

Nessuna delle tecnologie impiegate per dare vita alle AI generative è particolarmente straordinaria o innovativa; l’insieme dei loro utilizzi è tuttavia in grado di metterci a disposizione strumenti davvero mai visti prima per come sono capaci di assisterci.
Come funzionano queste macchine viste dall’interno
DALL·E 2, Midjourney, ChatGPT, Bard e tutte le macchine analoghe che verranno in futuro sono basate su reti neurali. Le reti neurali sono modelli computazionali, strutture logico-matematiche ispirate al funzionamento del cervello biologico.
Possono essere fisiche – ovvero costruite mediante circuiti, come avveniva per le prime macchine di questo tipo – oppure immateriali: programmi, software, che girano su computer di varie dimensioni e potenze.
Leggi anche: Che cos’è l’intelligenza artificiale e come può esserti utile in azienda
Immaginiamo di poter smontare una rete neurale fino alla sua unità funzionale più piccola, in pratica fino al suo componente più piccolo che mantiene tutte le funzioni della rete neurale stessa, e poi di ricostruirla via via. L’unità funzionale più piccola di una rete neurale è un neurone artificiale, esattamente come l’unità funzionale più piccola del cervello è il neurone.
Puoi immaginare un neurone artificiale come un nodo in un vasto network di nodi interconnessi (gli altri neuroni). È un’unità di elaborazione base che riceve input da dati esterni oppure da altri neuroni. Ogni input è pesato, ovvero ha una sua importanza specifica relativa. Il peso di un input viene attribuito grazie a un coefficiente numerico che rappresenta, appunto, l’importanza relativa del segnale che arriva al neurone.
Il neurone artificiale somma quindi tutti questi input pesati, applica una funzione di attivazione – una funzione matematica che determina se e quanto il neurone deve attivarsi – e produce un output. Questo output viene poi inviato ad altri neuroni, che lo ricevono come input.
