

Intelligenza artificiale, machine learning e deep learning
Innanzitutto, dobbiamo definire con precisione di che cosa stiamo parlando. Che cosa sono l’intelligenza artificiale, il machine learning e il deep learning? In che relazione si trovano fra loro?
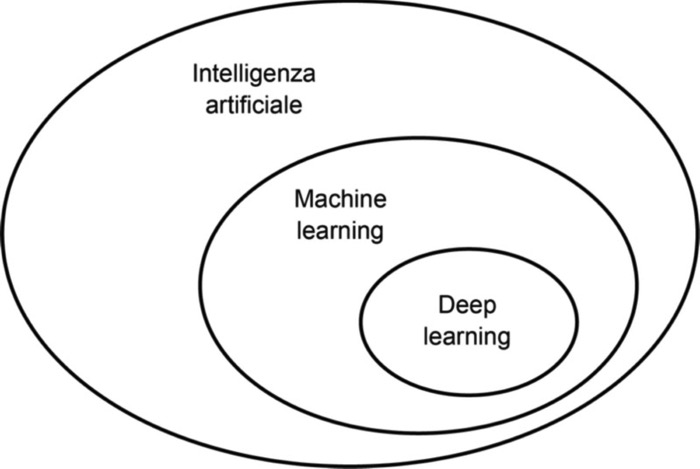
Intelligenza artificiale, machine learning e deep learning.
L’intelligenza artificiale
L’intelligenza artificiale è nata negli anni Cinquanta e una sua definizione sintetica potrebbe essere la seguente: il tentativo di automatizzare i compiti intellettivi normalmente svolti da esseri umani. Pertanto, l’intelligenza artificiale è un campo generale che comprende il machine learning e il deep learning, ma include anche molti altri approcci che non coinvolgono alcun apprendimento. I primi programmi di scacchi, per esempio, prevedevano solo regole codificate a mano dai programmatori, e non rientravano nel machine learning.
Per molto tempo, molti esperti hanno creduto che un’intelligenza artificiale di livello umano potesse essere conseguita facendo in modo che i programmatori predisponessero una quantità di regole esplicite sufficientemente ampia per manipolare la conoscenza. Questo approccio è chiamato intelligenza artificiale simbolica e, sebbene si sia dimostrato adatto per risolvere problemi ben definiti, logici, come il gioco degli scacchi, le regole esplicite si sono rivelate ingestibili per risolvere problemi più complessi, confusi, come la classificazione delle immagini, il riconoscimento vocale e la traduzione da una lingua all’altra. Nacque così un nuovo approccio per prendere il posto dell’intelligenza artificiale simbolica: il machine learning.
Il machine learning
Nell’Inghilterra vittoriana, Lady Ada Lovelace era amica e collaboratrice di Charles Babbage, inventore della Macchina analitica: il primo computer meccanico general-purpose. Sebbene visionaria, la Macchina analitica era stata concepita solo come un modo per utilizzare delle operazioni meccaniche per automatizzare determinati calcoli nel campo dell’analisi matematica. Proprio da ciò trasse il proprio nome. Nel 1843, Ada Lovelace descrisse così l’invenzione:
La Macchina analitica non ha la pretesa di inventare qualcosa di nuovo. Può fare tutto ciò che possiamo ordinarle di fare… La sua capacità è quella di aiutarci a rendere prontamente disponibile ciò che già conosciamo.
Il machine learning deriva da questa domanda: può un computer andare oltre tutto ciò che possiamo ordinargli di fare e imparare da solo a svolgere un determinato compito? Un computer può sorprenderci? Invece di avere programmatori che scrivono accuratamente e manualmente un insieme di regole di elaborazione dei dati, può un computer apprendere automaticamente queste regole semplicemente osservando i dati?
Questa domanda apre la strada a un nuovo paradigma di programmazione. Nella programmazione classica, sulla quale si basa l’intelligenza artificiale simbolica, gli esseri umani inseriscono delle regole (il programma) e i dati da elaborare in base a queste regole, e ne ottengono delle risposte. Con il machine learning, gli esseri umani inseriscono dei dati e le risposte attese in base a questi dati, e il computer individua le regole. Queste regole possono poi essere applicate ad altri dati per produrre altre risposte, originali.
