

Di che cosa parliamo
- Come si inserisce codice JavaScript in una pagina web
- Come estrarre informazioni da LinkedIn in grandi quantità
- Che cosa succede quando visiti un sito
- Come ottenere informazioni da Instagram in modo automatizzato
- Come è fatto Twitter sotto il cofano
1. Come si inserisce codice JavaScript in una pagina web
Tra i programmatori più navigati e un po’ snob vige una regola non scritta: prendersi gioco di chi si definisce programmatore e sa solo scrivere codice HTML. Questo è anche uno dei motivi per cui è stato sviluppato JavaScript: offrire al Web il suo vero linguaggio di programmazione. JavaScript, oggi, è il linguaggio più utilizzato per applicazioni e servizi web. Proprio per la sua natura, JavaScript non è semplice da capire quanto HTML, ma rappresenta un buon compromesso per chi è un po’ pigro e non se la sente di imparare linguaggi più complessi, e al tempo stesso vuole vantarsi di essere un vero programmatore.
Scherzi a parte (o forse no), JavaScript è divenuto così imprescindibile, quando si parla di Web, che analizzare un social media o una semplice pagina web richiede quanto meno una sua conoscenza basilare. Per questo motivo, i prossimi paragrafi non ti trasformeranno in un programmatore esperto, ma ti offrono quanto basta per imparare a leggere del codice JavaScript e orientarti tra le sue istruzioni al fine di ricavarci qualche utile informazione.
Il miglior amico di HTML
Partiamo dal presupposto che JavaScript, in quanto vero linguaggio di programmazione, può essere utilizzato in un mucchio di contesti diversi. Di base nasce per rendere più interattive le pagine web, e per questo ancora oggi viene incluso nelle pagine HTML, ma nella sua semplicità è così potente da essere utilizzato per creare web server. In questo caso, tuttavia, si utilizzano appositi framework, come Node.js, vale a dire grossi pezzi di codice preconfezionato pronti per essere assemblati all’occorrenza.
In linea di massima, se nella pagina web che hai davanti c’è della grafica che si muove, o una qualche forma di interazione avanzata, come un sistema di messaggistica o grafica 3D animata al passaggio del mouse, lì c’è codice JavaScript. Il successo del linguaggio deriva proprio da questa sua grande versatilità: JavaScript funziona con qualsiasi browser degno di questo nome, anche se molto vecchio, ed è pure piuttosto rapido.

Inoltre, è abbastanza semplice da imparare e, ciliegina sulla torta, adotta il paradigma a oggetti, che lo rende un linguaggio trendy e moderno quanto basta. Dei suoi due principali difetti, il primo è che è veloce, ma non così veloce come tanti altri linguaggi di programmazione, mentre il secondo è che JavaScript non consente di mascherare il suo codice, come fanno tanti altri suoi colleghi. Quindi, se una pagina web utilizza codice JavaScript, sarà sempre possibile analizzarlo e comprenderne ogni segreto. Dal nostro punto di vista, questo non è certo un difetto, tutt’altro!
Il concetto di script
Inserire codice JavaScript in una pagina HTML è un gioco da ragazzi. È un po’ come inserire codice CSS, solo che si utilizza un altro tipo di tag contenitore.
