

Di che cosa parliamo
- Che cos’è la data analytics
- Chi fa data analytics
- Quali sono i tool per fare data analytics
- Come fare business mediante la data analytics
- Come muoversi in KNIME
Che cos’è la data analytics
Il termine data analytics è normalmente utilizzato per indicare i metodi e le tecniche adoperate per estrarre valore dai dati. A volte, lo stesso termine denota invece gli strumenti utilizzati per questa estrazione. In ogni caso, la data analytics rappresenta il come siamo in grado di trasformare i dati grezzi in qualcosa di più utile e prezioso. Possiamo riconoscere tre diversi tipi di data analytics, ognuno dei quali è caratterizzato da una sua prerogativa specifica e da un insieme di possibili applicazioni pratiche: i tipi sono descriptive, predictive e prescriptive analytics.
Descriptive analytics
La descriptive analytics è l’immancabile punto di partenza di qualsiasi sforzo analitico in azienda. Queste metodologie si concentrano sulla descrizione dei dati passati per renderli digeribili e offrire un modo per capire e interpretare lo stato del business. Rispondono alla domanda generica che cosa è successo attraverso la predisposizione di tabelle e grafici, arricchiti dall’uso di statistiche riassuntive (come media, mediana e varianza), semplici trasformazioni e aggregazioni di valori (come indici, conteggi e somme).
Il prodotto iconico (e anche il più elementare) associato alla descriptive analytics è il report statico: questo può essere costituito da un semplice file in qualsiasi formato (documenti PDF e fogli Excel sono i più ricorrenti) che viene distribuito su base regolare via e-mail o pubblicato su una piattaforma di distribuzione. La maggior parte dei manager ama il comfort dei report statici: lì possono trovare tutti i Key Performance Indicator (KPI) di interesse a portata di mano, con uno sforzo davvero minimo. Grazie ai tradizionali report, i manager non hanno bisogno di andare a cercare nulla: sono dati che arrivano da soli e proprio nel formato di cui hanno normalmente più bisogno.
Un prodotto più sofisticato nell’ambito dell’analitica descrittiva è la dashboard interattiva: in questo caso, gli utenti accedono a un’interfaccia web che li guida attraverso i dati di loro interesse. Grafici e tabelle mostreranno gli aspetti più rilevanti del business, mentre filtri, selettori e pulsanti offriranno agli utenti la possibilità di personalizzare la loro indagine, approfondendo gli aspetti che più li incuriosiscono. A volte, i cruscotti sono progettati specificamente per dare al top management una visione d’insieme dello stato del business, concentrandosi solo sui KPI più importanti: in questo caso, le dashboard sono conosciute con il nome più pittoresco di management cockpit (o cruscotti decisionali).
Per mettere a fuoco le differenze tra le varie analitiche descrittive, facciamo un’analogia turistica: se il report tradizionale offre un tour guidato all-inclusive, costituito da tappe preimpostate e non modificabili (se non ridisegnando il report, con tutte le complessità da affrontare e le tempistiche richieste dal cambio), le dashboard interattive permettono di scorrazzare autonomamente attraverso i dati, offrendo la possibilità di intraprendere percorsi insoliti.
Anche se questi ultimi detengono più potenziale strategico in virtù della maggiore versatilità che offrono, alcuni manager meno avventurosi (e in cerca di viste statiche e facili da confrontare nel tempo) preferiranno ancora la comodità di ricevere report tradizionali direttamente nella loro casella di posta. Per soddisfare entrambe le esigenze contemporaneamente, le dashboard possono essere impostate in modo da offrire notifiche attraverso il meccanismo delle subscription: in questo caso, gli utenti possono iscriversi per ricevere una selezione di immagini o tabelle dalla dashboard via e-mail con una certa frequenza regolare o non appena i dati vengono aggiornati. Le subscription sono una funzionalità molto promettente in quanto evitano la duplicazione degli sforzi nell’aggiornamento delle dashboard e nella diffusione dei report.
Predictive analytics
I metodi di predictive analytics si concentrano sulla risposta alle domande supplementari che ci si pone naturalmente dopo aver appreso ciò che è successo in passato, ovvero: perché è successo? e che cosa succederà?. Queste metodologie fanno leva su tecniche analitiche più sofisticate, talvolta basate sull’intelligenza artificiale, in quanto dovranno necessariamente andare oltre la semplice descrizione dei fatti storici e avventurarsi nella creazione di modelli probabilistici.
