

Tre modi di apprendere, per una macchina
Esistono tre varietà di machine learning: apprendimento con supervisione, apprendimento senza supervisione e reinforcement learning. Qui conosceremo le differenze fondamentali fra i tre diversi tipi di apprendimento e, impiegando esempi concettuali, svilupperemo una comprensione dei domini di problemi pratici in cui possono essere applicati.

Ci sono tre tipi di machine learning.
Fare predizioni sul futuro tramite l’apprendimento con supervisione
Lo scopo principale nell’apprendimento con supervisione è istruire un modello a partire da dati di addestramento etichettati, il che ci consente di eseguire predizioni su dati che non ha mai visto prima o futuri. Qui, la qualifica con supervisione fa riferimento a un insieme di esempi di addestramento (i dati di input) in cui i segnali di output desiderati (le etichette) sono già noti. La prossima figura riepiloga il tipico flusso di lavoro nell’apprendimento con supervisione, in cui i dati di addestramento etichettati vengono passati a un algoritmo di machine learning per adattare un modello predittivo in grado di effettuare predizioni su dati di input nuovi, senza etichette.
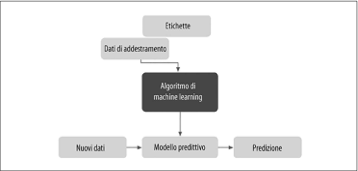
Il tipico flusso di lavoro nell’apprendimento con supervisione.
Considerando l’esempio del filtraggio dei messaggi spam nella posta elettronica, possiamo addestrare un modello impiegando un algoritmo di machine learning con supervisione su un corpus di messaggi di posta elettronica già etichettati, correttamente contrassegnati come spam o non-spam, per predire a quale delle due categorie appartiene un nuovo messaggio. Un compito di apprendimento con supervisione con etichette per classi discrete, come nel precedente esempio di filtraggio dei messaggi spam nella posta elettronica, è chiamato anche compito di classificazione. Un’altra sottocategoria dell’apprendimento con supervisione è la regressione, in cui il segnale risultante è un valore continuo.
Classificazione per predire le etichette delle classi
La classificazione è una sottocategoria dell’apprendimento con supervisione in cui l’obiettivo e predire le etichette delle categorie delle classi per le nuove istanze, sulla base delle precedenti osservazioni. Tali etichette delle classi sono valori discreti e non ordinati, che sanciscono l’appartenenza a un gruppo delle istanze. L’esempio del rilevamento dello spam nella posta elettronica rappresenta un tipico esempio di un compito di classificazione binario, in cui l’algoritmo di machine learning apprende un insieme di regole con lo scopo di distinguere fra due classi possibili: messaggi di posta elettronica spam e non-spam.