<script>
Istruzioni JavaScript
</script>
Questo è il modo migliore per inserire qualche istruzione JavaScript in mezzo a quelle HTML. Un esempio spicciolo:
<head>
<title>Un test per JavaScript</title>
</head>
<body>
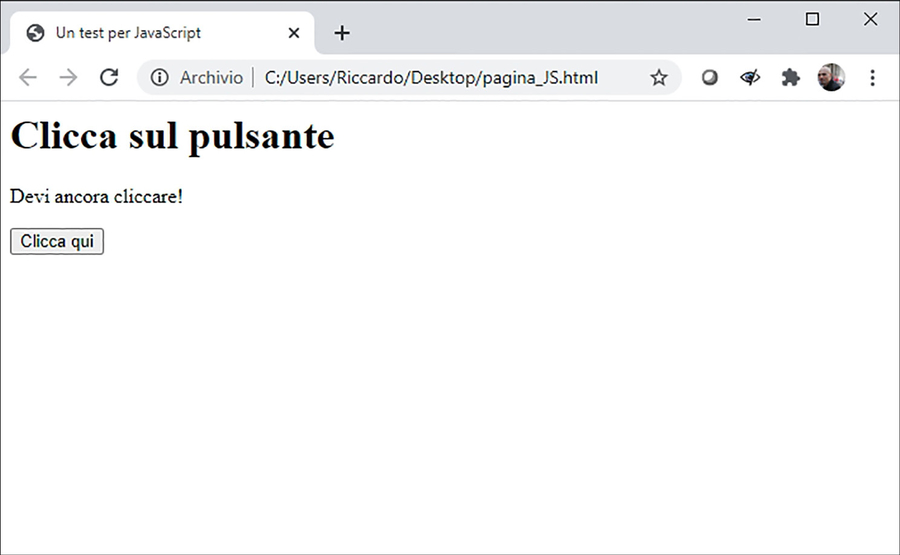
<h1>Clicca sul pulsante</h1>
<p id="messaggio">Devi ancora cliccare!</p>
<button type="button" onclick="cliccaQui()">Clicca qui</button>
<script>
function cliccaQui() {
document.getElementById("messaggio").innerHTML = "Hai cliccato!";
}
</script>
</body>
</html>
Se confezioni un HTML con queste istruzioni potrai poi vantarti di aver realizzato il tuo primo script in JavaScript. Soprattutto, avrai messo mano per la prima volta a questo linguaggio di programmazione. Lo script non fa molto: intercetta l’eventuale clic sul pulsante e, nel caso, provvede a cambiare il messaggio da "Devi ancora cliccare!" a "Hai cliccato!".
JavaScript consente di rendere più interattive e moderne le pagine web. Proprio per questo, viene utilizzato anche per gestire buona parte delle informazioni che vengono gestite da un sito o un servizio.
Uno script come quello che hai visto, quindi incluso tra i tag <script>, può essere piazzato un po’ dappertutto, anche se si tende a metterlo nel corpo del file HTML, quindi nella sezione <body>. Potresti, tuttavia, trovarlo anche in quella <head>. Se il codice JavaScript è abbondante, un po’ come avviene col CSS è buona prassi dedicargli un file apposito, che in questo caso ha estensione .js. File JS esterni, chiamati da un file HTML, riconducono a codice JavaScript che puoi analizzare con un semplice clic. Anche in questo caso, tuttavia, è necessario richiamare i file JS utilizzando <script>:
<script src= "ilfileesterno.js"></script>
In alcuni casi, potresti trovare un comando aggiuntivo, ma non ti devi spaventare. Alludo a questo:
<script src= "ilfileesterno.js" defer></script>
Che cosa combina defer? Semplice: dice al browser di caricare il codice JavaScript ma di eseguirlo solo dopo che ha completato il parsing di tutta la pagina web, cioè solo dopo aver eseguito tutte le istruzioni che vengono prima di </html>. In caso contrario, avvierebbe subito l’esecuzione del codice. La presenza o meno di defer ti dice molto su una pagina web, perché di fatto stabilisce l’ordine di esecuzione dei comandi nella pagina e, quindi, ti dà una precisa idea di come questa si comporta e in quale ordine gestisce certe informazioni.
2. Come estrarre informazioni da LinkedIn in grandi quantità
Se il tuo scopo è passare il più possibile inosservato e raccogliere informazioni LinkedIn su vasta scala con un piglio professionale… lì fuori ci sono diversi ottimi servizi utili allo scopo, ma ce n’è uno, in particolare, a dare una marcia in più alla tua caccia grossa su LinkedIn. Si tratta di Scrapingdog, una soluzione tra le più apprezzate del settore, tanto da essere utilizzata da molti big del mercato del Web.
Scrapingdog è un’azienda con oltre dieci anni di esperienza, nata per sviluppare soluzioni per il bypass automatizzato di sistemi di controllo come il captcha. Da qualche anno ha deciso di dedicarsi anche allo scraping, con ottimi risultati.
La tecnologia che lo guida poggia su una serie di indirizzi IP che, utilizzati a rotazione, evita che le tue ricerche vengano bloccate e l’attivazione di codici captcha che rallenterebbero o fermerebbero le attività automatizzate. Senza contare che i risultati ottenuti, a quel punto, non solo possono essere visualizzati nei formati più disparati, ma anche inoltrati e integrati nelle tue applicazioni preferite. Dulcis in fundo, puoi sfruttare Scrapingdog sia in una comoda e semplice versione web, sia direttamente come API, utilizzando il tuo linguaggio preferito (ovviamente anche Python).
