
PROMOZIONE
Lavori con dati e software?
Vuoi essere sicuro di fare le scelte giuste?
Ci sono 4 corsi per te, scoprili e con il codice DATAX50 risparmi 50€ sull’iscrizione a: Big Data Executive, Big Data Analytics, Data governance, Strategie e modelli contrattuali per cedere e acquisire software.
Come avviene a ogni tornata elettorale, anche in occasione delle ultime elezioni ci siamo trovati a fare i conti con exit poll e proiezioni. Allo scoccare della chiusura delle urne la curiosità è davvero troppa: malgrado l’ora ci ritroviamo incollati davanti al televisore per ottenere un’anticipazione e guardare in faccia il politico di turno nella scomoda situazione di essere incalzato a commentare un risultato ancora in divenire. Ma come funzionano exit poll e proiezioni? Come possono andare storte? E, soprattutto, che c’azzecca il coronavirus?
Partiamo dagli exit poll. L’idea è semplice: per anticipare un risultato elettorale chiediamo a un gruppo di persone (il campione) di condividere le loro intenzioni di voto. Una volta ottenuti i risultati, presumiamo che questi rappresentino, con un certo grado di approssimazione (il margine di errore) i risultati che ci consegneranno le urne. La statistica ci aiuta a stimare l’intervallo atteso di errore e quindi a farci un’idea di quanto possiamo sbagliare.
Ammettiamo di voler stimare il consenso raccolto da ciascuno dei due candidati in lizza. Guardiamo la prossima figura: all’aumentare della grandezza del campione, ovvero del numero di persone intervistate durante l’exit poll, il margine di errore (con una confidenza al 95 percento) si assottiglia. Questo potrebbe indurci a pensare che, avendo il giusto numero di intervistati (ipotizziamo di averne circa 2.400), potremmo essere verosimilmente certi del risultato con un margine di due punti percentuali.