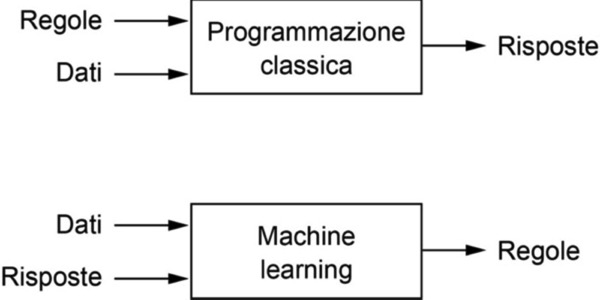
Machine learning: un nuovo paradigma di programmazione.
Un sistema di machine learning viene addestrato e non programmato. Gli vengono sottoposti numerosi esempi rilevanti per un determinato compito, e trova in questi esempi una struttura statistica che alla fine consente di produrre le regole per l’automazione del compito. Per esempio, per automatizzare il compito di applicare tag alle fotografie delle vacanze, si potrebbero presentare a un sistema di machine learning molti esempi di immagini già dotate di tag applicati da umani, e il sistema avrebbe il compito di imparare le regole statistiche in base alle quali associare determinate immagini a specifici tag.
Il machine learning è strettamente legato alla statistica, ma ne differisce per molti e importanti aspetti. A differenza della statistica, il machine learning tende a operare con dataset grandi e complessi (come un dataset di milioni di immagini, ognuna costituita da decine di migliaia di pixel) per i quali l’analisi statistica classica come l’analisi bayesiana non sarebbe utilizzabile. Di conseguenza, il machine learning, e in particolar modo il deep learning, esibisce una teoria matematica piuttosto limitata – a volte anche troppo – ed è un procedimento più tecnico che matematico. Si tratta di una disciplina pratica in cui le idee spesso si dimostrano in modo più empirico che teorico.
Apprendimento dalle rappresentazioni dei dati
Per comprendere la differenza fra deep learning e altri approcci di machine learning, dobbiamo innanzitutto chiarire che cosa fanno gli algoritmi di machine learning. Come abbiamo detto, il machine learning individua le regole da applicare per svolgere un compito di elaborazione di dati, sulla base di esempi di ciò che ci si aspetta. Pertanto, per fare machine learning, abbiamo bisogno di tre cose.
- Un input, rappresentato da punti di dati. Per esempio, se il compito è il riconoscimento vocale, questi punti di dati possono essere file audio di parlato umano. Se il compito è l’applicazione di tag alle immagini, si tratterà di immagini.
- Esempi dell’output atteso. In un compito di riconoscimento vocale, può trattarsi di trascrizioni dei file audio, generate da esseri umani. In un compito di applicazione di tag alle immagini, gli output attesi potrebbero essere tag come cane, gatto e così via.
- Un modo per valutare se l’algoritmo sta facendo un buon lavoro. Questo è necessario per determinare la distanza fra l’output attuale dell’algoritmo e l’output atteso. La valutazione viene poi impiegata come segnale di feedback per regolare il funzionamento dell’algoritmo. Questo passo di regolazione è proprio la parte di apprendimento (learning) del deep learning.
Un modello di machine learning trasforma i suoi dati di input in output significativi, un processo che viene appreso tramite l’esposizione a esempi noti di input e output. Pertanto, il problema centrale del machine learning e del deep learning consiste nel trasformare i dati in modo sensato: in altre parole, imparare a usare rappresentazioni utili dei dati di input disponibili, rappresentazioni che ci portano sempre più vicini all’output atteso. Prima di procedere: che cos’è una rappresentazione?
>Fondamentalmente, si tratta di un modo differente di osservare i dati, di rappresentare o codificare i dati. Per esempio, un’immagine a colori può essere codificata in formato RGB (red-green-blue) o in formato HSV (hue-saturation-value): si tratta di due diverse rappresentazioni degli stessi dati.
Alcuni compiti che risultano difficili impiegando una determinata rappresentazione possono diventare facili impiegandone un’altra. Per esempio, il compito seleziona tutti i pixel rossi dell’immagine è più semplice nel formato RGB, mentre il compito rendi meno satura l’immagine è più semplice nel formato HSV. I modelli di machine learning hanno proprio lo scopo di trovare le rappresentazioni appropriate dei dati di input: quelle trasformazioni dei dati che li rendono più adatti al compito da svolgere, per esempio un compito di classificazione.
Cerchiamo di essere più concreti. Consideriamo un asse x, un asse y e alcuni punti rappresentati dalle loro coordinate nel sistema (x, y), come è rappresentato in questa figura.
