
A fronte dell’enorme quantità di dati raccolti e archiviati non sempre corrisponde una uguale abbondanza di informazioni.
I termini “dato” e “informazione” sono spesso confusi, ma in realtà indicano concetti diversi anche se fra loro correlati: i dati sono simboli, segni, numeri e non implicano alcun significato.
L’informazione invece è un dato al quale sia possibile attribuire un significato.
Un’abbondanza di dati di per sé non implica una vasta conoscenza, perché il passaggio dai dati alla conoscenza è un processo logico complesso. Possiamo definire la Business Intelligence come quell’insieme di strumenti e metodi che permettono di comprendere i dati utilizzandoli per ottenere quelle informazioni che aiutano a meglio raggiungere gli obiettivi.
Le applicazioni di Business Intelligence sono ambienti di supporto alle decisioni per l’analisi e la manipolazione di informazioni mission-critical in tempo reale e in maniera interattiva. Queste applicazioni migliorano la comprensione di informazioni chiave per identificare problemi di business e opportunità e prevengono la potenziale perdita di conoscenza all’interno dell’azienda derivante da un accumulo massivo dei dati in forma non realmente fruibile.
La negatività del 2003 ha lasciato tracce su tutto il mercato, anche su quello della Business Intelligence.
Il 2004 sembra improntato a una maggiore stabilità. I vendor ben capitalizzati stanno usando questo periodo di relativa calma per espandersi, aggiornare la cultura interna e acquisire nuove tecnologie che li aiutino a posizionarli favorevolmente in vista del recupero.
Quelli con minori risorse finanziarie, a causa del periodo sfavorevole, stanno subendo perdite significative, soffrono particolarmente il protrarsi di questa situazione e circa il 50% di loro sta lottando per non collassare.
Per chi resterà sulla scena, questo momento di relativa calma, dovrebbe essere sfruttato per fare delle riflessioni e prepararsi alla ripresa: una prima osservazione è che il successo oggi assume un significato diverso rispetto anche a solo due anni fa. In quel periodo infatti molti lo identificavano con le valutazioni gonfiate delle società e i prezzi delle azioni a livelli record.
Oggi invece si torna a parlare di concetti concreti quali la profittabilità, la base di clientela e una linea di prodotti credibile.
Un’altra riflessione è che le capacità dei vendor non devono essere finalizzate solo a creare valore nel breve termine, ma sul lungo periodo. Chi adesso occupa una posizione solida, ha l’opportunità di investire per il futuro della Bi e quindi aumentare il vantaggio che gli deriva dalla completezza della sua vision.
Nel panorama attuale questa completezza, anche per i brand più forti sulla bocca di tutti, necessita ancora di significativi passi in avanti per migliorare la scalabilità, l’usabilità, la gestibilità e la stabilità.
Queste caratteristiche sono spesso citate come attributi dei prodotti ma, in molti casi, hanno ancora bisogno di miglioramenti.
Nell’attuale clima le opportunità sono difficili da identificare e da cogliere e la tendenza è quella di acquistare da vendor certi e stabili. Il periodo di calma relativa offre un’importante opportunità ai vendor per prepararsi per il prossimo scenario di crescita.
Allo stesso modo, il mercato dovrebbe usare questo tempo per valutare i vendor con calma tenendo un occhio al futuro e valutando sia le funzionalità dei prodotti offerti sia la solidità e la stabilità di chi li vende.

In prima approssimazione, la Business Intelligence ha il compito di ridurre drasticamente i costi di accesso alle informazioni.
Senza un sistema di questo genere ogni richiesta richiede la raccolta dei dati, la loro integrazione, il merging e la sommarizzazione dei risultati. Con un sistema di Bi invece i dati sono raccolti e integrati solo una volta e ogni report può essere lanciato in maniera veloce ed efficiente. La Bi risolve il problema di integrare i dati storici trasformandoli in vantaggio competitivo con l’aumento di revenues e quote di mercato e la riduzione dei costi. Il problema è che la quantificazione di questi risultati non è semplice.