Se dovessimo disegnare un neurone artificiale, avrebbe un aspetto simile a un cerchio (che rappresenta il neurone stesso) dal quale partono e arrivano una serie di frecce, che rappresentano gli input pesati e l’output, ma anche le connessioni con l’esterno o con altri neuroni: le sinapsi.
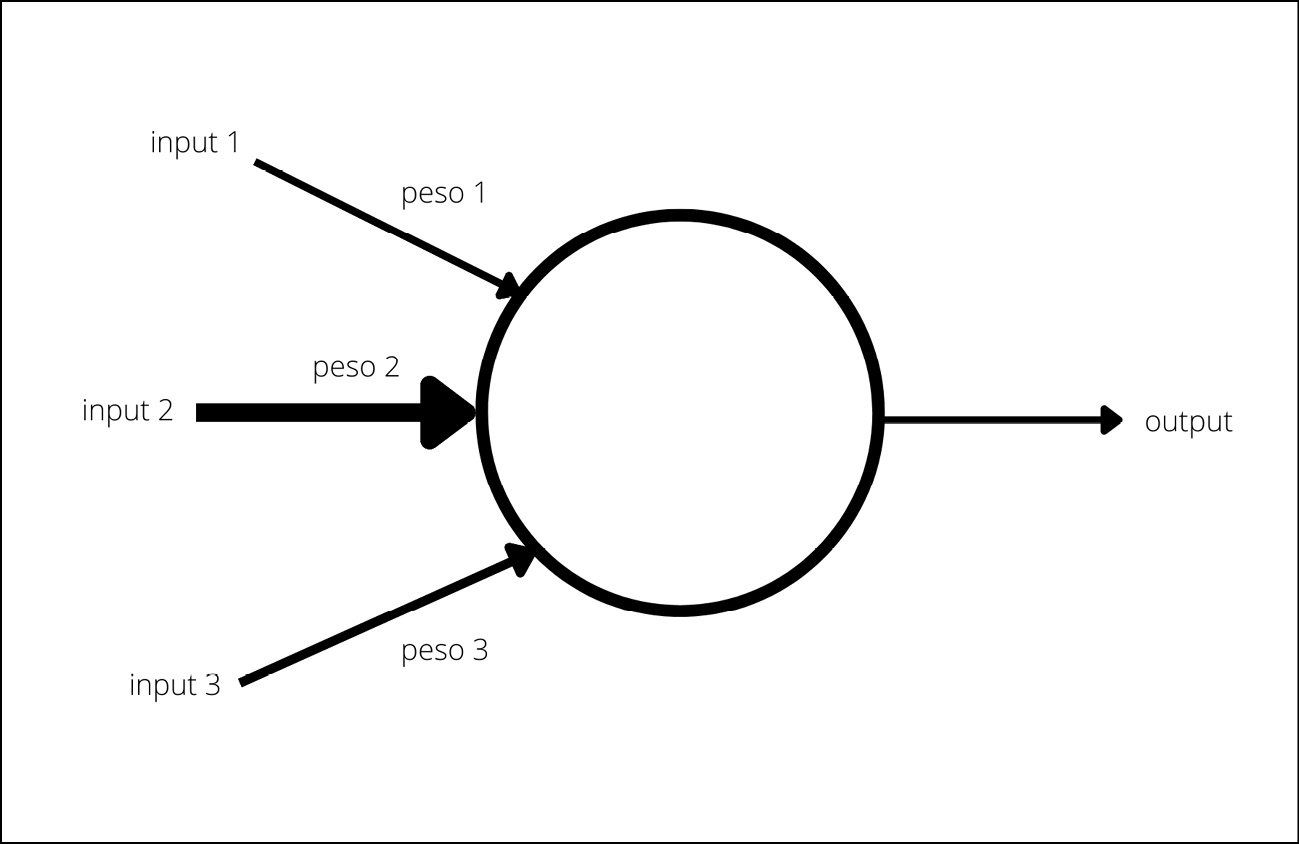
La schematizzazione di un neurone artificiale. Il cerchio rappresenta il neurone, le frecce in ingresso gli input, ciascuno con il proprio peso, la freccia in uscita è l’output.
Proseguiamo con la ricostruzione: combinando insieme molti di questi neuroni, possiamo creare uno strato di rete neurale. Le connessioni tra i neuroni sono, appunto, le sinapsi artificiali: ciascuna connessione ha un suo peso. I pesi rappresentano l’apprendimento della rete neurale: modificandoli, la rete neurale si adatta e impara dai dati. Questi strati sono, poi, interconnessi fra loro: i neuroni di uno strato inviano i loro output ai neuroni dello strato successivo. Nelle reti neurali più semplici, i dati scorrono in una sola direzione: partono da uno strato di input, attraversano uno o più strati nascosti, raggiungono uno strato di output. Questo tipo di reti neurali è chiamato rete neurale feed-forward.
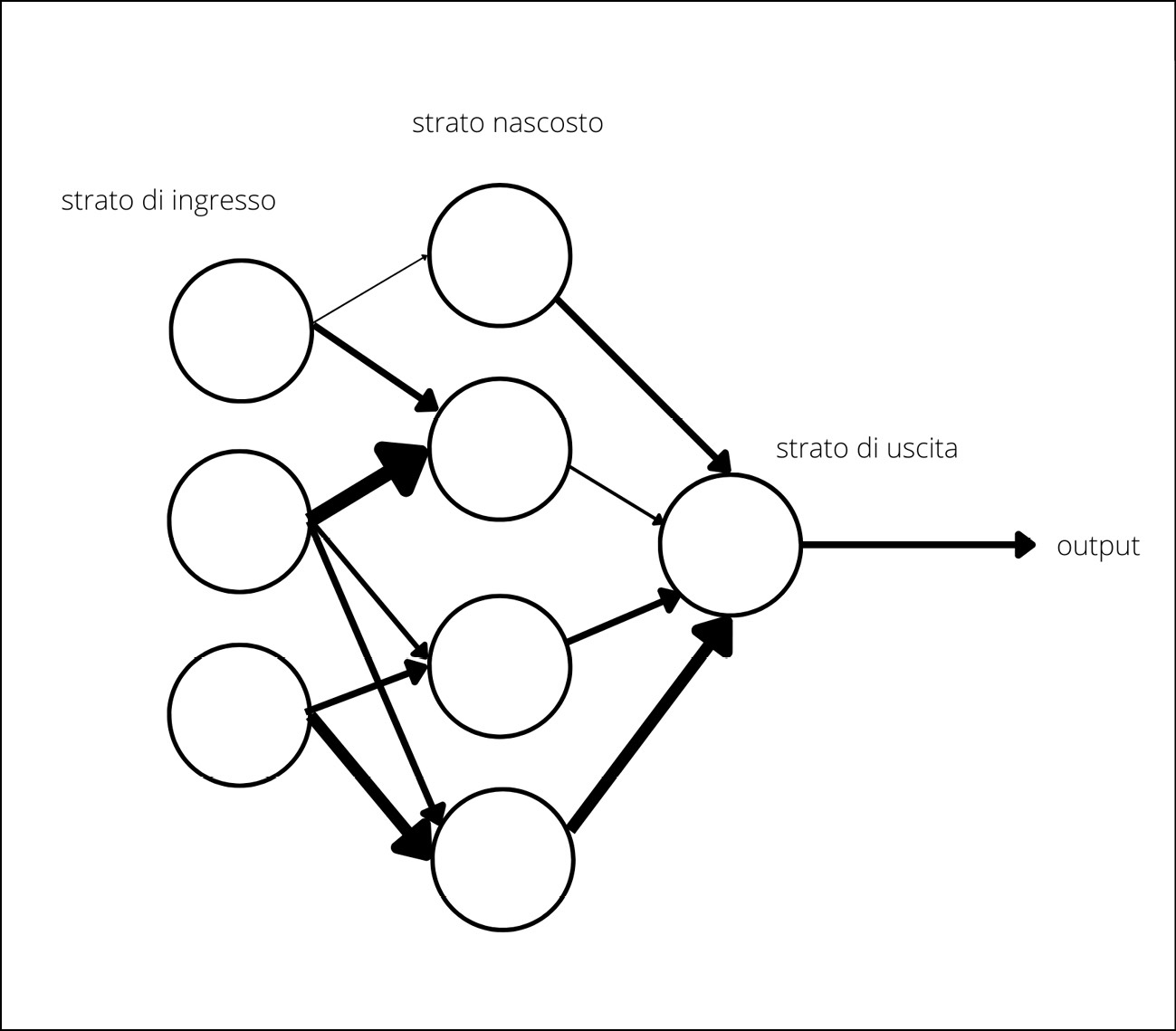
La schematizzazione di una rete neurale feed-forward, fatta da otto neuroni. I primi tre da sinistra sono lo strato in ingresso, poi ci sono i quattro neuroni dello strato nascosto, infine un neurone dello strato in uscita.
Le cose, poi, si possono complicare ulteriormente: nelle reti neurali più complesse, come le Reti Neurali Convoluzionali (CNN) utilizzate nell’elaborazione delle immagini, o le Reti Neurali Ricorrenti (RNN) impiegate dal 1980 nell’elaborazione del linguaggio naturale, le connessioni vanno avanti e indietro tra gli strati e possono essercene anche all’interno dello stesso strato. In queste reti, i dati venivano elaborati in maniera sequenziale. A partire dal 2017 sono arrivate le tecnologie Transformer.