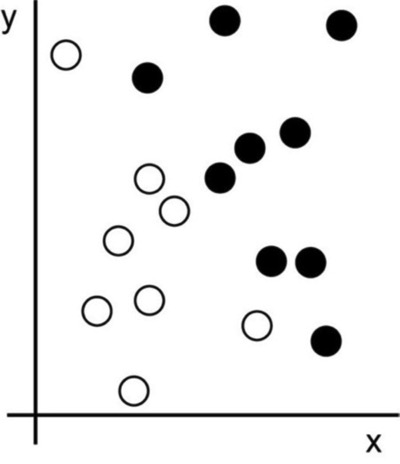
I dati dell’esempio.
Come si vede, abbiamo alcuni punti bianchi e alcuni punti neri. Supponiamo di voler sviluppare un algoritmo in grado di prendere le coordinate (x, y) di un punto e produrre in output il fatto che tale punto abbia maggiori probabilità di essere nero o bianco. In questo caso:
- gli input sono le coordinate dei nostri punti;
- gli output attesi sono i colori dei nostri punti;
- un modo per valutare se il nostro algoritmo sta svolgendo bene il suo lavoro consiste, per esempio, nel considerare la percentuale di punti classificati correttamente.
Ciò di cui abbiamo bisogno, qui, è una nuova rappresentazione dei nostri dati che separi nettamente i punti bianchi dai punti neri. Una trasformazione che potremmo usare, fra le tante altre possibilità, sarebbe un cambio di coordinate, come illustrato qui sotto.
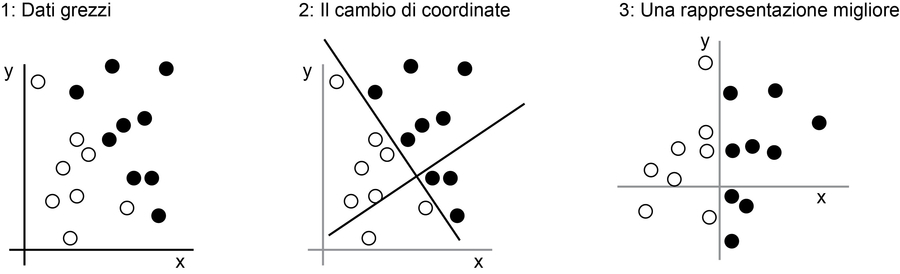
Un cambio di coordinate.
In questo nuovo sistema di riferimento, le coordinate dei nostri punti sono a tutti gli effetti una nuova rappresentazione dei nostri dati. Una rappresentazione ottima! Con questa rappresentazione, il problema di classificazione bianco/nero può essere espresso con una semplice regola: I punti neri sono quelli tali per cui x > 0 oppure I punti bianchi sono quelli tali per cui x < 0. Questa nuova rappresentazione risolve, sostanzialmente, il problema di classificazione.
In questo caso, abbiamo definito a mano il cambio di coordinate. Ma se invece avessimo tentato di cercare sistematicamente tanti possibili cambi di coordinate, e se avessimo usato come feedback la percentuale di punti classificati correttamente, avremmo fatto del machine learning.
Tutti gli algoritmi di machine learning hanno lo scopo di ricercare automaticamente tali trasformazioni che fanno sì che i dati si trovino in una rappresentazione più utile per svolgere un determinato compito. Queste operazioni possono essere cambi di coordinate, come abbiamo appena visto, o proiezioni lineari (che possono distruggere le informazioni), traslazioni, operazioni non lineari (come “Seleziona tutti i punti tali per cui x > 0”) e così via. Gli algoritmi di machine learning non sono particolarmente creativi nella ricerca di queste trasformazioni; svolgono la ricerca tramite un insieme predefinito di operazioni, chiamate collettivamente spazio delle ipotesi.
Ora sappiamo che cosa intendiamo per apprendimento, learning, dunque vediamo che cos’ha di speciale la sua versione profonda: il deep learning.
Che cosa rende deep il deep learning
Il deep learning è una specifica sotto-branca del machine learning: un nuovo livello in tema di apprendimento delle rappresentazioni dai dati che pone l’accento sull’individuazione di layer successivi, con rappresentazioni sempre più significative. La qualifica deep nel deep learning non fa riferimento tanto a una comprensione più profonda che è possibile raggiungere con questo approccio; piuttosto, si basa sull’idea di raffinare layer (livelli) sempre più profondi nelle rappresentazioni. Il numero di layer che contribuiscono a formare un modello dei dati è quindi detto “profondità” (depth) del modello.
