmi. Vediamone qualcuna, con l’intenzione di riconoscere gli strumenti analitici che abbiamo appena visto.
- Viene introdotta una dashboard interattiva a sostituire una lunga serie di report che venivano generati all’inizio del mese per aggiornare il consiglio di amministrazione sullo stato del business. La dashboard si aggiorna adesso quotidianamente ed è altamente personalizzabile.
- Grazie a un semplice modello in grado di riconoscere le novità statisticamente significative nell’evoluzione delle vendite, la dashboard viene arricchita di una pagina che riporta ogni settimana un sommario generato in maniera automatica dei cinque trend più importanti da tenere sott’occhio.
- Utilizzando vari tipi di dati esterni (commenti sui social media, recensioni dei consumatori, previsioni del tempo, modelli macroeconomici) e interni (vendite per territorio, richieste di assistenza, livelli di produzione) viene messo a punto un modello di previsione dei consumi di caffè in cialde in grado di stimare le vendite dei prossimi tre mesi per ogni regione d’Italia commettendo un errore medio del ±10 percento.
- Il dipartimento di R&D ha sviluppato un dispositivo IoT in grado di raccogliere i dati relativi all’utilizzo delle macchine del caffè e di permetterne il controllo da remoto tramite app.
- L’azienda cerca di rinforzare il suo canale di vendita diretta tramite la sottoscrizione, ovvero ordini ripetuti automaticamente con regolarità. Per fare questo, viene predisposto un modello di propensione che utilizza i dati relativi agli acquisti passati dei clienti registrati sul sito dell’azienda allo scopo di proporre un’offerta personalizzata di invito alla sottoscrizione. Questo sistema è completamente automatizzato, è in grado di imparare dagli esiti delle offerte precedenti e in pochi mesi triplica il numero di sottoscrizioni attraverso offerte promozionali finanziariamente sostenibili.
Questi esempi (di fantasia ma tutti basati su storie vere) di utilizzo della Data Analytics ci permettono di fare una serie di considerazioni di valenza più generale.
- I vari livelli di Data Analytics non vanno necessariamente visti come alternative.
- Malgrado sia auspicabile spingersi oltre il livello base descrittivo e cogliere le opportunità delle più avanzate analytics predittive e prescrittive (alle quali ci si riferisce infatti con il termine advanced analytics), lo strato di business intelligence sarà sempre utile per il controllo gestionale e costituirà l’immancabile piattaforma di lancio degli strumenti più sofisticati.
- Sebbene la Data Analytics e, quando disponibili, i Big Data (ai quali ci si può riferire congiuntamente con il termine Big Data Analytics) siano in grado di impattare positivamente sul business nei modi più diversi e stravaganti, in generale possiamo riconoscere tre ampie fonti di creazione del valore. La prima è la riduzione dei costi, come la diminuzione dell’inventario nell’esempio precedente. La seconda è l’aumento delle vendite, come la crescita delle sottoscrizioni vista sopra. La terza è molto potenziale, pur avendo un impatto meno diretto sul conto economico rispetto alle prime due: è il miglioramento di decisioni (come quelle prese dal consiglio di amministrazione grazie alla dashboard) e prodotti (come nel caso della macchina del caffè resa intelligente attraverso l’aggiunta di dati e algoritmi).
3. Quali conseguenze porta con sé la Data Transformation
Da sempre le innovazioni tecnologiche hanno plasmato la storia dell’umanità ridefinendo le regole di interazione tra individui e il loro modo di vivere in società. Questo è stato evidente in particolare negli ultimi due secoli e mezzo, durante i quali sono state introdotte una serie di tecnologie pervasive (definite general purpose) in grado di impattare in maniera trasversale e profonda sull’attività economica. Una tra le più evidenti è stata l’introduzione della macchina a vapore da parte di James Watt alla fine del XVIII secolo. Anche l’intelligenza artificiale e, in generale, le Data Analytics sono dotate di questa pervasività e potenzialità e ci stanno proiettando in quella che è stata definita la seconda età delle macchine o la quarta rivoluzione industriale.