A differenza delle vecchie RNN, i Transformer non processano i dati sequenzialmente, ma utilizzano un meccanismo che viene chiamato attenzione. L’attenzione permette al modello di concentrarsi su differenti parti dell’input simultaneamente, determinando l’importanza di ogni singola parte per la comprensione del contesto. I Large Language Model, le Text-to-Image e le Text-to-Video sono esempi di reti neurali Transformer.
Ecco: abbiamo smontato e rimontato insieme una di queste macchine. Adesso è il momento di addestrarle.
E ora, l’addestramento, l’inferenza e altre storie
Al di là delle competenze tecniche specifiche, una delle difficoltà più grosse che incontriamo smontando e rimontando questi strumenti è il fatto che le parole che utilizziamo sono normalmente attribuite a capacità o caratteristiche umane o almeno animali: intelligenza, attenzione, imparare, neuroni, allucinazioni, addestramento sono tutti termini che contribuiscono a confonderci un po’ di più le idee.
Non abbiamo, tuttavia, altri termini a disposizione e non possiamo sforzarci di costruire un vocabolario parallelo per tutto. Bisogna accontentarsi, cercando di ricordarci di cosa stiamo parlando ogni volta.
Le reti neurali non funzionano da sole e non basta programmarle: hanno bisogno di un addestramento, che avviene sulla base dei dati proposti come input – a volte si dice, colloquialmente, dati in pasto – alla macchina. La macchina, quindi, li elabora e restituisce un output. A questo punto, l’output viene valutato da un essere umano o da un’altra macchina. Il processo viene ripetuto su un gran numero di esempi di dati, fino a quando la rete non è più in grado di migliorare significativamente la sua precisione.