Utilizzare Scrapingdog
Scrapingdog è disponibile in una versione trial gratuita, ma offre diverse soluzioni a pagamento che partono da un paio di decine di euro al mese per fare tutto quel che serve a un professionista.
Per provare le potenzialità di questo servizio, tutto quel che devi fare è andare su http://www.scrapingdog.com e fare clic, in alto a destra, su Free Trial. Inserisci le informazioni richieste, fa’ clic su Register, poi vai nella casella di posta elettronica specificata e fa’ clic sul link di verifica. Vieni così portato a una pagina di Scrapingdog che ne promette delle belle. Un messaggio, innanzitutto, ti invita a ricorrere alla API se sei uno sviluppatore, ma per il momento facciamo i lavativi. Il codice che vedi è la API key, che tra l’altro viene riportata anche nella parte superiore: ti identifica in modo inequivocabile.
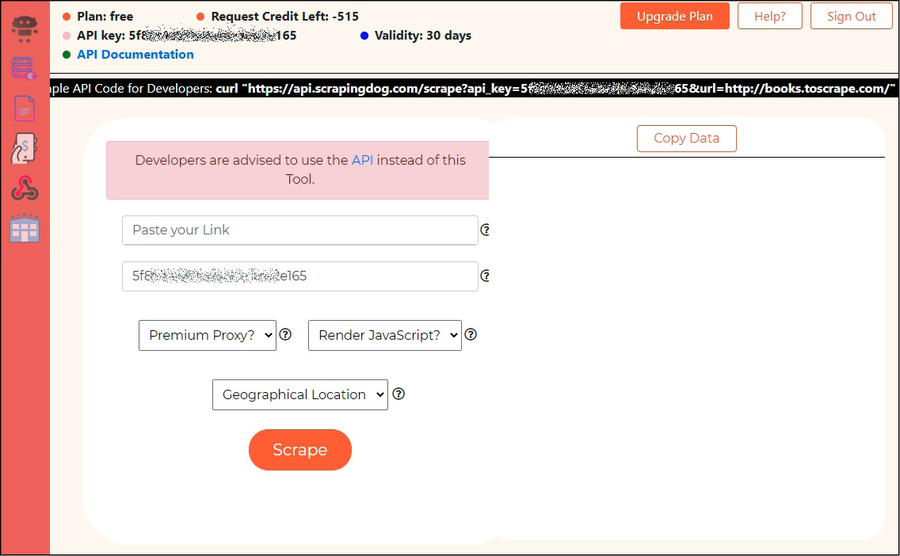
Per la maggior parte delle esigenze si può utilizzare direttamente l’interfaccia web di Scrapingdog.
Per un utilizzo spiccio di Scrapingdog tutto quel che devi fare, ora, è scegliere un qualsiasi profilo LinkedIn e incollarne l’indirizzo su Paste your link. A questo punto puoi lasciare tutto com’è e fare clic sul pulsante Scrape per vedere, poi, il risultato nel box a destra. Qui, se lo desideri, puoi copiare il tutto facendo clic su Copy Data.
In alternativa, come abbiamo visto, puoi far valere il tuo lato da sviluppatore e utilizzare l’API. Il suo utilizzo non è molto complicato, e lo puoi sperimentare impiegando cURL.
curl "https://api.scrapingdog.com/linkedin/?api_key=XXX&type=YYY&linkId=ZZZ"
Le parti fondamentali sono tre. Innanzitutto, mettere la tua API key. Poi specificare il type, cioè il tipo di contenuto LinkedIn che vai a dare in pasto a Scrapingdog. Infine, l’ID, cioè la stringa identificativa che contraddistingue il tuo obiettivo. Un piccolo esempio:
curl "https://api.scrapingdog.com/linkedin/?api_key=5eaa61axxxxxxxx763tr516e4653&type=profile&linkId=rbranson"
Questa stringa, da digitare direttamente nel terminale del tuo PC, ma che volendo puoi tradurre in semplice codice Python, ti restituisce tutto lo scraping della pagina LinkedIn di Richard Branson.

L’esito di un cURL tramite Scrapingdog.