Grazie alla predictive analytics possiamo tentare di svelare le relazioni che intercorrono tra dati diversi ed estrapolarle opportunamente in modo da anticipare un futuro possibile. Al gradino più basso tra gli strumenti di predictive analytics troviamo gli strumenti diagnostici: questi sono in grado di arricchire i report descrittivi con indicatori che cercano di spiegare le cause di quello che osserviamo nei dati. Utilizzando metodi semplici come l’analisi di correlazione, le carte di controllo (o control chart) e i test statistici, questi strumenti diagnostici possono evidenziare degli schemi rilevanti, facendo luce sulle ragioni per cui, per esempio, il business stia andando in un certo modo.
Il livello successivo di raffinatezza è costituito dai business alert: in questo caso, i controlli diagnostici vengono eseguiti automaticamente e gli utenti ricevono una notifica solo quando si verifica qualche situazione degna di nota per il business (come, per esempio, il fatto che la quota di mercato di un marchio scenda sotto una certa soglia). In maniera simile, gli strumenti di anomaly detection (rilevazione delle anomalie) sono in grado di ispezionare continuamente i dati alla ricerca di incongruenze e fenomeni atipici che, una volta segnalati, possono essere gestiti opportunamente: per esempio, i dati generati dai sensori lungo una linea di produzione industriale possono essere utilizzati per anticipare possibili malfunzionamenti e attivare la manutenzione necessaria.
L’analitica predittiva include anche metodi per anticipare il futuro generando forecast (previsioni) di grandezze rilevanti come le vendite, il prezzo, le dimensioni del mercato e il livello di rischio, le quali possono certamente aiutare i manager a prendere decisioni migliori e prepararsi per ciò che è in procinto di avvenire. Grazie a questi strumenti, anche il comportamento di clienti e concorrenti può essere anticipato, producendo un chiaro vantaggio competitivo e impattando positivamente il ritorno sugli investimenti (Return on Investment, ROI) futuri.
Nel caso dei propensity model (modelli di propensione), gli algoritmi di intelligenza artificiale vengono adoperati per prevedere quanto un determinato cliente apprezzerà una specifica offerta commerciale o quanto è possibile che abbandoni il nostro negozio o servizio (churn), consentendoci di mettere in piedi e tarare le nostre attività di fidelizzazione (retention).
Un ultimo esempio di predictive analytics è quello delle segmentazioni: in questo caso, utilizziamo gli algoritmi per raggruppare clienti, negozi o prodotti che mostrano un certo grado di somiglianza tra loro. Gestendo questi gruppi omogenei in maniera definita possiamo rendere i nostri processi più snelli e migliorare l’esperienza dei nostri clienti facendola diventare personalizzata e più coinvolgente.
Prescriptive analytics
Se descriptive e predictive analytics guardano al passato e ci offrono una possibile vista del futuro, gli strumenti di prescriptive analytics fanno un passo oltre e ci indicano direttamente quali azioni mettere in campo per raggiungere un determinato obiettivo, rispondendo quindi alla domanda clou che ogni manager aziendale si pone continuamente: che cosa fare?. Per esempio, uno strumento prescrittivo potrebbe simulare un gran numero di scenari alternativi e vagliarli sistematicamente per restituirci la migliore ricetta da seguire in modo da massimizzare il profitto o minimizzare i costi.
Un altro esempio di strumenti analitici prescrittivi sono i cosiddetti recommendation system (o sistemi di raccomandazione): essenzialmente, forniscono agli utenti raccomandazioni sui prodotti. Questi algoritmi sono praticamente onnipresenti nella nostra esperienza digitale quotidiana. Quando facciamo acquisti su Amazon o siamo in procinto di selezionare la prossima serie TV da guardare tutta d’un fiato su Netflix, ci viene presentato un insieme (limitato) di opzioni particolarmente aderenti ai nostri gusti: tutto questo avviene attraverso sistemi di raccomandazione nei quali un algoritmo è in grado di scremare le scelte più promettenti.
Il livello più sofisticato di analytics prescrittive entra in gioco nel momento in cui gli algoritmi non si limitano a raccomandarci che cosa fare ma… si mettono a farlo! Pensiamoci un attimo: alcune microdecisioni necessarie al funzionamento di un processo di business potrebbero essere prese in real time, senza dare il tempo a un essere umano di approvare in maniera esplicita ogni singola raccomandazione elaborata dalla macchina.