Inoltre, è influenzabile da fattori come l’introduzione sul mercato di nuovi prodotti, i cambiamenti delle condizioni di mercato, dell’economia. Per questi motivi non è possibile indicare dei parametri universalmente validi. Si tenterà di dare alcune indicazioni utili per la valutazione dei benefici dell’investimento effettuato. Per facilitare questa misurazione si può pensare di dividere i vantaggi in funzionali, tattici e strategici.
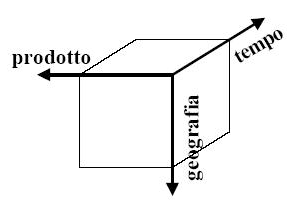
A ogni voce componente queste famiglie si provvederà ad assegnare un peso e una misura. Come evidenziato da figura 1, gli obiettivi funzionali so-no perseguiti con specifiche applicazioni per i settori aziendali quali vendite, marketing, finanza, operations, HR e IT come per esempio cross-selling analysis, market & customer penetration, production planning & quality control, vendor performance, customer clickstream information.
Gli obiettivi tattici sono rappresentati invece dalla capacità di fare analisi multidimensionale, interagire con scenari ad hoc come l’analisi what-if, drilling e slice & dice mentre, quelli strategici, sono il miglioramento continuo delle capacità decisionmaking, umento delle revenues, riduzione dei costi, accesso, valutazione e ottimizzazione delle operazioni e delle relazioni, distribuzione di migliori strumenti agli utenti, e maggiore cattura e storicizzazione dei dati transazionali.
Un aspetto importante è identificare la classe di utenza destinata a cogliere i maggiori benefici. Si pensi alla divisione per classi di comportamento introducendo le figure del farmer e dell’explorer. Un farmer sa cosa vuole, ha un comportamento prevedibile, di solito trova quello che cerca e raramente estrae grossi volumi.
Un explorer è imprevedibile: possono passare mesi senza che sottometta una query e poi in una settimana ne sottomette molte che, di solito, sono anche molto gravose.
Le considerazioni per valutare i benefici vanno applicate ai farmer per la loro prevedibilità e non agli explorer per il loro carattere più aleatorio.
Architettura
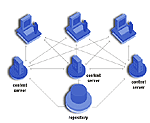
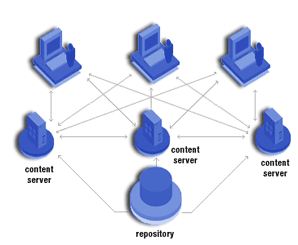
Il disegno di un sistema di BI riguarda i processi e i tools utilizzati per prelevare i dati dai sistemi sorgenti transazionali, detti OLTP (online transaction processing), e renderli accessibili agli utenti di business. Le componenti principali di una tale architettura comprendono:
- I sistemi sorgente
- I servizi di migrazione dei dati (extraction, cleansing, transforming, e loading)
- I servizi del database
- I servizi di Query, Reporting e Analysis (data access/security, query optimization, query governing, activity monitoring)
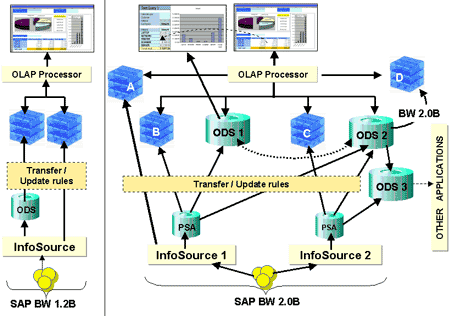
Questa architettura, in forma molto semplificata, si può schematizzare come in figura 2.
Sistemi Alimentanti
È l’insieme dei sistemi legacy da cui provengono i dati e possono essere i più disparati: mainframe, dipartimentali e transazionali così come la tecnologia: file testuali, database relazionali, gerarchici di qualunque versione.