Attualmente il deep learning prevede spesso decine o perfino centinaia di layer successivi di rappresentazioni – e tutti vengono appresi automaticamente dall’esposizione ai dati di addestramento. Altri approcci al machine learning tendono a concentrarsi sull’apprendimento in base a solo uno o due layer di rappresentazione dei dati; in questo caso si parla, talvolta, di shallow learning, apprendimento superficiale.
Nel deep learning, queste rappresentazioni a layer sono apprese (quasi sempre) tramite modelli chiamati reti neurali, strutturate attraverso layer sovrapposti l’uno all’altro, come strati. Il termine rete neurale fa riferimento alla neurobiologia, ma sebbene alcuni dei concetti di base del deep learning siano stati in parte sviluppati traendo ispirazione dalla nostra comprensione del funzionamento del cervello umano, i modelli di deep learning non sono modelli del cervello.
Ma che aspetto hanno le rappresentazioni apprese da un algoritmo di deep learning? Vediamo come una rete della profondità di alcuni layer (nella prossima figura) trasforma l’immagine di una cifra per cercare di riconoscerla.
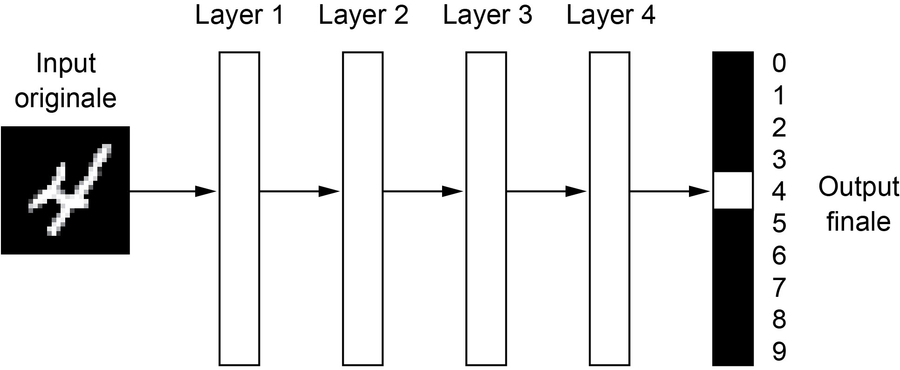
Una rete neurale profonda per la classificazione di una cifra.
La rete trasforma l’immagine della cifra in rappresentazioni sempre più differenti dall’immagine originale e sempre più informative sul risultato finale. Si può pensare a una rete profonda come a un’operazione di derivazione multi-fase delle informazioni: l’informazione attraversa sempre più filtri e ne esce sempre più purificata (ovvero utile a servire un determinato compito).
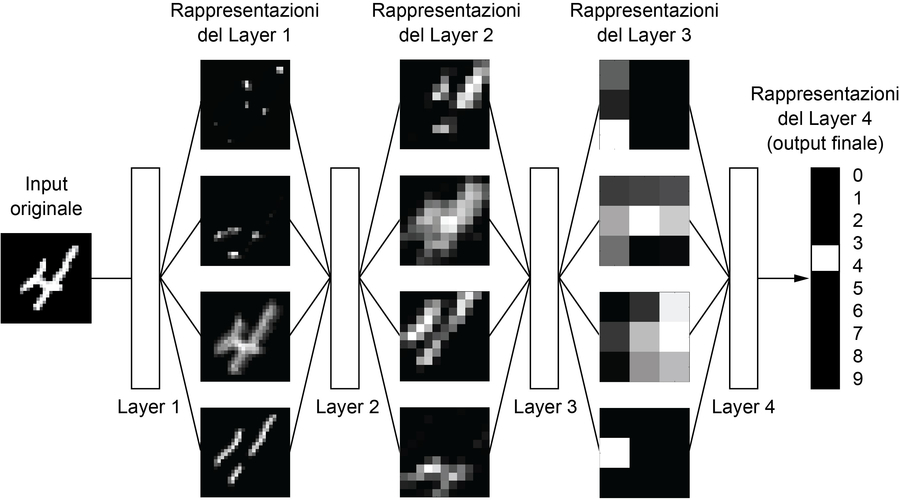
Rappresentazioni profonde apprese in base a un modello di classificazione per cifre.