In qualche caso, gli algoritmi sono progettati per comportarsi come agenti autonomi, incaricati di imparare continuamente attraverso un processo iterativo. Questi algoritmi testano continuamente la loro strategia d’azione nel mondo reale e la correggono opportunamente di volta in volta che i vari tentativi vanno a buon fine (o falliscono), cercando di massimizzare i rendimenti cumulativi prodotti dalle decisioni. Questo è proprio il caso, per esempio, del trading automatizzato (una tendenza in forte crescita nell’ambito della tecnofinanza, o FinTech) e del programmatic advertisement (ovvero dell’acquisto in tempo reale di pubblicità digitale attraverso un complesso meccanismo di aste automatizzate).
Questa figura mostra il compromesso tra il valore potenziale e la complessità da gestire nel mettere in campo questi diversi tipi di analytics.
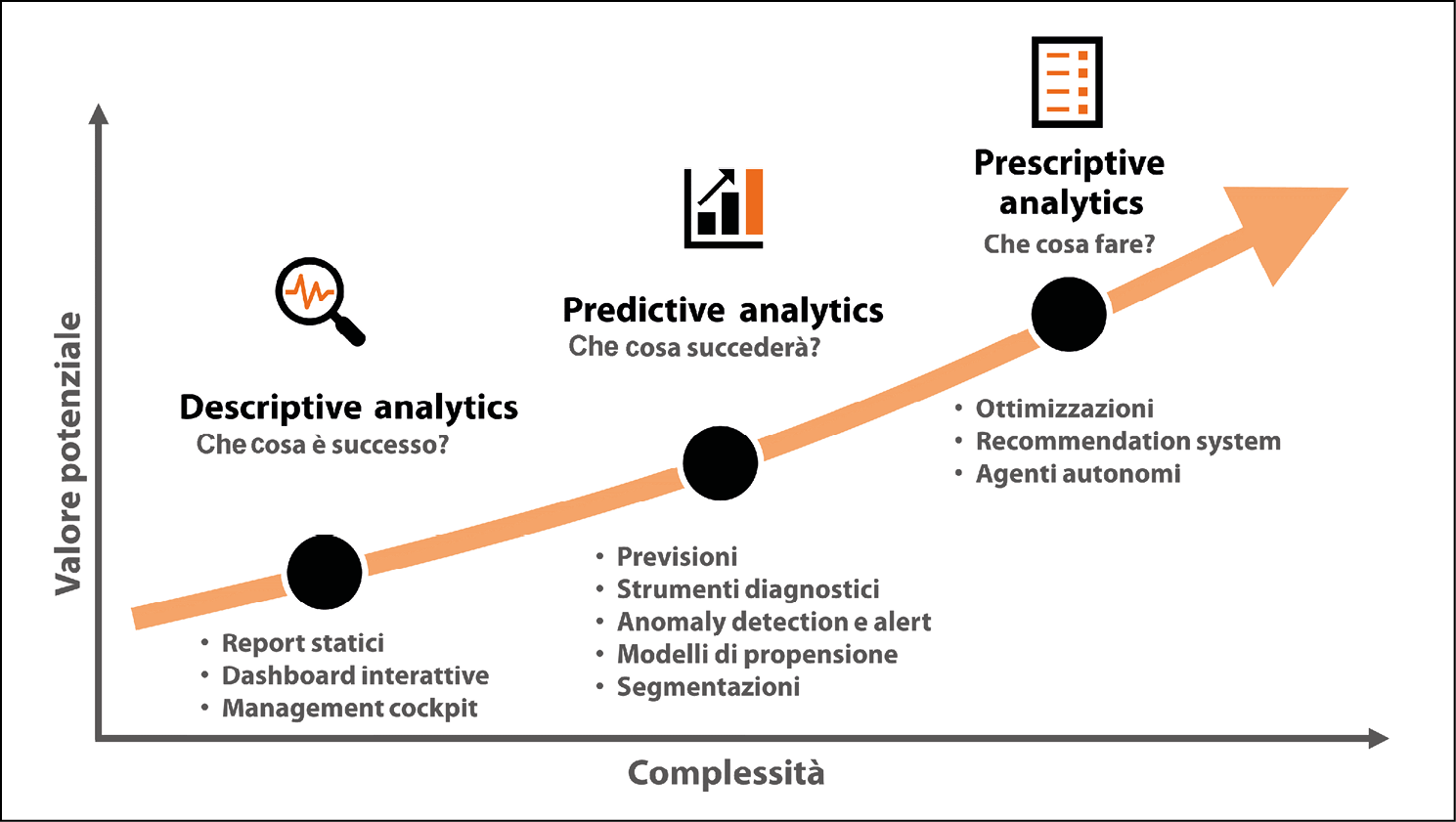
I tre tipi di data analytics: quanto valore vogliamo sbloccare e quanta complessità siamo in grado di affrontare?