Teoricamente (dipende dai limiti tecnologici), qualunque fonte può essere letta per inserire i dati nella successiva area di staging.
Questo servizio è espletato dai tool cosiddetti di Extraction, Cleansing, Transformation and Loading (Ectl).
Staging Area
Si intende un’area usata con finalità di Staging in cui i dati sono parcheggiati in preparazione dell’elaborazione che li inserirà nel data warehouse destinazione.
Il modello dati è simile o identico a quello dei sistemi sorgente, i dati vi permangono solo il tempo necessario per le trasformazioni prima del caricamento nell’area successiva. In quest’area si possono attuare meccanismi molto semplici di restart-recovery e le strategie di back-up sono da valutarsi unicamente tenendo presente il costo di un reinserimento dei dati.
Il mapping è molto semplice e non prevede algoritmi di organizzazione dei dati in strutture dimensionali o normalizzate.
Operational Data Store
Per Operational Data Store (Ods), si intende un’estensione del data warehouse rivolta ai sistemi operazionali, dove sono svolti i primi controlli di integrità. Quest’area fornisce le basi per l’integrazione con il mondo operazionale dal momento che il data warehouse non offre alcuna estensione in tal senso. L’area appartiene al dominio operazionale i dati entrano dai sistemi transazionali e talvolta non sono integrati. Secondo questa accezione, l’Ods è un ambiente full function dove sono consentite le operazioni di aggiornamento record oriented.
Disegno del Database
Il disegno logico di un database OLAP (On Line Analitical Processing) è molto diverso da quello di un sistema OLTP (On Line Transaction saction Processing) che segue le regole della normalizzazione che, minimizzando la ridondanza dei dati, risulta molto performante per le transazioni che hanno normalmente come soggetto un insieme minimo di righe di varie tabelle collegate. Il disegno di un database per la business intelligence (data warehouse) deve essere affrontato con metodologie dette di modellazione dimensionale, che consentono un utilizzo semplice da parte dei tools di Query & Reporting, in modo da garantire alte prestazioni pur impattando su enormi moli di dati, come quelli storici.
Data warehouse
Il data warehouse consente di disaccoppiare i dati fra le applicazioni che li forniscono e quelle che li acquisiscono, facilitando così un’evoluzione flessibile dei sistemi informativi e dei canali di interazione. A fronte della continua evoluzione di una infrastruttura It, l’utilizzo del Dw come hub di snodo dell’informazione, consente di evitare una proliferazione delle integrazioni tra i differenti sistemi. Un modo comune di descrivere un data warehouse è quello di riferirsi alle sue caratteristiche così come esposte da Inmon.
Secondo queste definizioni un data warehouse è un database:
- Subject Oriented: disegnato per supportare l’analisi dei dati per aree applicative. La possibilità di definire data warehouse tematici li rende subject oriented.
- Integrato: recepisce i dati dalle sorgenti più disparate e li dispone in formati consistenti risolvendo conflitti come la naming convention, l’inconsistenza fra unità di misura, ecc.
- Non volatile: una volta che i dati sono stati inseriti non cambiano più, infatti lo scopo è quello di consentire l’analisi dell’accaduto su base storica.
- Time variant: Il focus è quello di mostrare il cambiamento del business nel tempo attraverso l’utilizzo di dati storici.
Extraction, Cleansing, Transformation and Loading tools (Ectl)
Enormi quantità di dati, molteplici e diversi sistemi legacy, formati di dati complessi o obsoleti, terminologia di business non normalizzata, diverse codifiche dei dati e integrità referenziale carente sono solo alcuni degli ostacoli che un’organizzazione deve superare per alimentare un Dw e ciò è compito dei tool Ectl.
Ulteriori vincoli sono che il processo sia completato nello spazio di tempo allocato, soddisfi il Service Level Requirement e riesca a gestire la crescita di volumi attesa. Il processo di Ectl è la fase più delicata sia in sede di sviluppo che in esercizio e quindi, le saranno dedicati i maggiori sforzi e attenzioni.