Le fasi di una rivoluzione
Ogni buona rivoluzione industriale è scomponibile in tre fasi distinte: un prima, un durante e un dopo.
- Prima della rivoluzione, la conoscenza tecnica e scientifica alla base dell’innovazione tecnologica che la causerà già esiste ma non ha ancora raggiunto quel livello di maturità e di convenienza economica in grado di farla esplodere.
- Quando la tecnologia è finalmente matura, questa inizia a diffondersi molto velocemente, accompagnata da un carico di implicazioni chiaramente visibili e impattanti per l’economia, la società e la singola realtà produttiva.
- Una volta che la novità tecnologica è del tutto integrata nel ciclo produttivo dalla gran parte delle aziende, questa inizia a essere data per scontata.
Pensiamo ora al prima, al durante e al dopo relativo all’arrivo della Big Data Analytics e dell’intelligenza artificiale: i dati ci sono sempre stati e le conoscenze scientifiche alla base degli algoritmi di apprendimento automatico erano già esistenti da tempo.
I primi neuroni artificiali (quelli che poi sfoceranno nelle reti neurali e nel deep learning, oggi una delle frontiere metodologiche più sofisticate) sono stati ideati negli anni Quaranta del secolo scorso. Il termine intelligenza artificiale è stato coniato nel lontano 1956.
Abbiamo dovuto aspettare i primi anni Dieci di questo secolo per vedere la versione matura e scalabile di questi strumenti, finalmente pronti per fare il loro ingresso massificato nelle aziende e nella vita delle persone. Grazie alla progressione esponenziale della capacità di calcolo a costi ridotti e alla disponibilità dei nuovi Big Data, la reazione a catena della rivoluzione si è innescata.
In questi anni viviamo il cuore di questa rivoluzione e ne osserviamo gli effetti: le tecnologie digitali supportano la crescita della produttività media e della ricchezza (ci si aspetta che l’intelligenza artificiale possa da sola accelerare la crescita del PIL medio annuo di circa 1,2 punti da qui al 2030), malgrado negli anni altri rallentamenti dell’economia come la crisi del 2008 e la più recente legata alla pandemia di Covid-19 rendano questi aumenti poco visibili nella vita quotidiana della maggior parte di noi.
Il modello operativo digitale
La visione macroeconomica dell’arrivo delle tecnologie digitali con il loro dirompente effetto sull’industria è descritta come una rivoluzione e in effetti ha degli aspetti poco controllabili, assomigliando a uno tsunami di cambiamenti sistemici fuori dalla nostra area diretta di controllo. In realtà ogni singola azienda ha l’opportunità di organizzarsi per sfruttare anche le onde più potenti e anomale a proprio vantaggio. Questa trasformazione va sotto il nome di Data Transformation (o, più genericamente, Digital Transformation). Per capire l’importanza della Data Transformation, pensiamo alle due componenti essenziali di un’azienda.
- La prima di queste componenti è il modello di business (o business model) ovvero la descrizione della sua proposta di creazione di valore economico (value creation) e il suo piano per monetizzarlo (value capture).
- La seconda componente è il suo modello operativo (operating model) ovvero la descrizione del suo funzionamento. Se il business model definisce che cosa fare, il modello operativo descrive il come farlo.
Una delle caratteristiche del modello operativo aziendale è il suo livello di digitalizzazione, che potremo definire in maniera generale come il grado di centralità di dati e algoritmi nel funzionamento dei processi aziendali.
I modelli operativi digitale e tradizionale hanno dimostrato di rispondere in maniera molto diversa di fronte all’esigenza di accrescere le dimensioni del business, e ciò deriva dalla natura di dati e algoritmi. Quando dati e algoritmi si incontrano nell’esecuzione di un processo di business formano una coppia imbattibile: possono aumentare l’output del loro lavoro a parità di risorse, scalando con costi marginali pressoché nulli.