Tutto questo processo di addestramento viene eseguito utilizzando un set di dati chiamato proprio set di addestramento. Una volta addestrato, il modello può essere testato su un nuovo set di dati, definito set di test, per valutare la sua capacità di generalizzare a nuovi esempi.
L’intero processo – da quando si inizia l’addestramento alla validazione finale sul set di test – è supervisionato da esperti di machine learning, che si occupano di regolare i parametri del modello, tra cui, per esempio, il tasso di apprendimento e la funzione di attivazione dei neuroni, in base ai risultati ottenuti durante l’addestramento.
L’apprendimento della macchina, quindi, non è un processo completamente autonomo, ma richiede un costante intervento umano per assicurarsi che il modello stia imparando nel modo corretto. Le due principali categorie sono:
- apprendimento supervisionato;
- apprendimento non supervisionato.
Nell’apprendimento supervisionato, disponiamo di un insieme di dati di addestramento che include sia le caratteristiche di input sia le etichette di output corrispondenti. In altre parole, abbiamo sia le domande sia le risposte. L’obiettivo è addestrare il modello in modo che possa apprendere una funzione che collega correttamente l’input all’output.
Facciamo un esempio per chiarire il concetto. Voglio creare un modello in grado di riconoscere se una foto raffiguri un cane o un gatto. Darò in pasto alla macchina una serie di immagini di cani e gatti e le etichetterò, in modo che riceva, per ciascuna di esse, l’etichetta cane o gatto. Una volta addestrato, il modello dovrebbe essere in grado di riconoscere immagini di entrambi gli animali che non ha mai visto – cioè ricevuto in input – prima.
A questo punto, bisognerà valutare l’output e verificare se le previsioni del modello corrispondono all’effettiva etichetta dell’immagine. Se mostro al modello una foto di un cane che non ha mai visto prima, mi aspetto che sia in grado di fare un’inferenza: mi aspetto che l’output sia cane. Se così non è, allora il modello ha commesso un errore e dovrà essere ulteriormente addestrato.
Questo processo di addestramento e valutazione si ripete per un gran numero di volte, con il modello che gradualmente affina la sua capacità di distinguere tra cani e gatti. Il modello impara, come abbiamo visto, modificando i pesi associati alle sue connessioni neurali, in modo da migliorare progressivamente la sua precisione.
Naturalmente, se poi mostro a una macchina addestrata in questo modo la foto di un cavallo, non sarà in grado di riconoscerla, ma potrebbe, se progettata per farlo, dire che non è né cane né gatto. Per farle riconoscere i cavalli, dovrei ricominciare l’addestramento da capo, con immagini apposite correttamente etichettate.

Se capiamo bene i loro pregi e difetti, le IA generative possono essere le nostre migliori assistenti.
Nell’apprendimento non supervisionato, invece, abbiamo solo i dati di input. L’obiettivo è trovare tra i dati di input delle strutture o dei pattern ricorrenti. Il che potrebbe implicare l’aggregazione dei dati in cluster sulla base della loro somiglianza (clustering) oppure trovare delle regole che descrivano o ipotizzino relazioni tra vari elementi (scoperta di regole di associazione).
Per esempio, un caso di clustering potrebbe essere l’analisi, da parte di un algoritmo di apprendimento non supervisionato, di un enorme volume di articoli di giornale. La macchina potrebbe raggruppare gli articoli in insiemi sulla base di parole-chiave o temi simili, senza che nessuno le abbia detto esplicitamente quali siano questi temi. Senza, cioè, etichette specifiche.
Anche i sistemi di raccomandazione come quelli utilizzati da Amazon o Netflix o dai feed dei social che frequenti abitualmente sono esempi di apprendimento non supervisionato. In questo caso, l’algoritmo potrebbe analizzare i comportamenti di acquisto o visualizzazione dei clienti e rintracciare associazioni fra diversi prodotti o film o libri, scoprendo che le persone che acquistano un certo libro tendono anche ad acquistare un determinato tipo di cuscino per la lettura, per esempio, o che gli individui che guardano una certa serie TV tendono anche a guardare uno specifico tipo di film. Questi pattern possono poi essere utilizzati per fare raccomandazioni personalizzate: si tratta di un processo noto come scoperta di regole di associazione.