È qui che il gioco si fa più complesso di quello che sembra e interviene uno dei più acerrimi nemici dei sondaggisti: il sampling bias (o distorsione da campionamento o da selezione). Il margine di errore che ritroviamo nel grafico presuppone, infatti, che le persone intervistate siano buoni rappresentanti della popolazione completa dei votanti e che la loro selezione casuale avvenga in maniera bilanciata tra i sostenitori delle due fazioni. Come si può immaginare, questo è davvero difficile da ottenere in realtà.
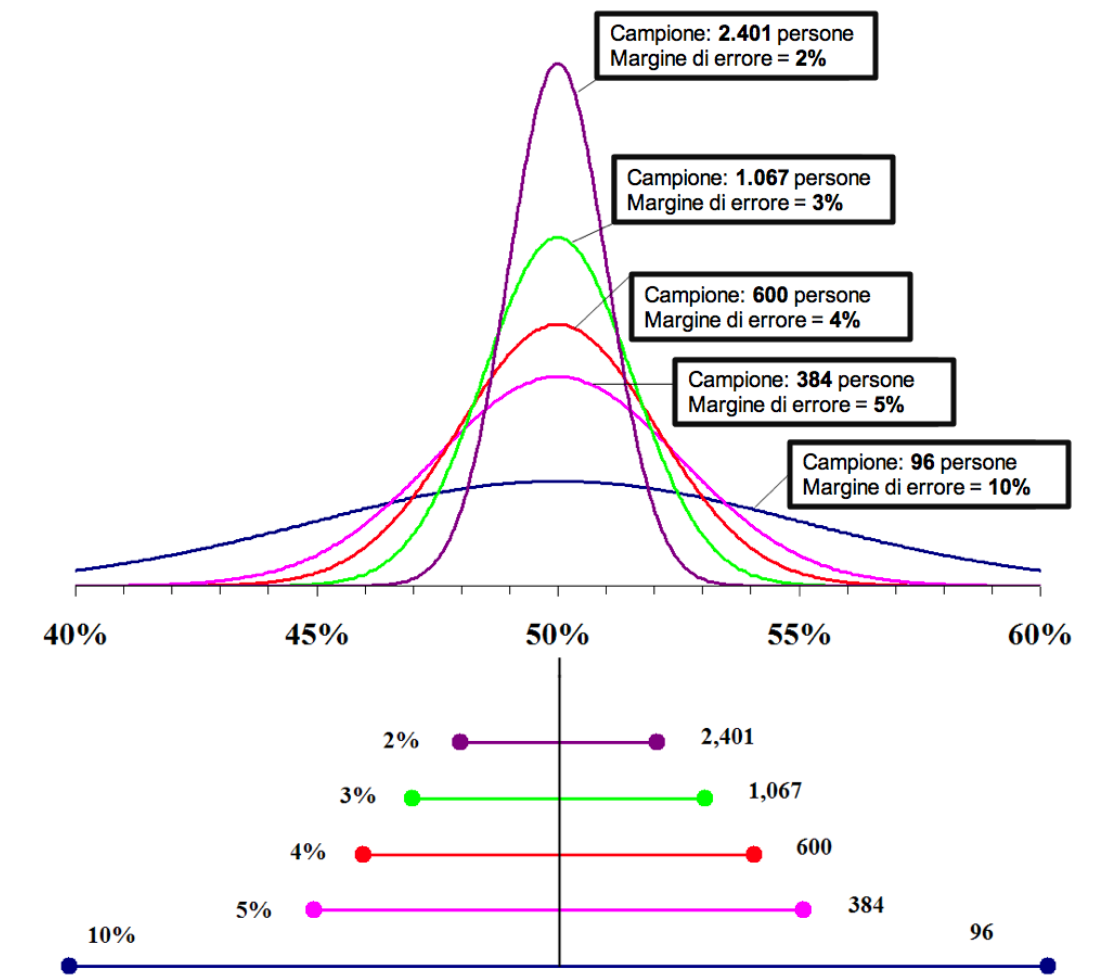
Il margine di errore diminuisce all’aumentare del numero di casi campionati. Questi numeri si riferiscono a un livello di confidenza del 95 percento. Ad esempio, possiamo affermare che nel 95 percento dei casi, intervistando 600 persone, il nostro errore sarà inferiore al 4 percento.
Come già evidenziato in precedenza, gli exit poll possono risultare poco attendibili a causa del sampling bias. Ad esempio, effettuando i nostri sondaggi pre-elettorali via telefono fisso (come spesso – ahinoi – avviene), stiamo introducendo quasi sicuramente un bias in quanto i sostenitori di una data fazione possono essere meno propensi ad utilizzare il telefono fisso.
Sembra che sia successo proprio questo nel 2013, quando il balzo al 25 percento del Movimento 5 Stelle è stato ignorato da molti sondaggi avvenuti tramite telefonate sulla linea fissa: come osservato da Piergiorgio Corbetta dell’Istituto Cattaneo, molti giovani, che sono una parte importante dell’elettorato di Grillo, usano solo il cellulare!
Non era la prima volta e non è stata l’ultima. Celebre è il caso delle elezioni presidenziali statunitensi del 1948: i sondaggi davano Dewey per vincitore fino all’ultimo minuto, tanto che il Chicago Tribune aveva già messo in stampa una prima pagina con il famoso titolo Dewey Defeats Truman. Una volta sancita la sua vittoria, Truman avrebbe orgogliosamente mostrato la prima pagina con la profezia sbagliata: la scena è stata catturata in una celebre foto.

