

Un crescente interesse per i Big Data
Big Data, intelligenza artificiale, data analytics, machine learning, data science, cloud: tutte queste espressioni sono diventate inaspettate protagoniste di articoli, lezioni universitarie, tavole rotonde, libri, seminari accademici, master e – nelle nostre aziende – progetti, meeting, iniziative commerciali e, talvolta, vere e proprie ristrutturazioni organizzative.
Qui sotto è rappresentata l’evoluzione della popolarità di una serie di parole chiave nelle ricerche sul Web effettuate dagli utenti di Google: l’interesse catturato dai Big Data è esploso a partire dal 2011 e solo recentemente viene superato in popolarità da argomenti più specifici, come quello dell’apprendimento automatico (machine learning).
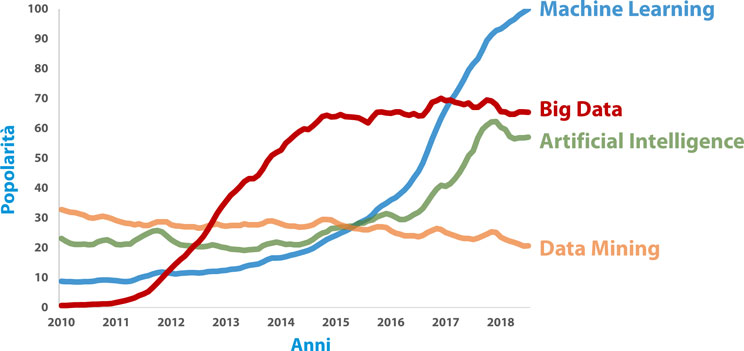
Evoluzione della popolarità di vari termini legati ai Big Data nelle ricerche su Google (trends.google.com).
Dan Ariely, professore di psicologia ed economia comportamentale alla Duke University di Durham, ha colto bene l’improvvisa attenzione al tema proponendo nel 2013 una definizione di Big Data tanto ironica quanto azzeccata:
L’argomento Big Data è come l’argomento sesso per gli adolescenti: tutti ne parlano, nessuno sa davvero come farlo ma tutti pensano che chiunque altro lo stia facendo e, di conseguenza, tutti dichiarano di farlo.
La definizione che utilizzeremo per portare chiarezza sull’argomento è meno divertente, ma più utile:
I Big Data rappresentano una raccolta di dati così estesa in termini di volume, velocità e varietà da richiedere tecnologie e metodi analitici specifici per l’estrazione di valore.
Questa definizione ha il pregio di segnalare attraverso le parole che la compongono le quattro componenti essenziali del concetto di Big Data:
- informazione, in quanto i Big Data sono – essenzialmente – dati, organizzati allo scopo di estrarne il contenuto informativo;
- tecnologia, data l’esigenza di dotarsi di strumenti tecnologici specifici per l’utilizzo di questi dati;
- metodi, visto il bisogno di usare metodologie analitiche particolari per la loro analisi;
- impatto, in quanto i Big Data influiscono sulla nostra vita e sul nostro modo di lavorare, creando o proponendosi di creare del valore.
Informazione
Vengono creati continuamente più dati di quanto siamo in grado di elaborarne. Ogni minuto, 400 ore di nuovi video sono caricati su YouTube e gli utenti di Google effettuano 3 milioni e mezzo di ricerche. Su Facebook arrivano 3 milioni di nuovi like. Sugli smartphone vengono scambiati circa 16 milioni di messaggi tramite WhatsApp, WeChat e altre piattaforme. A questi dati generati dalle persone dobbiamo aggiungere quelli generati dalle macchine.
Negli ultimi anni è esploso, infatti, il numero di dispositivi dotati di sensori che generano e distribuiscono dati in maniera autonoma attraverso una connessione a Internet. Questi creano una vera e propria rete a sé, denominata Internet of Things (IoT, ovvero l’Internet delle cose), la quale trova vaste applicazioni negli ambiti più vari.
Nelle nostre case l’Internet delle cose permette di controllare elettrodomestici, luci e caldaie per ottimizzare l’uso dell’energia. Sulle strade, invece, le automobili connesse contribuiscono a far diminuire gli incidenti e l’illuminazione pubblica è ottimizzata tenendo conto del traffico effettivo. Persone e macchine generano un enorme volume di informazioni, appunto i Big Data.
I quali hanno anche la caratteristica di essere molto vari nel loro formato. Il grosso dei dati postati da miliardi di persone sui social media sono video, foto o testo, nulla a che vedere con le tradizionali basi di dati. Un’ulteriore caratteristica dei Big Data è di essere generati con estrema velocità: i sensori di una singola automobile intelligente, come una Tesla, possono produrre qualcosa come 80 gigabyte di dati al minuto. Ritroviamo quindi con facilità tutte e tre le caratteristiche che rendono big i dati della nostra definizione: alto volume, grande velocità di generazione e varietà di formato.
Tutti gli esempi visti in questo paragrafo si riferiscono a dati generati nel presente. Talvolta, invece, ci si può sorprendere del valore insito nel riorganizzare dati vecchi in modo innovativo. Prendiamo l’esempio del progetto Google Books: a partire dal 2004 Google ha iniziato a digitalizzare i libri conservati nelle più grandi biblioteche del mondo rendendoli, quando possibile, accessibili gratuitamente online attraverso Google Libri.
Su un totale stimato di 130 milioni di titoli diversi esistenti al mondo, più di 25 milioni sono già stati digitalizzati da Google, dalla prima Bibbia a 42 linee di Gutenberg stampata nel 1455 a oggi. Le immagini di ogni pagina sono state convertite in stringhe di testo, permettendo l’analisi globale della presenza relativa di parole in tutti questi libri. Chiunque può comparare la popolarità di parole a scelta usando la pagina web books.google.com/ngrams: le curve nel grafico mostrato nella prossima figura rappresentano, per esempio, l’evoluzione della presenza relativa di patria, razza e successo nei libri scritti in italiano e stampati dal 1840 ai giorni nostri. 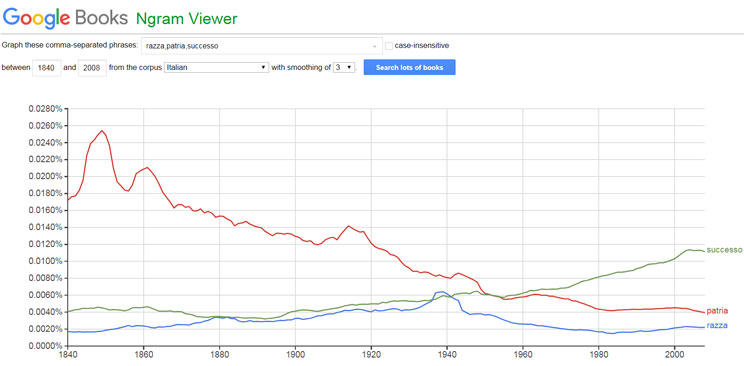
Google Books Ngram Viewer riporta la popolarità relativa dei termini usati nei libri stampati.
Tecnologia
Il fattore scatenante che più di tutti può spiegare il successo esplosivo dei Big Data è la crescita esponenziale della capacità di calcolo, trasferimento e immagazzinamento dei dati, frutto di progressi combinati in varie discipline, soprattutto nell’elettronica digitale, le telecomunicazioni e l’informatica.
- la frequenza di calcolo dei microprocessori continua ad aumentare (i 6 MHz del mitico processore Intel 286, fatto di 134.000 transistor, sono nulla in confronto ai 4.000 MHz degli attuali processori Core i7, che contano miliardi di transistor);
- la capacità delle schede di memoria o delle chiavette USB o la memoria negli smartphone cresce continuamente a parità di costo (dalle decine di megabyte negli anni 2000 ai milioni di megabyte attuali);
- la velocità di Internet nelle case è passata dai 56 kb/s della connessione dial-up analogica degli anni Novanta al milione di kb/s della fibra ottica dei giorni nostri;
- analogamente, la velocità dello scambio dati via cellulare si è spostata dai 64 kb/s del 2G (GSM/GPRS) ai 100.000 kb/s del 4G LTE moderno.
La velocità con cui queste tecnologie si sono evolute ha seguito un ritmo esponenziale e non lineare come siamo abituati a vedere per altre grandezze, come l’inflazione, il prodotto interno lordo o il nostro stipendio, le quali aumentano o diminuiscono di pochi punti percentuali ogni anno. Queste grandezze tecnologiche sono invece state cresciute di diversi zeri nel giro di pochi anni.