Quello che invece avviene con il modello operativo tradizionale è molto diverso. All’inizio, quando la scala è limitata, il valore generato è alto e, con molta probabilità, anche maggiore di quanto il modello digitale non riesca a fare, grazie all’estrema flessibilità dell’operatore umano nella gestione di situazioni di cui può avere il pieno controllo. Quando la dimensione del business aumenta, però, con esso cresceranno anche i problemi inerenti alla sua gestione.
>Come mostrato nella prossima figura, i modelli operativi digitale e tradizionale divergono in termini di valore marginale via via che la dimensione del business cerca di crescere. All’aumentare del livello di digitalizzazione la nostra azienda può avere la possibilità di intraprendere la crescita esponenziale tipica del modello operativo digitale, lasciando i competitor meno attenti a dati e algoritmi nella dannazione del modello operativo tradizionale, intrinsecamente refrattario a una crescita sostenibile.
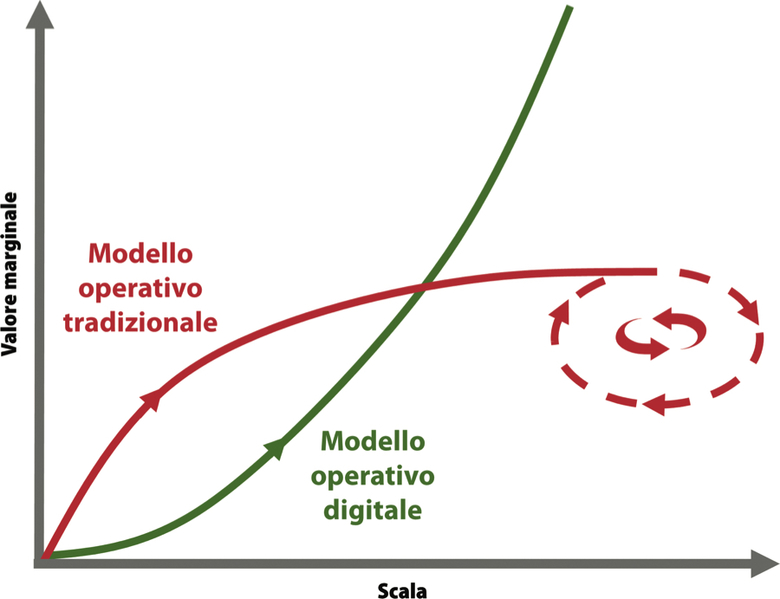
Modelli operativi a confronto. Preferisci quello digitale o quello tradizionale?
La sfida della Data Transformation è tutta qui: aumentare il livello di digitalizzazione aziendale concedendo alla Big Data Analytics e agli algoritmi di intelligenza artificiale il ruolo che meritano durante questa seconda età delle macchine.
4. Come cambia il management nell’era dei Big Data
Il campione internazionale di scacchi Garry Kasparov ha ottenuto il massimo della sua visibilità mediatica nel momento per lui apparentemente più difficile, quello della sconfitta. L’11 maggio del 1997 Kasparov perde la sua partita con Deep Blue, un supercomputer espressamente progettato da IBM allo scopo di giocare a scacchi. Dopo essere stato l’incontrastato numero uno mondiale per ben vent’anni consecutivi, il grande campione perde la sua partita contro un computer, segnando un punto critico nella storia degli scacchi. Da quel momento in poi, infatti, la legge di Moore ci ha messo del suo facendo progressivamente aumentare le performance di gioco delle macchine dotate di intelligenza artificiale rendendole ormai praticamente imbattibili dall’uomo.
Kasparov ha usato la sconfitta come un’opportunità per approfondire i meccanismi possibili di collaborazione tra l’uomo e la macchina, tema di cui nel tempo è diventato un esperto riconosciuto. Subito dopo la sua clamorosa sconfitta il grande campione ha promosso una modalità originale di gioco degli scacchi che va sotto il nome di scacchi avanzati o, più comunemente, freestyle chess, nel quale sono ammessi come giocatori squadre formate da uomini e macchine. L’esito di uno di questi tornei freestyle giocato nel 2005 aveva dell’incredibile: una coppia di scacchisti amatoriali americani poco più che ventenni muniti di tre semplici PC commerciali è riuscita a imporsi su tutte le altre squadre, incluse quelle formate da grandi maestri di scacchi (il titolo più prestigioso da conseguire) che si avvalevano di supercomputer molto potenti.