Il neopresidente Truman mostra con soddisfazione la copertina del Chicago Tribune che lo dava (erroneamente) per spacciato.
Dopo gli exit poll arrivano le prime proiezioni, questa volta basata sullo spoglio effettivo di un numero limitato di seggi. Man mano che il Viminale o gli uffici elettorali locali ricevono i primi risultati, questi vengono presi come campioni da cui proiettare il risultato totale. Anche in questo caso, più grande è il campione (più seggi diventano disponibili) più piccolo sarà il margine di errore.
E anche in questo caso, il nostro scellerato sampling bias ci metterà del suo a complicare le cose: le prime sezioni scrutinate potranno essere concentrate in aree che non rispecchiano la totalità della popolazione. Se ad esempio ricevessimo per prime le sezioni cittadine (magari meglio organizzate per lo spoglio e la comunicazione dei risultati) e per ultime quelle suburbane, le prime proiezioni potrebbero ignorare il malcontento della provincia che ha portato un particolare partito a fare incetta di consenso fuori dalle grandi città.
Per completezza va detto che gli istituti che si occupano di effettuare le proiezioni elettorali tengono conto ovviamente del possibile bias introdotto dalla selezione delle sezioni scrutinate. Ma questo processo di neutralizzazione della distorsione statistica è anch’esso basato su assunzioni predefinite e, quindi, suscettibile a errore.
Sampling bias e coronavirus
Nel mese di dicembre del 2019 è emersa una serie sospetta di casi di polmonite nella città di Wuhan, nella Cina centrale. Dopo qualche settimana sarebbe stata accertata l’origine virale di queste polmoniti e localizzata un’area circoscritta nella quale il virus si sarebbe diffuso nei primi giorni dell’epidemia: il mercato cittadino del pesce (vedi figura). Al nuovo virus è stato presto dato un nome: nuovo coronavirus del 2019 (2019 novel coronavirus, o 2019-nCoV). Nel momento in cui scrivo quest’articolo purtroppo la sua diffusione è ancora in atto, destando notevoli preoccupazioni in tutto il mondo.
I numeri disponibili al 22 gennaio del 2020 presso l’ospedale di Wuhan non erano certo incoraggianti: dei primi 41 pazienti diagnosticati con il nuovo coronavirus, 28 (ovvero il 68%) erano stati rilasciati mentre 6 (il 15%) erano deceduti. Fortunatamente il tasso di mortalità del 15% non era rappresentativo di tutta la popolazione di persone affette dalla malattia. Anche in questo caso il sampling bias c’ha messo del suo.
In effetti, la stima della mortalità è davvero difficile da effettuare all’inizio di un’epidemia. Ad esempio, i pazienti che arrivano in ospedale per una sospetta polmonite saranno quelli più preoccupanti, perché già debilitati da patologie pregresse (nel caso di Wuhan, il 32 percento dei primi 41 casi era affetto da diabete, ipertensione o altre condizioni cardiovascolari croniche). Questo è un caso tipico di sampling bias: basare la stima del tasso di mortalità proiettando i primi casi documentati tenderà ad ignorare erroneamente quel gran numero di pazienti meno deboli che, inconsapevoli della novità del virus che li ha infettati, si cureranno a casa e guariranno senza complicazioni.

Le prime 41 ammissioni ospedaliere di pazienti affetti dal coronavirus. La porzione di barra arancione rappresenta i pazienti che hanno avuto contatto diretto con il mercato del pesce di Huanan. Fonte: Huang, Chaolin, et al. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. The Lancet (2020).
Insomma, il sampling bias è un fenomeno tanto frequente quanto beatamente ignorato per ragioni di superficialità o di opportunismo giornalistico. Alcune affermazioni farebbero infatti meno notizia se fossero accompagnate dalle giuste avvertenze. L’importante è saperlo: lettore avvisato, lettore (parzialmente) salvato!
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Corsi che potrebbero interessarti

Big Data Analytics - Iniziare Bene

Big Data Executive: business e strategie

Data governance: diritti, licenze e privacy
Libri che potrebbero interessarti

Big Data Analytics
Analizzare e interpretare dati con il machine learning
Data Science
Guida ai principi e alle tecniche base della scienza dei dati