Combinare Scrapingdog e Python ti offre innumerevoli vantaggi, come il poterti creare i tuoi tool sulla base delle tue specifiche esigenze. Di base, ti è sufficiente scrivere del codice che includa l’importazione della libreria, che hai già visto, e una riga di questo tipo:
r = requests.get('https://api.scrapingdog.com/scrape?api_key=<your-api-key>&url=https://www.linkedin.com/school/apogeo/').text
In questo caso abbiamo effettuato lo scraping diretto della pagina LinkedIn di Apogeo Editore.
3. Che cosa succede quando visiti un sito
Visitare un sito è una delle cose più semplici che puoi fare, quando gironzoli per il Web. Apri il tuo browser preferito, digiti l’indirizzo del sito, attendi qualche secondo ed eccoti nella sua home page. Banale, vero? Eppure, scommetto che non ti sei mai chiesto che cosa succede, per davvero, quando esegui questa semplice azione. Ti stupiresti di quanta raffinata tecnologia si nasconda dietro qualche tasto premuto e qualche clic!
Cerchiamo di sopperire a questa piccola lacuna con una spiegazione un po’ tecnica, ma spiegata in modo facile e con qualche (grossa) semplificazione, che parte proprio dal digitare l’indirizzo nel browser. Mettiamo, che ne so, che digiti https://www.apogeonline.com, lo splendido sito di Apogeo.
Il Web, essendo un sottoinsieme di Internet, di rado ragiona con le lettere, preferendo loro i numeri. È per questo che, una volta digitato l’indirizzo, il browser consulta una sorta di tabella, chiamata Domain Name System, che molti conoscono come DNS. Si tratta di un sistema che fa corrispondere un indirizzo letterale a uno numerico, il famoso indirizzo IP. Così tu non ti devi ricordare o annotare centinaia di orrendi indirizzi numerici, e il Web può continuare a utilizzare il suo linguaggio preferito, quello dei numeri. Nel caso del nostro bel sito, la corrispondenza, nel momento in cui ti scrivo, è 31.156.53.75. Quindi, se in un browser provi a inserire direttamente questo IP, ti ritrovi davanti al sito di Apogeo.
Ora il browser ha l’agognato indirizzo IP del sito. Ma questo indirizzo, tecnicamente, dove porta? Al server, cioè il computer che contiene, fisicamente, tutti i file che compongono il sito. Può trattarsi di un server che contiene solo il sito che ti interessa oppure, nella maggioranza dei casi, si tratta di un server condiviso. Le sue risorse, cioè, sono suddivise tra tanti siti che le noleggiano con offerte low cost dei cosiddetti host provider (quelle aziende che vendono spazi web nei quali costruire siti).
Al contrario, esistono siti e servizi web così famosi e utilizzati da essere presi d’assalto da milioni di utenti contemporaneamente, e che dunque hanno bisogno di suddividerli su più server: un servizio, tanti server. Facebook, Twitter, Google, Amazon, sono solo alcuni esempi famosi.

Ad Altoona, in Iowa (USA), si trova uno dei data center di Facebook, vale a dire i centri che custodiscono i tantissimi server che danno vita al noto social media e i servizi annessi. È stato il quinto a essere inaugurato da Facebook e ha richiesto un investimento iniziale di 400 milioni di dollari.
Qualunque sia il tipo di server, il browser gli invia una richiesta, sfruttando il protocollo HTTP o HTTPS. Di che richiesta si tratta? Semplice: il tuo browser chiede, a mani giunte, una copia del sito, o per lo meno dei file che ne compongono la home page. Se il server, sulla base di certe condizioni, dà il suo OK, trasmette al client, cioè il browser, un messaggio di approvazione, e inizia l’invio dei file, per esempio delle splendide pagine web.
Non scenderò in noiosi dettagli tecnici, ma diciamo che i file, a questo punto, sono trasmessi al browser a pezzetti, chiamati pacchetti. Una volta che giungono a destinazione, il browser non fa altro che riassemblarli nel modo corretto e, alla fine, visualizzare il risultato sullo schermo del tuo dispositivo: hai davanti ai tuoi occhi il sito web. Ogni volta che effettui un clic per scegliere un’altra pagina, si rimette in moto questo processo tra client e server. Eccoti presentato, per sommi capi, il funzionamento di un sito web. Ora, però, scopriamo qualche succoso particolare in più.