Se vuoi vedere in azione questo processo, puoi lavorarci in prima persona in due modi: il primo è valutare come cambiano le raccomandazioni dei tuoi feed a seconda delle tue abitudini di navigazione o di acquisto. Il secondo è utilizzare una macchina basata su queste tecnologie che si chiama Open Assistant. È un chatbot, come ChatGPT, ma, a differenza del suo famosissimo omologo, è completamente libero sia nell’accesso sia nell’ispezione. Si tratta di un progetto di LAION, un’organizzazione non-profit la cui missione è fornire insiemi di dati, strumenti e modelli per liberare la ricerca sul machine learning. Come scrivono nel loro sito:
Nel farlo incoraggiamo un’educazione pubblica aperta e un uso delle risorse più eco-compatibile, riutilizzando dati e modelli già esistenti.
Questo approccio è molto sensato, molto contemporaneo e dovrebbe essere una delle principali battaglie da combattere: aprire queste tecnologie, renderle libere e riutilizzabili, oltre che ispezionabili.
Se ti colleghi a Open Assistant, puoi contribuire all’addestramento della loro rete neurale e vedere come funziona in generale un processo del genere.
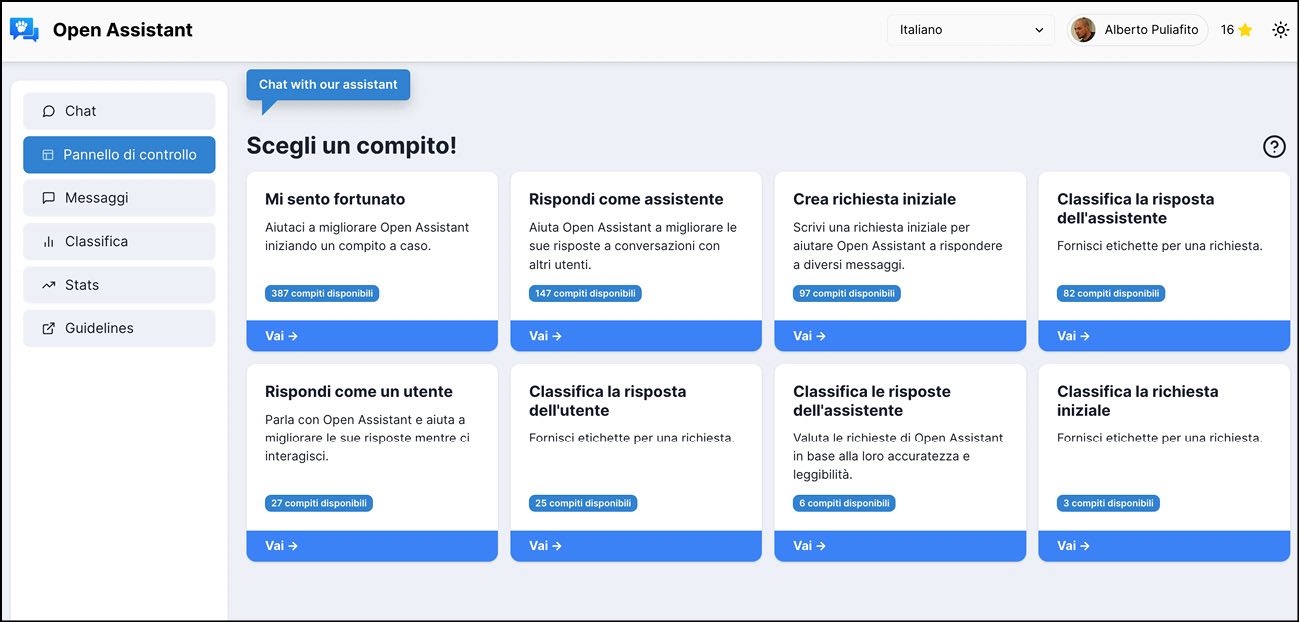
L’interfaccia di Open Assistant in italiano da cui puoi scegliere un compito da eseguire per contribuire a migliorare la macchina.
Per esempio, nella prossima figura possiamo vedere una domanda fatta da una persona che usa Open Assistant (l’input) e la risposta della macchina (l’output).