Chi fa data analytics
La risposta breve al titolo di questa sezione è anche la più ovvia: tutti hanno un ruolo da svolgere nella data analytics, nessuno può tirarsi indietro! Infatti, tutti i knowledge worker hanno senza dubbio a che fare con i dati in qualche aspetto del loro lavoro: potrebbero interagire con le analytics in qualità di utenti di qualche dashboard o lettori di report oppure, all’altro estremo, potrebbero essere i principali creatori di una capability avanzata. Possiamo riconoscere quattro famiglie di ruoli professionali legati alla data analytics in azienda, ciascuna avente una funzione specifica e un insieme di competenze caratterizzanti.
- Gli utenti di business di qualsiasi funzione e livello, compresi i senior manager, interagiscono con la data analytics in una qualche misura. Anche se il loro ruolo principale è quello di fruitori, queste persone traggono grandi benefici dall’avere una comprensione di base delle tecniche di data analytics. Questa consapevolezza, seppur superficiale, si integrerà con le loro conoscenze aziendali e permetterà alle persone focalizzate sul business di prendere il meglio dai loro dati, interpretandoli correttamente e comunicandone il valore attraverso visualizzazioni e storie efficaci. Inoltre, la loro produttività personale sarà positivamente influenzata dall’essere in grado di automatizzare le proprie attività di pulizia e macinazione dei dati usando macro in Excel o creando workflow in KNIME. Infine, questi utenti dovrebbero avere una comprensione di massima di ciò che le advanced analytics potrebbero fare per loro, acquisendo i concetti fondamentali dell’apprendimento automatico e, in generale, dell’intelligenza artificiale. È ovvio che queste persone non avranno bisogno di diventare esperte. Tuttavia, finché non vedranno che cosa è possibile, non saranno in grado di anticipare le opportunità di applicazione della data analytics su quegli aspetti del business talvolta specifici e che solo loro conoscono approfonditamente.
- I business analyst (o data analyst) svolgono un ruolo fondamentale: mettere in connessione i due mondi, apparentemente separati e distanti, del business e dei dati. Hanno una comprensione molto solida delle dinamiche di business (mercato, clienti e concorrenti, processi e così via) poiché sono costantemente in contatto con i partner appartenenti a tutte le aree funzionali (come vendite, marketing, finanza e così via). Grazie al loro forte background aziendale, possono intercettare proattivamente le opportunità per la data analytics di fare la differenza e sono in grado di tradurre le esigenze di business in requisiti tecnici da soddisfare. I business analyst sono abili utilizzatori delle tecniche di data analytics (poiché devono essere in grado di estrarre insight, ovvero intuizioni rilevanti per il business, partendo da grandi quantità di dati) e di quelle di data storytelling (in quanto hanno bisogno di comunicare efficacemente gli insight in loro possesso). Nel contempo, sono capaci di usare strumenti e tecniche di machine learning e, all’occorrenza, saranno in grado di creare prototipi di capability analitiche avanzate, prima di passare il testimone nelle mani dei data scientist. Anche se non è strettamente richiesto e non è un punto focale per il loro lavoro, i business analyst possono trarre grande vantaggio dal saper scrivere codice in uno o più linguaggi di programmazione, in modo da costruire semplici query per l’estrazione di dati e script per la loro trasformazione.
- I data scientist predispongono capability di advanced analytics. Si propongono di essere i maggiori esperti in azienda di algoritmi di apprendimento automatico e possono implementare analisi predittive e prescrittive partendo da zero o costruendo sulla base di prototipi già esistenti. Collaborano attivamente con i business analyst, attraverso i quali riescono a mantenersi in contatto con le necessità di business più rilevanti, e con i data engineer, che fungono da partner principali nell’assicurare sostenibilità e scalabilità delle capability. Questi scienziati dei dati sono abili nel programmare e sono in grado di codificare processi complessi di trasformazione di dati e di utilizzare al meglio le librerie di machine learning più avanzate.