Il diavolo sta nei dettagli, e anche il Web
Se fin qui ti sei fatto l’idea che il Web sia molto più complicato di quanto pensassi, beh, sappi che hai ragione, e considera pure che finora ci siamo concessi molte grosse semplificazioni. Però hai ben chiaro quali sono gli elementi costitutivi che ti permettono di poterti gustare un buon sito web.
- Internet.
- Server.
- Client.
- HTTP/HTTPS.
- Pagine web.
Conviene spendere ancora qualche parolina in più sul server. Se un computer deve contenere un sito web, ecco che prende il nome di web server. Un web server è caratterizzato da speciali software che rendono fruibile il sito da tutti i client che andranno a consultarlo attraverso i loro browser.
Ci sono tante tipologie di software utili allo scopo, come per esempio Apache, Nginx, IIS, LiteSpeed Web Server e Google Web Server. Considera che i primi tre, insieme, rappresentano oltre il 90% di tutto il mercato. Scopo ultimo del web server è quello di attivare e gestire il protocollo HTTP, in modo da permettere quella serie di trasmissioni e ricezioni di file di cui abbiamo già parlato. Poi, a seconda del tipo di web server, si hanno prestazioni diverse, che lo rendono più adatto a gestire, di volta in volta, un piccolo blog, un magazine, un social media, un servizio di streaming o tanto altro ancora.
Eppure, per quanto possa essere complesso il progetto con cui si ha a che fare, l’unica differenza è data da prestazioni e funzioni accessorie, mentre il cuore tecnologico è pressoché identico.
Se abbiamo detto che l’HyperText Transfer Protocol regola, di fatto, lo scambio di dati, poco invece sappiamo della natura di questi dati, i famosi “pacchetti”. È chiaro che si tratta di materiale molto eterogeneo, ma nel caso di un normale sito web è rappresentato in larga parte da istruzioni in linguaggio HTML. Per ora ti basti sapere che si tratta dell’HyperText Markup Language, cioè un linguaggio in grado di descrivere al tuo browser come visualizzare il sito che stai visitando. HTML è uno dei pilastri del Web, dei siti e, dunque, di chi va a caccia di informazioni nascoste tra pagine e documenti digitali. Pensalo come l’inglese, una lingua universalmente riconosciuta e capace, a volte in modo semplice altre più complesso, di farti dialogare in ogni angolo del mondo. E, in questo caso, quel mondo si chiama Web.
4. Come ottenere informazioni da Instagram in modo automatizzato
instagram_scraper è uno dei migliori progetti di reperimento di informazioni su Instagram, molto asciutto ed elegante. Devi correre sul repository del progetto e fare clic sul pulsante verde Code, per selezionare poi Download ZIP. Scarica l’archivio di file ed estrai il tutto in una cartella facilmente raggiungibile del tuo PC.
Di “instagram_scraper”, in Rete, ne trovi parecchi, ma questo di cui ti parlo ha il pregio di essere molto semplice, veloce e integrabile nei tuoi programmi Python, che potranno così spingerlo ben oltre i suoi limiti.
Dal terminale del computer, accedi alla cartella e poi digita:
pip install -r requirements.txt
In pratica, viene installata la libreria di instagram_scraper sulla base di una serie di indicazioni elencate nel file requirements.txt. A volte, con programmi un po’ particolari, i rispettivi sviluppatori preferiscono offrire questa alternativa per evitare errori di installazione.
Una volta terminata l’installazione, sei pronto per scrivere un piccolo programma Python:
#nota che non utilizzo il classico import
from igramscraper.instagram import Instagram
instagram = Instagram()
account = instagram.get_account_by_id(3)
print('Informazioni sull'account:')
print('Id: ', account.identifier)
print('Nome utente: ', account.username)
print('Nome completo: ', account.full_name)
print('Biografia: ', account.biography)
print('Indirizzo foto: ', account.get_profile_picture_url())
print('Sito web: ', account.external_url)
print('Numero di post pubblicati: ', account.media_count)
print('Numero di follower: ', account.followed_by_count)
print('Numero di profili seguiti: ', account.follows_count)
print('Privato: ', account.is_private)
print('Verificato: ', account.is_verified)
Quel che viene fatto da queste poche, semplici, righe di programma, è estrarre alcune informazioni dall’account Instagram con ID pari a 3. E siccome sono un Grinch e voglio rovinarti la sorpresa, ti dirò subito che si tratta niente poco di meno che del profilo di Kevin Systrom.