I due vincitori avevano messo a punto una modalità di collaborazione molto efficiente che prevedeva la divisione dei ruoli in base ai loro rispettivi punti di forza e l’uso dell’AI per specifiche attività di previsione. Kasparov ha presto spunto da questo trionfo del processo, confermato successivamente in molteplici altri casi, per formulare un’osservazione di valenza generale, ricordata da alcuni come legge di Kasparov: la combinazione esseri umani (anche deboli) + macchina + processo migliore è superiore alla combinazione esseri umani forti + macchina + processo peggiore. Kasparov osserva come la “guida strategica” dell’uomo trovi il suo ideale complemento nell’“acume tattico” dei computer, a patto che questi possano amalgamarsi efficacemente attraverso un processo che permetta la loro piena collaborazione, nella quale ciascuna parte sia in grado di esprimere il meglio di sé.
La legge di Kasparov ci offre uno spunto per delineare i contorni delle competenze e dei tratti comportamentali che è verosimile aspettarsi dal manager del futuro, in grado di gestire efficacemente esseri umani e macchine in un’organizzazione data-centric.
Il manager che verrà sarà dotato di alcune caratteristiche inedite e non tradizionali, come per esempio:
- è in grado di progettare le organizzazioni e i processi aziendali orchestrando congiuntamente persone e algoritmi, senza mai limitarsi all’una o all’altra componente ma concentrandosi proprio sul ruolo cruciale del processo di collaborazione tra esseri umani e macchine;
- non è necessariamente un esperto di algoritmi ma li conosce nei loro tratti fondamentali e ne riconosce i potenziali casi di utilizzo nel business che gestisce;
- nel prendere decisioni è in grado di bilanciare la sua esperienza con ciò che dati e algoritmi propongono;
- dimostra di avere data acumen, ovvero di essere in grado di annusare in anticipo le opportunità di sfruttamento della data analytics per risolvere le proprie esigenze.
Se sommiamo i tratti appena elencati a tutte le altre aspettative che è lecito mantenere nei confronti di un buon leader, appare ovvio che non sarà facile trovare profili così bilanciati e completi almeno nel breve termine. Ciononostante, converrà a manager e aziende iniziare da subito a organizzarsi per lo sviluppo di queste abilità e competenze nelle attuali risorse umane, in modo da non rimanere impreparati a queste emergenti necessità di leadership.
5. Che cos’è veramente il machine learning
Il machine learning è una variante dell’approccio tradizionale alla programmazione informatica. Il metodo tradizionale di programmazione (suonerà davvero ovvio) prevede quattro elementi fondamentali:
- i dati di partenza;
- il programma, ovvero il codice da eseguire;
- un computer che esegue il codice utilizzando i dati di partenza come input;
- i risultati, ovvero nuovi dati in uscita.
Affinché questo approccio (rappresentato nella prossima figura) funzioni, è essenziale la figura del programmatore, una persona capace di codificare, ossia di descrivere in maniera formale i passi che il computer dovrà eseguire. Per descrivere questi passi, il programmatore userà una lingua comune tra uomo e macchina, il linguaggio di programmazione. Alla base c’è un assunto importante: il programmatore è in grado di descrivere come passare dai dati iniziali al risultato e, quindi, deve conoscere il tipo di legame che li unisce.

L’approccio tradizionale alla programmazione informatica. Otteniamo in uscita il risultato di un’elaborazione.
Questo requisito viene superato dall’approccio dell’apprendimento automatico, nel quale è alla macchina viene richiesto di capire il legame che unisce dati e risultati. Con il machine learning, infatti, gli ingredienti di base sono gli stessi, vale a dire dati, programma, computer e risultato. Ciò che muta è il loro ordine: il programma che riesce a legare dati e risultato non è più un input in ingresso ma diventa l’output in uscita al computer. L’algoritmo di machine learning impara come passare in modo verosimile dai dati al risultato e restituisce questo processo in uscita, come possiamo osservare qui di seguito.