Si ricorda l’importanza di procedere col necessario rigore per ottenere dati puliti senza cedere alla pressione di abbassare il livello di qualità del filtro, cedendo di fronte alla eventuale sporcizia dei dati sorgenti. Un sistema con un filtro qualitativo basso è inutile e vanifica l’investimento fatto.
Olap Query & Reporting
Questi tool sono destinati a utenti con capacità analitiche intensive e che costruiscono dinamicamente i propri report, definendo runtime calcoli complessi o navigando fra i dati percorrendo le dimensioni e vedendo così i fatti aggregati a diversi livelli. Questa flessibilità, potenza di calcolo e dinamicità è resa possibile dall’accesso al repository dei metadati attraverso il quale il tool conosce il modello dati e permette all’utente di navigare solo conoscendo il business, senza preoccuparsi sul come e il dove reperire le informazioni.
In generale i tool Olap hanno le seguenti caratteristiche:
- Capacità avanzate di data manipulation come roll up, drill down e pivoting con tempi di risposta brevi anche su grandi quantità di dati.
- Capacità di calcolo avanzate come analisi periodo su periodo, percentuali sul totale dei margini di contribuzione, top five, bottom five etc.
- Capacità di complessi data browsing per presentare le informazioni usando architetture sia client/server sia Internet/intranet.
È evidente che la possibilità di rilasciare tool Olap sempre più potenti e flessibili è supportata dalla possibilità di avere repository di metadati sempre più ricchi di informazioni e condivisibili fra vari ambienti e che lo sviluppo tecnologico dell’uno sia legato allo sviluppo dell’altro. Questa è una importante direzione di sviluppo per le Enterprise Business Intelligence Suite (Ebis).
Pianificazione del progetto
Ci sono parecchi fattori da tenere in considerazione quando si pianifica un progetto di Business Intelligence.
Se è il primo progetto di Bi realizzato in azienda, gli obiettivi non devono essere troppo ambiziosi, molti progetti di questo tipo falliscono per questo motivo.
Se possibile, ci si deve limitare a una singola subject area e ridurre il numero dei sistemi sorgenti.
Un progetto di Business Intelligence richiede la collaborazione delle figure di project sponsor, esperti di business, Ectl programmer, Olap tool programmer, project manager, network administrator, requirements analyst, database designer, source system analyst, Dba, power user.
In funzione della dimensione del progetto, i singoli individui possono ricoprire più ruoli mentre alcuni possono essere rivestiti da più di un individuo (di solito occorrono più esperti di business). Il gruppo di progetto è costituito da due grandi famiglie: esperti di business e di IT, pilotato dal business e il coinvolgimento di esperti in materia è vitale.
Tre figure di business, in particolare, assicurano la buona riuscita del progetto: il project sponsor, il business subject matter experts e il power user.
Il project sponsor deve essere una persona con potere significativo in azienda e godere del rispetto di tutta l’organizzazione.
Se non promuove e supporta attivamente il progetto, le chance di successo si riducono. Le risorse che meglio comprendono il business devono essere costantemente impegnate nella definizione e la revisione delle soluzioni.
Il power user, usando il sistema nel mondo reale, ha una grande conoscenza dei dati e una buona visione di come usare l’applicazione in maniera creativa per fornire i risultati attesi.
Quando si pianifica un progetto di questo tipo, è opportuno raccogliere le opinioni dei vari membri del team e, possibilmente, coinvolgere anche figure esterne che hanno esperienza nel campo. I progetti possono fallire miseramente a causa di una pianificazione non realistica e i ritardi eccessivi possono ridurrne la credibilità.
La fase che più spesso va in crisi è Ectl: il processo spesso impiega più tempo di quanto stimato inizialmente a causa di complessità inattese e, del resto, non è possibile prevedere a priori tutte le insidie nascoste nei sistemi sorgente. È solo l’esperienza del team quindi, che aiuta a fornire una stima ragionevole.
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo