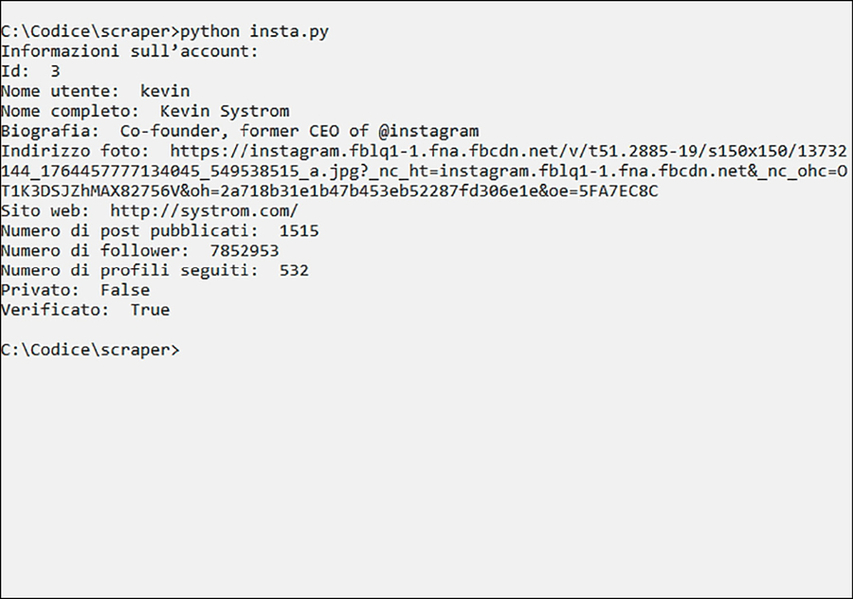
Con poche righe di Python, e l’aiuto di un’eccellente libreria esterna, hai ottenuto un sacco di informazioni interessanti su un profilo scelto in base al suo ID, cioè il numero che lo identifica tra tutti gli utenti Instagram.
L’intervallo di profili è ristretto per un motivo molto semplice: se instagram_scraper non trova un certo ID esce dal programma con un messaggio di errore. Potresti quindi migliorarlo prevedendo un’eventuale eccezione, e già che ci sei potresti anche direzionare tutte queste informazioni in un bel file .txt.
Se ti chiedi, invece, come se la cava instagram_scraper in fatto di autorizzazioni, il discorso è semplice. Se i profili Instagram da cui estrai informazioni sono pubblici, puoi addirittura fare a meno di avere un tuo account Instagram. Se invece un profilo è privato, ti occorre fartelo amico col tuo account e, a quel punto, inserire delle istruzioni nel tuo programma, sempre sfruttando alcune funzioni di questa splendida libreria.
instagram.with_credentials('username’, 'password’)
instagram.login()
Dove devi inserire username e password del tuo account o comunque dell’account che è entrato nella cerchia dei follower di quello da cui vuoi estrarre delle informazioni.
Funzioni per tutti i gusti
Nello scompattare il file .zip di instagram_scraper forse ti sarai accorto della presenza della sotto-cartella examples. Bene, qui trovi una miniera di piccoli programmini pronti all’uso per sfruttare le varie funzioni della libreria. Qualcuno richiede qualche ritocchino per essere messo in pista, ma si tratta di bazzecole. Mettiamo, per esempio, che vuoi sapere l’ID di un account in base al suo username. Scartabellando tra i vari file ecco get_account_by_username.py. Appena lo apri, ti accorgi che, tutto sommato, non ti servono tutte quelle informazioni e ti basta prenderne a prestito solo qualche riga. Così:
from context import Instagram
instagram = Instagram()
account = instagram.get_account('apogeonline')
print('Account info:')
print('Id', account.identifier)
Ti basta avviarlo per trovare il codice ID associato allo username apogeonline.
Nel caso di questi programmi, è importante salvare i tuoi file nella medesima sottocartella, che è dove si trova anche il file context.py, richiamato proprio nella prima riga. In alternativa, ovviamente, puoi copiare il file context.py insieme al tuo file sorgente.
A questo punto, ID alla mano, puoi sperimentare con altri programmi Python per sgraffignare qualche interessante informazione dai tuoi profili preferiti.