L’approccio del machine learning. Otteniamo in uscita il programma che lega dati a risultati attesi.
Prima di concentrarci su come sia possibile che una macchina sia in grado di imparare, è utile ragionare sull’enorme potenziale di questo nuovo approccio. Rispetto alla programmazione tradizionale, il machine learning ha due chiari vantaggi:
- il primo è che possiamo riutilizzare il programma generato dal computer a nostro piacimento, facendolo girare su dati nuovi, ottenendo così nuovi risultati. Questa possibilità ci permetterà di sfruttare ciò che la macchina ha imparato e riapplicarlo su casi futuri, amplificando così il valore del programma. Come si vede nella figura seguente, per fare questo avremo bisogno di utilizzare entrambi gli approcci di programmazione descritti sopra, in due blocchi sequenziali: il primo blocco, detto learner, esegue la fase di apprendimento per generare un programma, usando uno degli algoritmi di machine learning (detti, per l’appunto, algoritmi di learning); il secondo blocco, detto predictor, sfrutta invece l’approccio tradizionale per riapplicare il programma generato dal learner su nuovi dati;
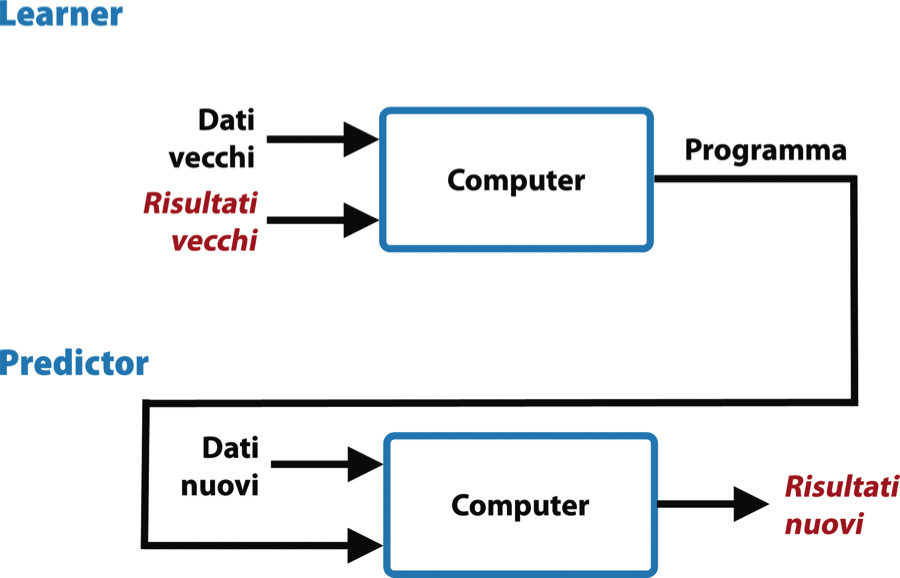
Predizione tramite machine learning. Il programma generato dal computer viene riapplicato su altri dati.
- il secondo vantaggio è legato alla capacità delle macchine di identificare delle connessioni estremamente complesse tra dati e risultati, grazie al fatto che, rispetto all’uomo, possono valutare insieme molti più dati. A volte queste connessioni (dette anche pattern) sono insolite, inaspettate o, semplicemente, nessun uomo le aveva mai notate prima. Di conseguenza, in alcuni casi, l’uomo può imparare qualcosa di esplicito dai dati utilizzando il machine learning, che ci offre, quindi, il vantaggio di poter “creare conoscenza” (in inglese knowledge discovery).
Questo articolo richiama contenuti da Big Data per il Business.
Immagine di apertura di Stephen Dawson su Unsplash.
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Corsi che potrebbero interessarti

Big Data Executive: business e strategie

Data governance: diritti, licenze e privacy

Big Data Analytics - Iniziare Bene
Libri che potrebbero interessarti

Big Data per il Business
Guida strategica per manager alle prese con la trasformazione digitale
Software Licensing & Data Governance
Tutelare e gestire le creazioni tecnologiche