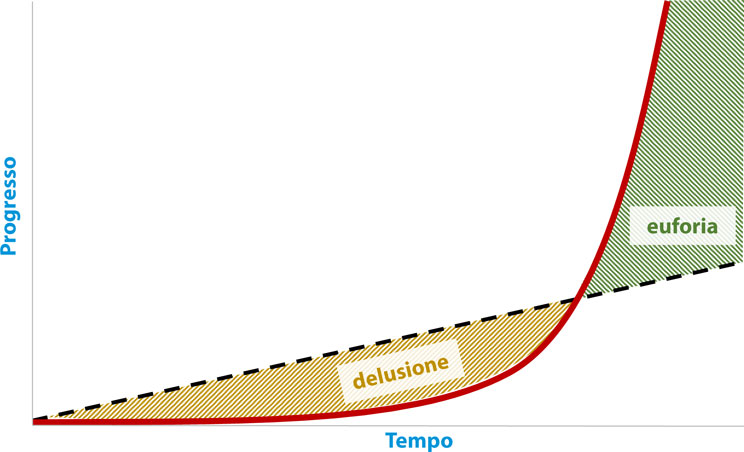
Progressione esponenziale (linea continua in rosso) a confronto con quella lineare (linea tratteggiata in nero). La prima all’improvviso supera di slancio la seconda.
Guardando la figura sopra, osserviamo che la progressione lineare (linea nera tratteggiata) mantiene un vantaggio importante per molto tempo, fase durante la quale si rimane delusi dalla crescita della progressione esponenziale. A un certo punto, la progressione esponenziale supera di improvviso quella lineare e in poco tempo la rende irrilevante, suscitando euforia. I Big Data hanno superato questo punto critico qualche anno fa.
I Big Data hanno inoltre beneficiato degli importanti progressi ottenuti in alcune, specifiche aree tecnologiche: una di queste è il calcolo distribuito (distributed computing). Immaginiamo di dover calcolare nel minor tempo possibile con carta e penna il valore di un’espressione matematica:
1311 ∙ 1749 + 2918 ∙ 1612 + 8329 ∙ 7752 = ?
Se ci sono amici disposti ad aiutarci, ciascuno si occuperà di una operazione e la soluzione arriverà molto più velocemente. Il calcolo distribuito è proprio dividere il lavoro, procedere in parallelo e scambiarsi i risultati intermedi per ottenere quello finale. Diverse infrastrutture informatiche implementano la filosofia del calcolo distribuito per la gestione dei Big Data, come Hadoop.
Un altro aspetto tecnologico del successo dei Big Data è il cloud: un modo molto efficace di scambiare potenza computazionale o spazio di memorizzazione tra organizzazioni diverse. L’esempio tipico è una piccola azienda che ha bisogno di espandere velocemente la propria infrastruttura e, invece di acquistare decine di macchine, si rivolge a fornitori specializzati (provider) i quali le assegnano temporaneamente una parte delle risorse dei propri centri di calcolo connessi online (data center), in cambio di una sorta di canone di affitto. I vantaggi dell’approccio cloud sono evidenti:
- le aziende possono iniziare a beneficiare dei Big Data senza esporsi a investimenti di lungo termine;
- i cloud provider si specializzano nella gestione dei loro grandi data center, creando economie di scala e sinergie;
- si possono regolare velocemente le risorse di elaborazione a disposizione, per ridurle o aggiungerne di nuove in funzione della necessità del momento.
Metodi
Avere tanto carburante (i dati) e un motore potente (la tecnologia) non bastano a vincere la gara: il talento del pilota rimane un ingrediente indispensabile. L’avvento dei Big Data è stato accompagnato dal bisogno di codificare tecniche e metodologie analitiche nuove o affinare quelle già esistenti.
Questi metodi analitici, volti a interpretare ed estrarre conoscenza dai dati, si sono sviluppati in un ambito scientifico fortemente multidisciplinare (un mix di informatica, matematica, statistica e altre discipline) che va sotto il nome di data science, scienza dei dati. Insieme al successo dei Big Data è arrivato anche l’interesse per la data science e per il suo operatore principale: il data scientist.
