

Schietto e senza peli sulla lingua, sa essere ironico e andare al punto. Gli abbiamo sottoposto un sacco di domande e lui ha risposto a tutto, tanto che abbiamo diviso in due l’intervista (la seconda metà uscirà domani).
Dmitry Zinoviev è l’autore di Data Science con Python, che esce oggi per i tipi di Apogeo, e pensiamo che poche volte sia accaduto, come in questo caso, che dall’intervista si possa capire quanto è valido il libro. Prima di cedere la parola a Dmitry, desideriamo ringraziare Sabino Maggi per la collaborazione. Buona lettura!
Apogeonline: Perché scegliere Python, linguaggio generico, rispetto a un linguaggio specifico come R?
Dmitry Zinoviev: Almeno per due ragioni. La prima è che R è un brutto linguaggio, progettato e implementato da statistici, per i propri scopi, più che da informatici. La sua sintassi e la sua semantica sono antiintuitive. È lento e inefficiente. (La prossima volta parliamo di un dataset Yelp che R ha letto in venti minuti, e Python in uno). Se sei cresciuto come programmatore di computer, imparare R può avvicinarsi alla tortura. Se R è il tuo primo linguaggio di programmazione, sarà una tortura impararne altri dopo. La seconda ragione è che R comunque brilla in qualche modo nell’elaborazione standard dei dati: individuazione di dati anomali, regressioni, classificazioni, machine learning… in altre parole, quando i dati sono già ordinati in comode tabelle. Convertire in tabelle dati provenienti da rappresentazioni misteriose e intricate, non tabellari, invece, è un compito dove i linguaggi generici non hanno rivali.

Quasi un obbligo per il moderno data scientist.
Python dispone di numerosi ambienti integrati di sviluppo (IDE); la data science si basa su molte librerie software differenti e anche nel campo della visualizzazione non c’è un software chiaramente prevalente (anche se matplotlib ci va vicino). Queste tante opzioni potrebbero confondere i nuovi arrivati invece di aiutarli?
Mi permetto di dissentire. Ci sono tante librerie, ma quasi sempre ogni particolare tipo di analisi ha la sua: NLTK l’analisi del testo, Beautiful Soup per il parsing di HTML e XML, pandas per elaborare dati tabellari, networkx per l’analisi di rete, matplotlib per la visualizzazione, scikit-learn per il machine learning, biopython per la bioinformatica e così via. Il novizio può fermarsi alle librerie più note, dove troverà template, framework e consigli in quantità. Si cercano alternative se la libreria-tipo non supporta qualcosa.
Secondo rilevazioni come quella di Burtch Works, al momento R è molto più usato di Python. Nel contempo l’uso di Python aumenta e molti passano a quest’ultimo o scelgono di volta in volta. Che evoluzione prevedi nei prossimi anni?
Per prima cosa tendo allo scetticismo verso queste analisi. Mentre scrivo queste note, su Monster.com compaiono 307 offerte di lavoro nella data science con R, contro 328 con Python. Solo un singolo punto di osservazione, ma lo trovo indicativo. Un altro indizio: leggo da Amazon.com che l’ultimo libro su R è stato pubblicato in ottobre 2014 e il penultimo in aprile dello stesso anno; nel solo 2017 sono usciti oltre cinquanta libri su data science e Python. Scrivo libri tecnici e so che vengono pubblicati solo in presenza di un mercato. Prevedo che i data scientist in quota Python aumenteranno; non a danno di R, ma a beneficio dei laureati in informatica che preferiranno guadagnare di più nella data science che nella programmazione classica. Occuperanno le nicchie di data discovery/acquisition e machine learning/big data, lasciando ai programmatori R la ricerca tradizionale, orientata alla statistica.
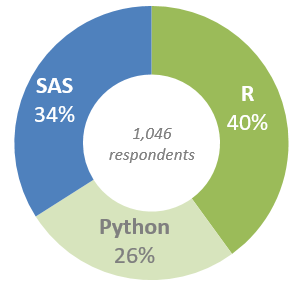
La domanda di Burtch Works: preferite Python, R o SAS?
Ok, parliamo di data science allora. Come riconosciamo i dati che contano da quelli che no?
Esistono vari strumenti (chiamati feature selector) che adottano euristiche per eliminare le variabili a bassa varianza, quelle che meno probabilmente influiranno sul risultato finale. Detto questo, ammetto che la feature selection lavora su dati che sono già stati raccolti e, siccome la raccolta è costosa, vederli decimati può nuocere al morale e al budget. Idealmente, i dati che non contano non dovrebbero nemmeno essere raccolti. Spesso si può partire in piccolo e reperire più dati se e quando vediamo che non bastano a spiegare i fenomeni che analizziamo.
Il data mining solleva problematiche di riservatezza. È possibile tutelare i singoli e lavorare utilmente sulla massa?
Per definizione, il data mining estrae dai dati schemi ricorrenti (pattern). È una tecnica di aggregazione che esclude intenzionalmente le deviazioni dalla norma e le eccezioni alle regole, lontano dai singoli record di un dataset. È la raccolta dei dati per i data mining che può causare e causerà problemi di privacy, non il data mining in sé. Abbiamo peraltro esempi di protocolli di riservatezza dal successo ragionevole nella ricerca medica e nelle scienze sociali. L’applicazione imposta e sistemica a tutti i dati di tecniche di anonimizzazione come quelle usate negli esempi di cui sopra ridurrà significativamente i rischi dei consumatori.
Hai usato il machine learning nella vita privata? Che cosa potremmo farcene, almeno in teoria?
Sì, ho praticato analisi di rete almeno una volta. C’è stato un momento in cui le interfacce di programmazione applicativa (API) di Facebook permettevano di estrarre le connessioni di qualcuno e c’era una app che mostrava gli amici Facebook dell’utente, nonché i loro amici: la chiamavano la ego network. Ho usato la app e mi sono accorto che alcuni dei miei amici si conoscevano, inaspettatamente; il che mi diede ampi spunti di riflessione e conversazione. A parte questo episodio, non mi aspetto che i data scientist traggano beneficio nella loro vita privata dalle loro capacità. Non per insufficienza delle suddette, semmai perché non servirà: la data science arriverà silenziosamente a permeare le vite di tutti, preconfezionata in forma di apparecchi della Internet delle cose, auto a guida software, telefoni intelligenti eccetera.