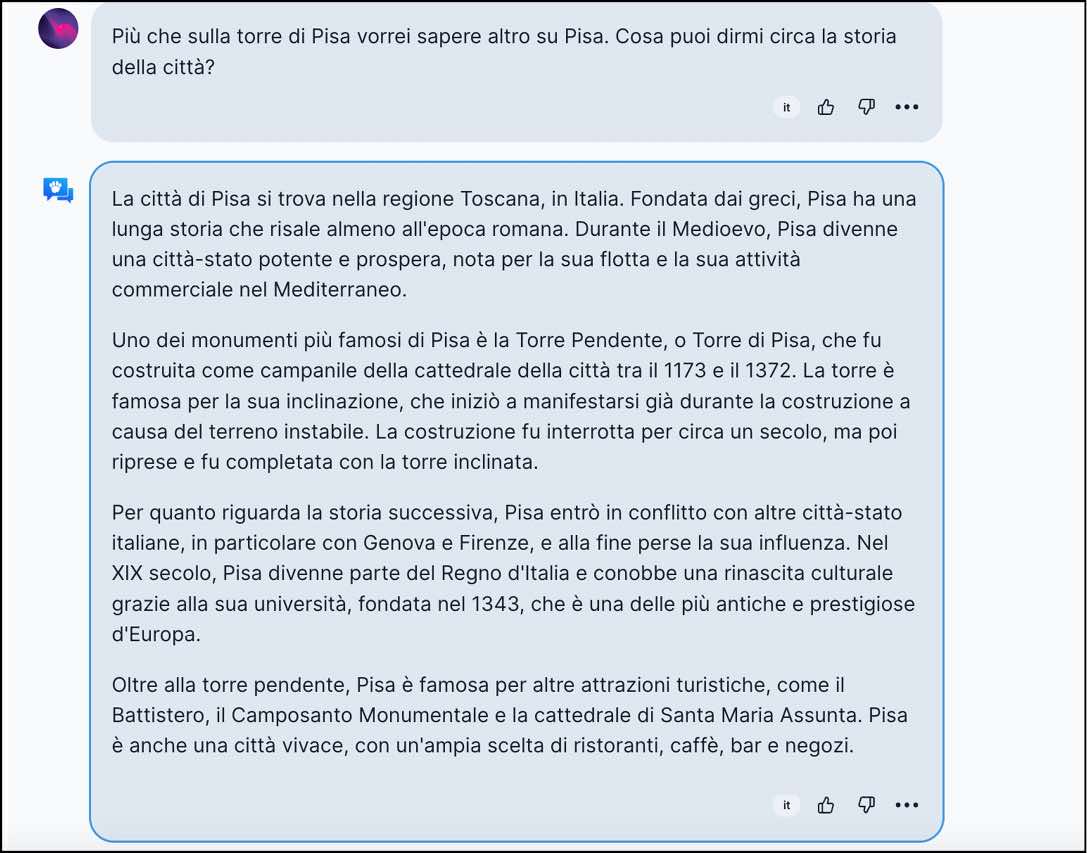
Domanda e risposta nell’interazione di Open Assistant. La persona che ha fatto la domanda è anonimizzata e generalmente non si trovano domande che possano rivelare dettagli personali.
Per contribuire all’addestramento, viene richiesto di dare una serie di valutazioni a questa risposta.