La figura del data scientist è ancora oggi in grossa ascesa nel mercato del lavoro e le aziende – sia in Italia sia nel mondo – confermano quanto sia difficile trovare persone esperte di data analytics. Il mito del data scientist è stato anche eccessivamente caricato di aspettative, in quanto gli sono richieste competenze molto variegate: statistico, programmatore, ricercatore, esperto di business, responsabile di progetto, specialista di architetture cloud, amministratore di sistema, comunicatore, esperto di privacy eccetera. Nella realtà, le aziende hanno bisogno di un mix di professionalità diverse e complementari tra loro. Analizziamo le quattro famiglie principali di ruoli professionali legati ai Big Data, rappresentate nella prossima figura:
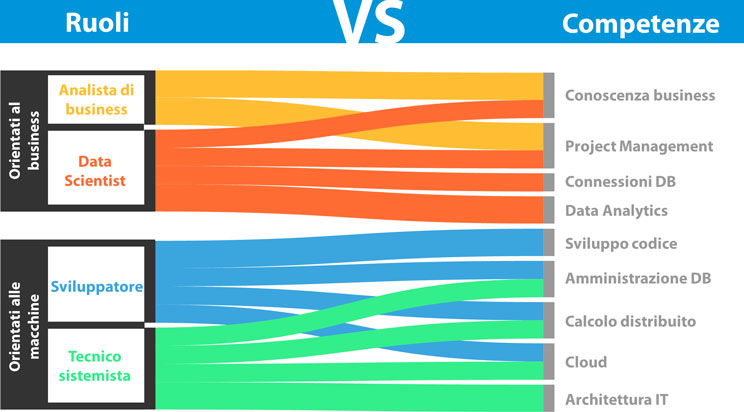
I quattro ruoli fondamentali di Big Data Analytics e relative competenze, da Human resources for Big Data professions: A systematic classification of job roles and required skill sets.
- Analista di business (o business analyst, data analyst): l’interfaccia tra le funzioni aziendali tradizionali (come marketing, vendite, acquisti e così via) e il mondo dei dati.
- Data scientist: identifica i giusti modelli e algoritmi da utilizzare in base all’esigenza e, all’occasione, modifica e riscrive metodi analitici esistenti, se non ne crea da zero.
- Sviluppatore: progetta, sviluppa e gestisce il software applicativo per l’utilizzo dei Big Data in azienda.
- Tecnico sistemista (o data engineer o system engineer): disegna, implementa e mantiene operativa tutta l’infrastruttura tecnologica a supporto della data analytics.
È importante una precisazione: le competenze di data analytics in azienda non possono essere patrimonio esclusivo di data scientist e analisti. Per poter collegare le opportunità dei Big Data alle esigenze di business servirà che tutti in azienda (a partire da chi la dirige) siano in grado di parlare di questi temi e abbiano una certa conoscenza di base di potenzialità e limiti dei vari metodi analitici.
Impatto
Nel mondo del business l’arrivo dei Big Data ha creato una miscela incandescente di euforia e paura. Effettivamente, le scelte relative alla gestione dei dati hanno portato delle semplici start-up a prosperare, mentre alcune floride multinazionali poco attente ai cambiamenti sono fallite nel giro di pochi mesi. È celebre il caso di Blockbuster e Netflix: la prima era l’azienda leader globale del noleggio di film e videogiochi. Nel 2004 contava oltre 84.000 dipendenti e solo sei anni dopo avrebbe dichiarato bancarotta, schiacciata dall’arrivo dell’on-demand streaming di Netflix, un’azienda che al tempo aveva poco più di 2.000 dipendenti ma che con i dati ci sapeva fare.
Settori molto diversi tra loro, da quello finanziario alla produzione industriale, ci offrono numerosi scenari di utilizzo dei Big Data. Le banche, per esempio, li usano per valutare il rischio di concedere credito. Nel settore aeronautico i dati provenienti dai sensori installati sugli aeromobili in volo (un altro esempio di IoT) sono utilizzati per ottimizzare rotte, prevedere guasti e risparmiare carburante.
Diversi studi hanno dimostrato che le aziende più veloci a dotarsi di tecnologie e talenti per utilizzare i Big Data hanno raggiunto un vantaggio competitivo finanziariamente significativo sul bilancio, pari a circa 6 punti percentuale di produttività incrementale in media. Le fonti di valore economico che derivano dallo sfruttamento dei Big Data sono principalmente tre:
- Riduzione dei costi: analizzando i Big Data si possono eliminare sprechi di tempo e materiale.
- Miglioramento delle decisioni: i metodi di data analytics permettono ai dirigenti di prendere scelte migliori e più veloci.
- Miglioramento di prodotto: i Big Data possono migliorare gli stessi prodotti e servizi offerti da un’azienda.
I Big Data hanno influenzato anche il mondo della ricerca scientifica e umanistica. Un esempio fra tutti viene dalla medicina e dalla ricerca contro il cancro: i ricercatori di Google hanno sviluppato una macchina chiamata LYNA (LYmph Node Assistant, o assistente per i linfonodi) in grado di analizzare fotografie di tessuti e di segnalare all’equipe di medici la presenza di metastasi anche molto piccole (nella prossima figura). La performance dei medici nel diagnosticare il cancro con e senza l’aiuto di LYNA passa dall’83 percento al 91 percento e la diagnosi richiede metà del tempo.