5. Come è fatto Twitter sotto il cofano
Twitter è un social media nato nell’ormai lontano 2006, come piattaforma di micro-blogging dedicata alla pubblicazione di brevi messaggi. Col tempo è molto cambiato, per esempio integrando anche i video e supportando messaggi più lunghi, e va da sé che le modifiche visibili dagli utenti corrispondono anche a grosse modifiche a livello strutturale. La sua architettura più intima, tuttavia, è rimasta pressoché inalterata nel tempo e si compone essenzialmente di sei elementi, che descrivono Twitter, come possono descrivere perfettamente anche Facebook, Instagram e qualsiasi servizio web che abbia a che fare con grandi moli di utenti e la gestione dei loro dati. Si tratta di un’architettura a strati, o layer, che parte da uno più interno e accessibile solo a chi sviluppa il social media, per arrivare quello più esterno, cioè quello visibile all’utente finale.
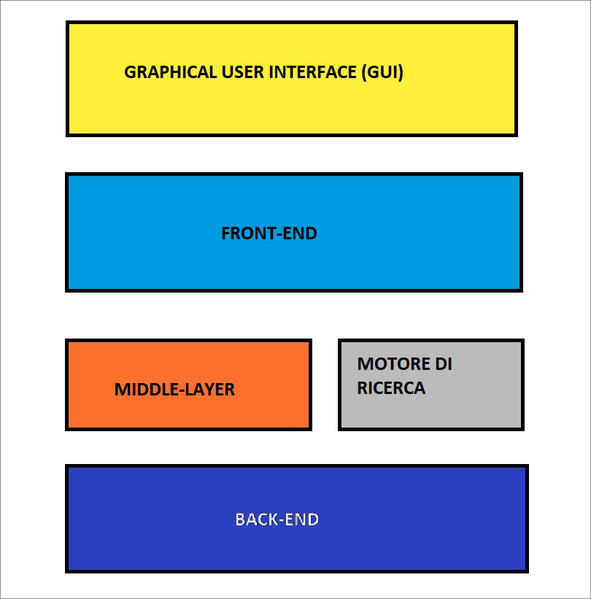
L’architettura su cui si basa Twitter e che descrive buona parte dei social media e dei servizi web in genere.
Innanzitutto, c’è il back-end, vale a dire tutto ciò che muove Twitter e non è esposto all’utente finale. Il server, per semplificare. Opposto il discorso sul front-end, vale a dire tutto ciò che rende possibili le interazioni tra il social media e gli utenti. Tra front-end e back-end troviamo due elementi: un middle-layer e il motore di ricerca.
Il primo serve a ottimizzare lo scambio di dati tra front-end e back-end, mentre il secondo è il componente software che si occupa di effettuare le ricerche interne, tra i contenuti del social media. Nello strato più esterno, infine, troviamo l’interfaccia grafica, la GUI, Graphical User Interface, vale a dire la “maschera” visualizzata a tutti gli effetti agli utenti.
E la API di Twitter, dove si colloca? Ce la siamo forse dimenticata per strada? Assolutamente no, ma occorreva avere prima ben chiara questa architettura. L’Application Programming Interface, infatti, si trova nel middle-layer: così è chiaro come l’API, di fatto, possa esporre alcuni dati e funzioni del back-end bypassando il resto, vale a dire front-end e GUI. Questa architettura può essere vista come una serie di filtri che limitano sempre più l’accesso a funzioni e dati del back-end, aumentando, al contempo, la semplicità dell’interfaccia.
Il back-end, dunque, offre l’accesso a qualsiasi dato e funzione del social media, ma è disponibile solo per l’azienda che lo sviluppa. Il front-end, al contrario, è disponibile per qualsiasi utente, ma offre un accesso molto limitato a quel che è il back-end ha da offrire. Nel mezzo c’è l’API: accedervi non è un gioco da ragazzi, specie per chi non sa nulla di programmazione, ma d’altro canto utilizzandola si può metter mano a funzioni altrimenti irraggiungibili con front-end e GUI.
Scovare dati e informazioni abitualmente non accessibili al normale utente, e quindi tramite front-end e GUI, richiede quindi di passare o dal back-end o dall’API. Nel caso del back-end, tuttavia, abbiamo detto che è accessibile solo a chi sviluppa quel dato servizio, e che dunque ha le credenziali per utilizzarlo. Accedervi senza queste credenziali, oltre a essere molto complesso e non sempre dall’esito certo, è illegale. È per questo che, molto più spesso, conviene puntare alle API. I vantaggi sono molteplici. Innanzitutto, è un metodo legale, e quindi i risultati possono essere sbandierati ai quattro venti senza troppe preoccupazioni.