La figura seguente illustra il concetto di un compito di classificazione binario sulla base di 30 esempi di addestramento: 15 esempi di addestramento sono etichettati nella classe negativa (i segni meno) e 15 esempi di addestramento sono etichettati nella classe positiva (i segni più). In questo scenario, il nostro dataset è bidimensionale, cioè a ciascun esempio sono associati due valori: x1 e x2. Ora, possiamo impiegare un algoritmo di machine learning con supervisione per apprendere una regola – il confine decisionale rappresentato dalla linea tratteggiata – in grado di separare queste due classi e classificare i nuovi dati in ognuna di queste due categorie sulla base dei loro valori x1 e x2.
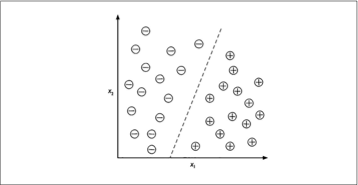
Un compito di classificazione binaria.
Tuttavia,l’insieme delle etichette delle classi non deve necessariamente avere una natura binaria. Il modello predittivo appreso da un algoritmo di apprendimento con supervisione può assegnare una nuova istanza, senza etichetta, una qualsiasi etichetta di classe, conosciuta tramite il dataset di addestramento.
Un tipico esempio di compito di classificazione multi-classe è il riconoscimento dei caratteri scritti a mano. Possiamo raccogliere un dataset di addestramento costituito da più esempi di scrittura a mano di ogni lettera dell’alfabeto. Le lettere (“A”, “B”, “C” e così via) rappresenteranno le varie categorie non ordinate o etichette delle classi che vogliamo predire. Ora, se un utente fornisce un nuovo carattere scritto a mano tramite un dispositivo di input, il nostro modello predittivo sarà in grado di predire la lettera corretta con una certa accuratezza. Tuttavia, il nostro sistema di machine learning non riconoscerà correttamente le varie cifre fra 0 e 9, per esempio, se esse non facevano parte del dataset di addestramento.
Regressione per predire risultati continui
Il compito della classificazione consiste nell’assegnare alle istanze delle etichette di tipo categorico, non ordinate. Un secondo tipo di apprendimento con supervisione è la predizione di risultati continui, un compito chiamato anche analisi a regressione. Nell’analisi a regressione, abbiamo un certo numero di variabili predittrici (descrittive) e una variabile di risposta continua (il risultato) e tentiamo di trovare una relazione fra tali variabili che ci consenta di predire un risultato. Notiamo che nel campo del machine learning, le variabili predittrici sono comunemente chiamate feature, caratteristiche, e le variabili di risposta sono normalmente chiamate variabili target.
Per esempio, supponiamo di essere interessati a predire i punteggi nei test attitudinali di matematica degli studenti. Se esiste una relazione fra il tempo dedicato a studiare per il test e i punteggi finali, possiamo impiegarla come dati di addestramento per istruire un modello che impieghi il tempo di studio per predire i punteggi nei test dei futuri studenti.
(Il termine regressione è stato coniato da Francis Galton nel suo articolo Regression Towards Mediocrity in Hereditary Stature, scritto nel 1886. Galton descrisse il fenomeno biologico in base al quale la varianza della statura in una popolazione non aumenta nel corso del tempo e osservò che la statura dei genitori non viene trasmessa ai loro figli, ma piuttosto che la statura dei figli regredisce verso la media della popolazione).