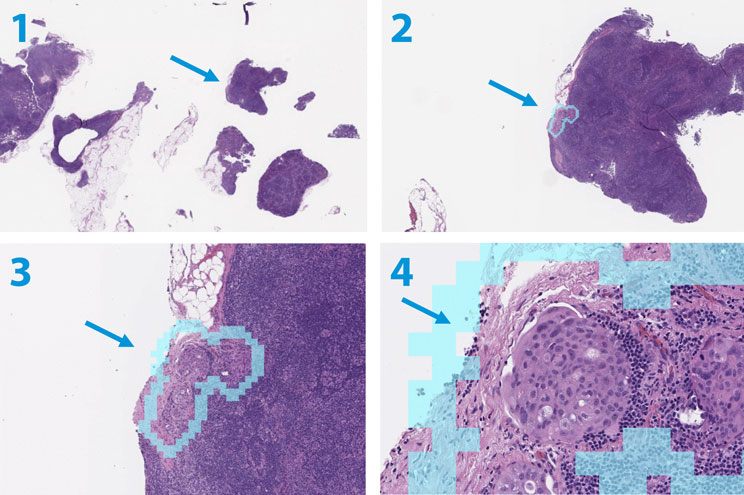
Piccole metastasi di tumore al seno a ingrandimenti progressivi. Le frecce indicano l’assistenza all’interpretazione generata dall’algoritmo di LYNA (da Impact of Deep Learning Assistance on the Histopathologic Review of Lymph Nodes for Metastatic Breast Cancer).
Big Data e privacy
Il mondo dei Big Data genera anche perplessità e legittime apprensioni. Quella più grande è sicuramente legata alla tutela della privacy e alla limitazione delle libertà personali. Un esempio: un ricco database potrebbe contenere una scia di tracce, anche molto dettagliate, lasciate dal comportamento di un individuo. Sebbene l’individuo possa aver accettato di condividere ogni singolo segnale (opt-in), la loro elaborazione collettiva potrebbe svelare schemi inaspettati, legati ad aspetti che la persona potrebbe non essere felice di condividere.
Una storia significativa in questo senso riguarda Target, una catena di ipermercati e supermercati operante negli Stati Uniti. Analizzando lo storico degli acquisti, i data analyst avevano osservato che le donne nelle prime 20 settimane di gravidanza tendevano ad aumentare l’acquisto di alcune tipologie specifiche di prodotti, quali supplementi alimentari, saponi senza profumo, detergenti igienizzanti eccetera. Questo permise l’assegnazione di un punteggio di gravidanza (pregnancy score) proporzionale alla probabilità delle consumatrici di aspettare un bambino. I responsabili del marketing decisero di usare questo punteggio per spedire offerte personalizzate alle donne probabilmente incinte. Qualche mese dopo, un signore visibilmente arrabbiato si presentò a un punto vendita Target di Minneapolis chiedendo di parlare con il direttore. Mostrando i coupon ricevuti, questo cliente esclamò spazientito: Mia figlia ha ricevuto questi buoni sconto per culle e vestiti da neonato. La mia bambina va ancora a scuola: la volete forse incoraggiare a rimanere incinta? Il direttore non poté fare altro che scusarsi profondamente e decise di richiamare a casa il cliente arrabbiato dopo un paio di giorni. Fu sorpreso di ricevere delle scuse dal suo cliente che sembrerebbe avere usato le seguenti parole: Non ero a conoscenza di alcune attività che andavano avanti a casa a mia insaputa. Mia figlia partorirà ad agosto.
Questa vicenda rispecchia la portata dell’impatto che la data analytics può avere sulla storia personale dei singoli individui e, quindi, della necessaria cura da osservare nell’utilizzare i risultati delle analisi.
Dalla teoria alla pratica
Il concetto di Big Data Analytics si è evoluto molto velocemente e ha generato tanti falsi miti, esagerazioni e proclami altisonanti, spesso privi di vero senso pratico. Analizzare il modello ITMI (Informazione, Tecnologia, Metodi, Impatto) pezzo per pezzo ci ha permesso di rimettere un po’ in ordine le idee, preparandoci a un approccio più concreto con la data analytics per chi fosse interessato concretamente all’argomento.
Questo articolo richiama contenuti dal capitolo 1 di Big Data Analytics.
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Corsi che potrebbero interessarti

Big Data Executive: business e strategie

Big Data Analytics - Iniziare Bene

Data governance: diritti, licenze e privacy
Libri che potrebbero interessarti

Big Data Analytics
Analizzare e interpretare dati con il machine learning
Data Science con Python
Dalle stringhe al machine learning, le tecniche essenziali per lavorare sui dati