Tre figure per comprendere come funziona il deep learning
Sappiamo che il machine learning si occupa della mappatura degli input (per esempio immagini) su target (per esempio l’etichetta gatto), svolto osservando molti esempi di input e target. Sappiamo anche che le reti neurali profonde svolgono questa mappatura input-target tramite una profonda sequenza di semplici trasformazioni dei dati (layer) e che queste trasformazioni vengono apprese tramite l’esposizione a esempi. Ora vediamo, più concretamente, come si verifica questo processo di apprendimento.
Le specifiche di ciò che un layer fa ai suoi dati di input sono conservate nei pesi (weight) del layer stesso, i quali sono in pratica una manciata di numeri. In termini tecnici, diciamo che la trasformazione implementata da un layer è parametrizzata dai suoi pesi.
In questo contesto, il termine learning rimanda al cercare un insieme di valori per i pesi di tutti i layer di una rete, tali per cui la rete sia in grado di mappare correttamente gli input ai rispettivi target. Ma qui sorge il problema: una rete neurale profonda può contenere decine di milioni di parametri. Trovare il valore corretto per ognuno di essi può sembrare un compito arduo, specialmente per il fatto che ogni modifica al valore di un parametro influenzerà il comportamento di tutti gli altri!
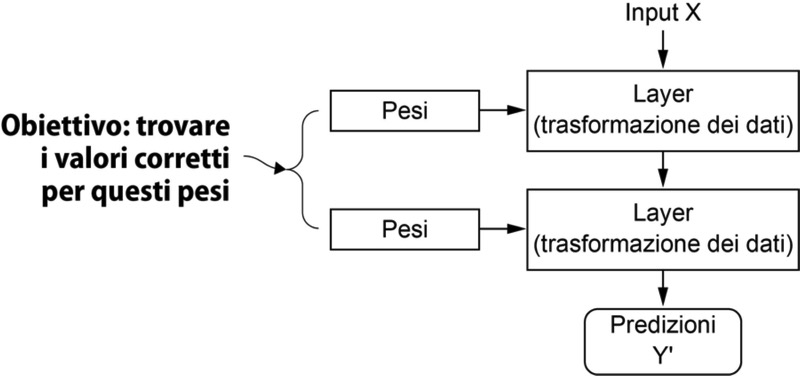
Una rete neurale è parametrizzata dai suoi pesi.
Per controllare qualcosa, occorre innanzitutto essere in grado di osservarlo. Per controllare l’output di una rete neurale, occorre essere in grado di misurare quanto questo output si avvicina al risultato previsto. Questo è il compito della funzione obiettivo della rete, la loss function. La funzione obiettivo prende le predizioni della rete e il target (ciò che vogliamo la rete produca in output) e calcola un punteggio di distanza, che valuti le prestazioni della rete in questo specifico esempio (vedi la figura seguente).
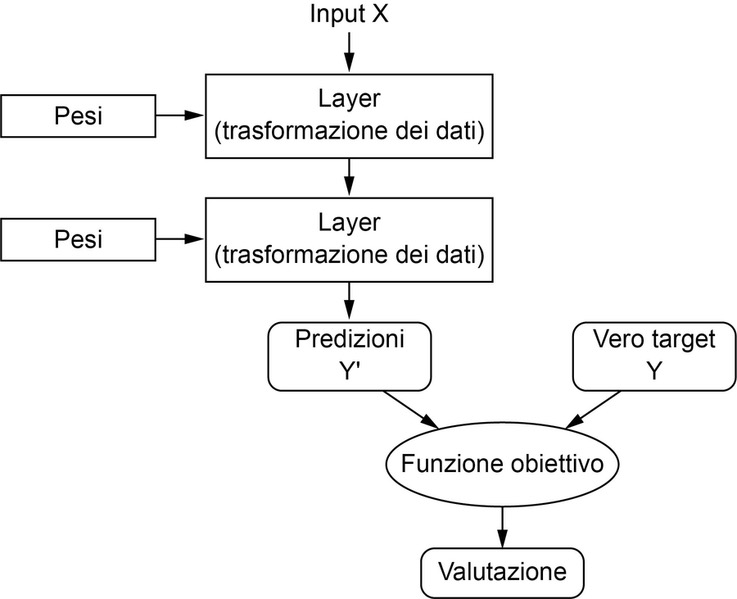
Una funzione obiettivo valuta la qualità dell’output della rete.
L’idea del deep learning consiste nell’impiegare questa valutazione come un segnale di feedback per regolare un po’ il valore dei pesi, in una direzione che riduca la distanza dal target per l’esempio corrente (si veda la figura sottostante). Questo aggiustamento è compito dell’ottimizzatore, che implementa l’algoritmo di retropropagazione: l’algoritmo centrale del deep learning.