Poi c’è proprio il discorso sulla semplicità. Benché sfruttare un’Application Programming Interface richieda qualche nozione avanzata, è comunque infinitamente più semplice che imparare a scardinare le protezioni di un servizio web presidiato da fior di professionisti. Senza contare che sulle API, in genere, è disponibile molta documentazione, che ti consente di sfruttarle ben oltre le possibilità per cui sono state progettate. E spingere una tecnologia oltre le possibilità per cui è stata progettata, se ci pensi, è proprio il significato di hacking.
Le API, comunque, non sono il solo modo per ottenere dati e informazioni sfiziose da un social media, uno di quelli che vanno oltre a ciò che siamo abituati a vedere in qualità di comuni mortali. Esiste, infatti, anche la tecnica dello scraping, che in buona sostanza consiste nell’esaminare pagine web a livello di codice sorgente, a caccia di materiale interessante. Alludo, per esempio, alle istruzioni HTML e CSS che compongono una pagina e che spesso, in effetti, celano utili informazioni su siti web, pagine, account e altro ancora.
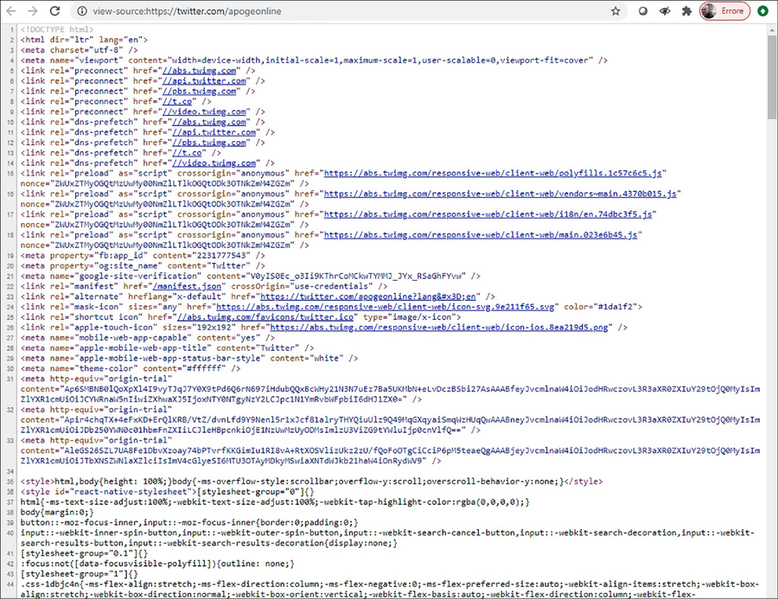
Lo scraping (raschiatura) è una tecnica con la quale si estraggono informazioni da un servizio web sfruttandone ogni elemento esposto al pubblico. Per esempio, analizzando il codice sorgente che compone le pagine di un sito. In questa immagine, il codice sorgente che compone la timeline Twitter di @apogeonline nel momento in cui scrivo.
Twitter, Facebook, Instagram e non solo
Le API hanno l’indubbio vantaggio di offrire informazioni senza dover tenere conto dell’architettura specifica di un social media o di un servizio web in genere. Questo perché rappresentano una vera e propria finestra su alcuni degli innumerevoli processi che, dietro le quinte, muovono un sistema così complesso, composto da migliaia e migliaia di componenti software e hardware.
Pensa che la descrizione dettagliata della sola tecnologia che muove il motore di ricerca di Facebook, quello che utilizzi per cercare per esempio un utente, richiederebbe un intero (e grosso) libro. E parliamo solo di una piccola porzione della sua struttura. Ciò non toglie, tuttavia, che l’utilizzo combinato di API e analisi del codice del front-end regali soddisfazioni immense per chi va a caccia di informazioni utili per investigazioni, marketing e molto altro.
Questo articolo richiama contenuti da Social Media Mining.
Immagine di apertura di Marvin Meyer su Unsplash.
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Corsi che potrebbero interessarti

Comunicazione digitale Food & Wine - Iniziare Bene

Machine Learning & Big Data per tutti

Data governance: diritti, licenze e privacy
Libri che potrebbero interessarti

Social Media Mining
L'arte di estrarre e analizzare dati da Facebook & Co.