La data science è già dentro le vite di tutti noi; dobbiamo solo fare mente locale.
La conoscenza si genera dal machine learning quasi dal niente, inaspettatamente, o sappiamo che vogliamo arrivare a quel certo tipo di informazione e lavoriamo per arrivarci? È possibile trovare connessioni che non sapevamo di voler cercare?
Entrambe le cose. La fisica insegna che il mondo attorno a noi è perlopiù lineare o linearizzabile. Molte domande hanno pertanto risposte lineari e tutto quello che ci serve è trovare i coefficienti della linearità. Non c’è serendipità nell’esecuzione di una regressione lineare. La teoria della complessità ci insegna tuttavia che che, se qualcosa è non lineare, è probabilmente non lineare in modo clamoroso; e questo vale per la gran parte dei fenomeni sociali e comportamentali. Quando analizziamo un sistema complesso, capita di non ottenere alcunché. Dopo un po’ cominci a chiederti se il problema che stai affrontando sia lineare o meno. E nell’aria aleggia la serendipità.
Un neofita potrebbe leggere che la data science non fa che rispondere a cinque domande: 1) A o B? 2) È fuori dal comune? 3) Quanto, o quanti? 4) Come è organizzato? 5) Che cosa devo fare dopo? e ogni domanda usa una famiglia differente di algoritmi. È una rappresentazione corretta, per quanto rozza?
Si nota la mancanza della domanda zero: Come ci arrivo? Molti (la maggior parte?) dei dataset più interessanti, utili e stimolanti non esistono in alcuna forma relazionale o tabellare ordinaria, bensì come raccolte informi di pagine HTML; immagini, caselle di posta, file di log di server e testo puro in linguaggi sovente diversi dall’inglese, il tutto senza alcuna struttura. La prima domanda cui deve rispondere un data scientist è da dove ottenere i dati e come renderli fruibili. Direi anche che alla quinta domanda, più che i data scientist, rispondono i data sponsor, che finanziano la ricerca.
Prima gli scientist, adesso tutti: la data science può calarsi in modo utile nella vita di ciascuno? La vita è una esperienza incessante di data science. Qualsiasi previsione, da arrivo tra cinque minuti a sta per piovere sono esempi di machine learning, dove la machine è il nostro cervello. Sono attività basate du dati di addestramento (la nostra esperienza) e una vasta raccolta di modelli di dati cablati sempre dentro la nostra testa. Lo stesso vale per la classificazione. La data science in senso formale è una misera simulazione delle nostre procedure quotidiane di apprendimento e decisione.
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Corsi che potrebbero interessarti

Big Data Analytics - Iniziare Bene
Libri che potrebbero interessarti

Data Science
Guida ai principi e alle tecniche base della scienza dei dati
Data Science con Python
Dalle stringhe al machine learning, le tecniche essenziali per lavorare sui dati