La figura qui sotto illustra il concetto della regressione lineare. Data una variabile delle caratteristiche x e una variabile target y, tracciamo una linea retta attraverso questi dati tale che minimizzi la distanza – più comunemente la distanza quadratica media – fra i punti dei dati e la linea stessa. A questo punto possiamo impiegare il punto di intersezione e la pendenza appresi da questi dati per predire la variabile target dei nuovi dati.
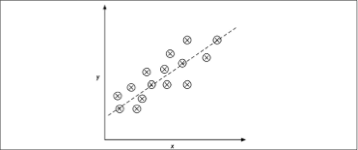
Rappresentazione di regressione lineare.
Risolvere problemi interattivi con il reinforcement learning
Un altro tipo di machine learning è il reinforcement learning. Qui l’obiettivo è sviluppare un sistema (agente) che migliora le proprie prestazioni sulla base di interazioni con l’ambiente. Poiché le informazioni sullo stato corrente dell’ambiente in genere includono anche un cosiddetto segnale di ricompensa (reward), possiamo considerare il reinforcement learning come un campo correlato all’apprendimento con supervisione.
Tuttavia, nel reinforcement learning, questo feedback non è l’etichetta o il valore di verità, bensì una misura della qualità con cui l’azione è stata misurata dalla funzione di ricompensa. Tramite le sue interazioni con l’ambiente, un agente può poi impiegare il reinforcement learning per apprendere una serie di azioni che massimizzano questa ricompensa tramite un approccio esplorativo, di tipo trial-and-error, o tramite una pianificazione deliberativa.
Un esempio classico di reinforcement learning è il motore per il gioco degli scacchi. Qui, l’agente decide fra una serie di mosse a seconda dello stato della scacchiera (l’ambiente) e la ricompensa può essere definita come vittoria o sconfitta alla fine del gioco (in figura).
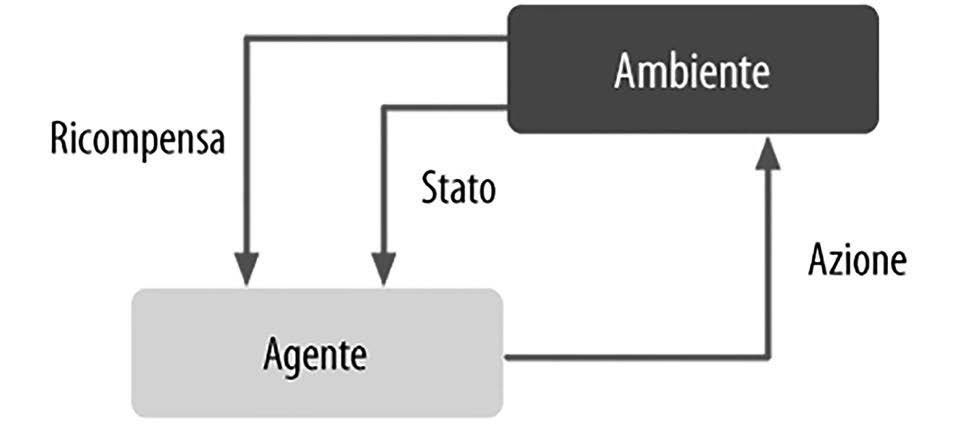
Come funziona il reinforcement learning.
Vi sono molti e diversi sottotipi di reinforcement learning. Tuttavia, uno schema generale è che nel reinforcement learning l’agente tenta di massimizzare la ricompensa attraverso una serie di interazioni con l’ambiente. A ogni stato può essere associata una ricompensa positiva o negativa e una ricompensa può essere definita come quella che consegue un obiettivo generale, come vincere o perdere una partita di scacchi.
Per esempio, negli scacchi, il risultato di ogni mossa può essere considerato come un diverso stato dell’ambiente. Immaginiamo di considerare alcune configurazioni della scacchiera associandole a stati che hanno maggiori probabilità di condurre a una vittoria – per esempio, il fatto di mangiare un pezzo avversario o di minacciare la regina.
Altre posizioni, al contrario, sono associate a stati che porteranno probabilmente a perdere la partita, come farsi mangiare un pezzo. Ora, nel gioco degli scacchi, la ricompensa (positiva per la vittoria o negativa per la sconfitta) non si riceverà se non alla fine della partita. Inoltre, la ricompensa finale dipenderà anche da come gioca l’avversario. Per esempio, l’avversario potrebbe sacrificare la regina, ma finire per vincere la partita.
Il reinforcement learning si preoccupa di imparare a scegliere una serie di azioni che massimizza la ricompensa totale, che può essere guadagnata o immediatamente dopo aver intrapreso un’azione o tramite un feedback ritardato.
Individuare strutture nascoste con l’apprendimento senza supervisione