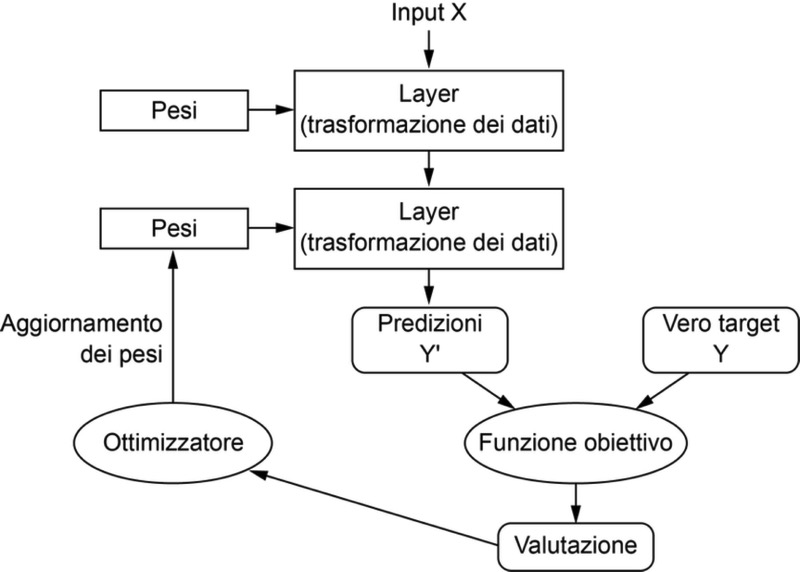
La valutazione fornita dalla funzione obiettivo viene impiegata come segnale di feedback per regolare i pesi.
Inizialmente, ai pesi della rete vengono assegnati dei valori casuali, ai quali la rete applica semplicemente una serie di trasformazioni casuali. Naturalmente, l’output sarà tutt’altro che ideale, e la valutazione finale fornirà una distanza molto grande. Ma a ogni esempio elaborato dalla rete, i pesi verranno aggiustati sempre più verso la direzione corretta e così la distanza dal target si ridurrà. Questo è detto ciclo di addestramento, il quale, ripetuto un numero di volte sufficiente (tipicamente decine di iterazioni su migliaia di esempi), fornisce dei valori per i pesi, i quali minimizzano la funzione obiettivo. Una rete la cui funzione obiettivo fornisce un valore minimo è tale per cui gli output sono molto vicini ai target: è una rete addestrata. Il meccanismo è semplice ma, esteso in termini di scala, fornisce risultati sorprendenti.
Che cosa riesce a fare, oggi, il deep learning
Il deep learning è salito alla ribalta solo a partire dal 2010. Nei pochi anni trascorsi, ha conseguito una vera e propria rivoluzione nel campo, con notevoli risultati nella percezione di problemi come la visione e la comprensione del parlato, problemi che implicano competenze naturali e intuitive per noi esseri umani, ma che sono sempre state elusive per le macchine.
In particolare, il deep learning ha ottenuto i seguenti risultati, tutti situati nei campi, storicamente complessi, del machine learning:
- classificazione delle immagini;
- riconoscimento vocale;
- trascrizione manuale;
- traduzione automatica;
- generazione vocale;
- assistenti digitali come Google Now e Amazon Alexa;
- guida autonoma di automobili;
- targeting pubblicitario avanzato, come quelli impiegati da Google, Baidu e Bing;
- ricerca avanzata di risultati nel Web;
- capacità di rispondere a domande poste in linguaggio naturale;
- capacità di gioco.
Stiamo ancora esplorando le possibilità del deep learning. Abbiamo cominciato ad applicarlo a un’ampia varietà di problemi che vanno oltre la percezione sensoriale automatica e la comprensione del linguaggio naturale, come il ragionamento formale. Se avremo successo, avrà inizio un’era in cui il deep learning assisterà gli esseri umani nelle scienze, nello sviluppo software e in molto altro ancora.
Questo articolo richiama contenuti dal capitolo 1 di Deep Learning con Python.
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Corsi che potrebbero interessarti

Data governance: diritti, licenze e privacy

Agile, sviluppo e management: iniziare bene

Machine Learning & Big Data per tutti
Libri che potrebbero interessarti

Deep Learning con Python
Imparare a implementare algoritmi di apprendimento profondo
Python
Guida alla sintassi, alle funzionalità avanzate e all'analisi dei dati