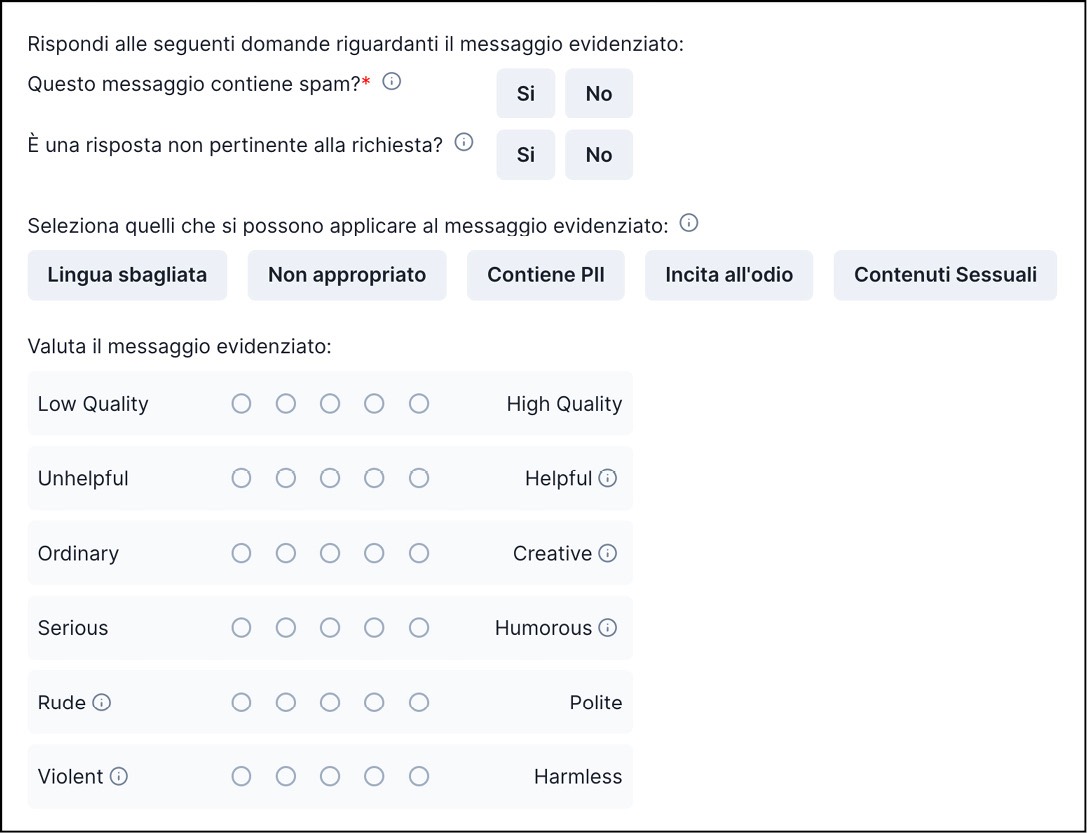
La griglia di valutazione delle risposte di Open Assistant.
Puoi indicare se la risposta è equiparabile a spam, se è pertinente o meno, se ci sono eventuali errori o contenuti inappropriati e puoi anche dare una valutazione da 1 a 5 per il grado di qualità, il grado di utilità, il grado di creatività, il tono di voce (da serio a umoristico), l’atteggiamento (da scortese a cortese), l’atteggiamento incoraggiato (da violento a innocuo).
I feedback vengono quindi raccolti e utilizzati per addestrare ulteriormente la macchina, in modo che possa fornire risposte migliori in futuro.
L’aspetto interessante in questo processo è che non solo aiuta la macchina a migliorare – se i feedback vengono lasciati in maniera corretta ed efficace – ma ti dà anche una comprensione più profonda di come funzionino queste macchine e del modo in cui vengono addestrate. Potresti, per esempio, notare che le risposte della macchina sono a volte vaghe o evasive; oppure che tendono a essere troppo letterali o pedanti. Questo è in parte dovuto al fatto che le macchine non hanno una comprensione reale del mondo o del contesto in cui operano. Le risposte vengono generate in base ai dati con cui sono state addestrate e ai pesi correnti dei loro neuroni artificiali. I pesi determinano quanto la macchina presti attenzione a certi input rispetto ad altri e quanto valore attribuisca a determinati input piuttosto che ad altri.
Se pensi alla risposta di una macchina come a una specie di voto di maggioranza tra i suoi neuroni, allora puoi iniziare a capire perché potrebbe dare certe risposte invece che altre, anziché prenderla in giro perché sbaglia.
In conclusione, lavorare con Open Assistant o con una macchina simile può essere un’esperienza di apprendimento molto ricca. Non solo ti aiuta a capire meglio come funzionano queste macchine, ma ti dà anche l’opportunità di contribuire a migliorarle. Senza dimenticare che rende anche evidente quanto sia importante conoscere i dati in input e sapere esattamente su quali parametri si basino le valutazioni e gli output della macchina. Senza queste informazioni, infatti, non possiamo aver alcun reale controllo sulle macchine che usiamo.
Questo articolo richiama contenuti da In principio era ChatGPT.
Immagine di apertura di Google DeepMind su Unsplash.
L'autore


Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Libri che potrebbero interessarti