Nell’apprendimento con supervisione, conosciamo la risposta corretta in anticipo quando addestriamo un modello e nel reinforcement learning definiamo una misura di ricompensa per determinate azioni svolte dall’agente. Nell’apprendimento senza supervisione, al contrario, abbiamo a che fare con dati senza etichetta o dati dalla struttura ignota. Impiegando tecniche di apprendimento senza supervisione, siamo in grado di esplorare la struttura dei nostri dati per estrarre informazioni utili senza la guida di una variabile risultante nota o di una funzione di ricompensa.
Ricercare sottogruppi con il clustering
Il clustering è una tecnica di analisi esplorativa dei dati che ci consente di organizzare una massa di informazioni in sottogruppi significativi (cluster) senza alcuna precedente conoscenza delle loro appartenenze a gruppi.
Ciascun cluster che emerge durante l’analisi definisce un gruppo di oggetti che condividono un certo livello di similarità, ma sono più differenti dagli oggetti di altri cluster, motivo per cui il clustering viene talvolta chiamato classificazione senza supervisione.
Il clustering è un’ottima tecnica per strutturare le informazioni e per trarre dai dati relazioni significative. Per esempio,consente a coloro che lavorano nel marketing di individuare gruppi di consumatori sulla base dei loro interessi, con lo scopo di sviluppare specifiche campagne di marketing.
La prossima figura illustra il modo in cui il clustering può essere applicato all’organizzazione dei dati senza etichetta in tre diversi gruppi sulla base della similarità delle loro caratteristiche, x1 e x2.
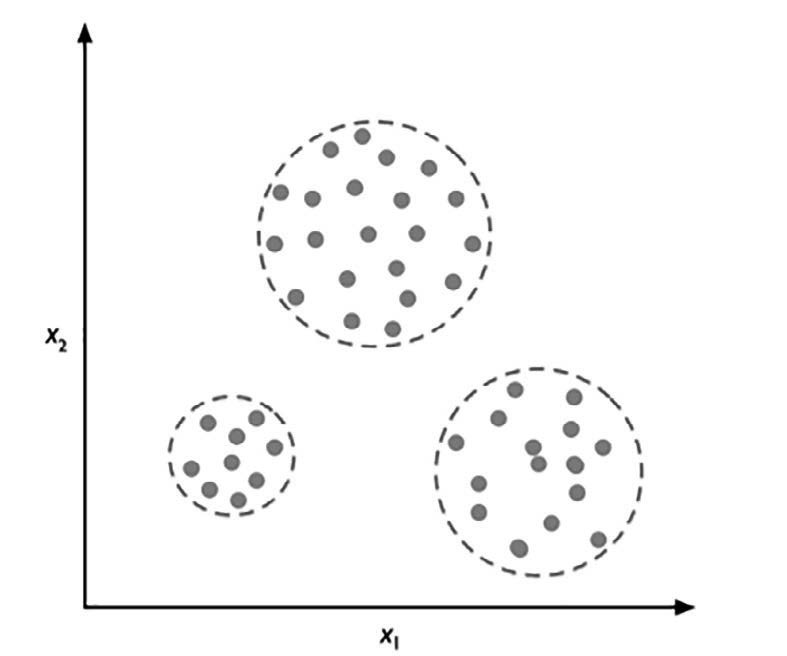
Clustering applicato all'organizzazione dei dati senza etichetta.
Ridurre la dimensionalità per comprimere i dati
Un altro sottocampo dell’apprendimento senza supervisione è la riduzione della dimensionalità. Spesso ci capita di lavorare con dati di elevata dimensionalità – ogni osservazione fornisce un numero elevato di misurazioni – il che può rappresentare una sfida in termini di spazio di memorizzazione e prestazioni computazionali per gli algoritmi di machine learning.
La riduzione della dimensionalità senza supervisione è un approccio comunemente usato nella preelaborazione delle caratteristiche, con lo scopo di eliminare il rumore dai dati, capace di degradare le prestazioni predittive di determinati algoritmi, e di comprimere i dati in un sottospazio a dimensionalità inferiore, mantenendo nel contempo la maggior parte delle informazioni rilevanti.
Talvolta, la riduzione della dimensionalità può essere utile anche per la visualizzazione dei dati; per esempio, un insieme di caratteristiche a elevata dimensionalità può essere proiettato su spazi di caratteristiche mono-, bi- o tridimensionali, con lo scopo di visualizzarlo tramite grafici a dispersione o istogrammi bi- o tridimensionali. La figura conclusiva mostra un esempio in cui è stata applicata una riduzione non lineare della dimensionalità per comprimere una sorta di rotella in un nuovo sottospazio delle caratteristiche di natura bidimensionale.

Esempio di riduzione non lineare della dimensionalità.
Questo articolo richiama contenuti dal capitolo 1 di Machine Learning con Python – nuova edizione.
Immagine di apertura di David Levêque su Unsplash.
L'autore


Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Corsi che potrebbero interessarti

Machine Learning & Big Data per tutti

Big Data Analytics - Iniziare Bene

Facebook e Instagram: la pubblicità che funziona