- I data engineer (e i ruoli a essi correlati, come i system engineer e i data architect) assicurano il funzionamento sistematico di data analytics prendendosi cura della progettazione, l’implementazione e la gestione dell’infrastruttura tecnologica necessaria. Il lavoro degli ingegneri dei dati è essenziale per costruire pipeline ovvero flussi di dati che siano stabilmente disponibili per le applicazioni analitiche. Essi interagiscono sia con i data scientist, per dimensionare adeguatamente le risorse computazionali e di memorizzazione necessarie e per progettare un’adeguata architettura dei dati, sia con il resto della funzione Information Technology (IT), per garantire la compatibilità della piattaforma dati utilizzata per la data analytics con i vari sistemi aziendali e assicurare standard accettabili di information security.
Questi quattro soggetti (le cui competenze sono riassunte nella tabella che segue), ognuno con la sua parte specifica da svolgere, copriranno insieme la stragrande maggioranza delle interazioni con l’analitica dei dati in un’azienda.
| Ruolo | Conoscenza verticale del business |
Data analytics e storytelling |
Machine learning | Programmazione | Architettura dati |
|---|---|---|---|---|---|
| Business user | ★ ★ ★ | ★ | ★ | ||
| Business analyst | ★ ★ | ★ ★ ★ | ★ ★ | ★ | |
| Data scientist | ★ | ★ ★ ★ | ★★★ | ★ | |
| Data engineer | ★ ★ | ★★ | ★ ★ ★ |
Matrice ruoli-competenze dei quattro soggetti della data analytics in azienda.
Qualunque sia il personaggio cui ci sentiamo più vicini, abbiamo certamente un ruolo da svolgere nell’estrazione di valore dai dati.
Quali sono i tool per fare data analytics
Fra tutte le tecnologie legate all’analisi dei dati, l’ambito delle applicazioni è dove avviene la magia: le applicazioni di data analytics permettono di trasformare i dati in effettivo valore per il business.
L’offerta odierna di applicazioni di data analytics è vastissima: c’è davvero l’imbarazzo della scelta. Tutte queste applicazioni, ciascuna con i suoi punti di forza e le sue peculiarità, sono potenzialmente interessanti da esplorare. Malgrado i tanti proclami delle aziende che operano nel settore, la realtà con la quale dobbiamo fare i conti è che nessuna applicazione può, da sola, soddisfare l’intero ventaglio di esigenze analitiche di cui una qualsiasi organizzazione possa avere bisogno. Di conseguenza, il nostro compito è effettuare una selezione di quel sottoinsieme di strumenti che, nel loro complesso, riescano a coprire una parte accettabile delle nostre necessità: questi strumenti selezionati andranno a formare la nostra cassetta degli attrezzi per la data analytics.
Leggi anche: Data analytics significa anche data visualization, di Andrea De Mauro
Così come un idraulico ha le sue predilezioni sugli attrezzi da usare nel proprio lavoro, così anche noi avremo le vostre preferenze e, data la vasta disponibilità di strumenti tra i quali selezionare, potremo personalizzare a piacere la nostra cassetta degli attrezzi. Ovviamente dovremo assicurarci di scegliere il giusto mix di attrezzi, in modo da coprire al meglio le nostre esigenze attuali, anticipando anche quelle che verosimilmente avremo in futuro. Scopriamo quali sono i quattro tipi di applicazioni analitiche tra le quali selezionare quelle che faranno parte della nostra cassetta.
- Fogli di calcolo: malgrado questi strumenti abbiano una capacità di analisi abbastanza limitata, le applicazioni di fogli di calcolo sono onnipresenti nelle nostre aziende vista la loro facilità d’uso e la loro estesa portabilità che facilita la condivisione dei dati con i colleghi. Chiunque in azienda è in grado di aprire un file di Microsoft Excel (o la sua alternativa open source LibreOffice Calc, o un servizio basato su cloud come Google Sheets) e aggiungere semplici formule di calcolo o aggregazioni attraverso delle pivot. Questi strumenti sono anche molto utili quando abbiamo bisogno di creare semplici visualizzazioni grafiche: il loro livello di personalizzazione del design di grafici e tabelle copre bene molte delle esigenze quotidiane di manipolazione e presentazione dei dati. Nel contempo, i fogli di calcolo sono inadeguati alla creazione di flussi di dati robusti e automatizzati: aggiornare anche un semplice report creato in Excel richiede passaggi manuali ed è soggetto a errori umani.
- Business intelligence: queste sono le applicazioni più adatte a creare dashboard interattive. Strumenti quali Microsoft Power BI, Qlikview/Qlik Sense, Microstrategy, Tableau, TIBCO Spotfire e Google Data Studio, permettono di implementare applicazioni interattive user-friendly e permettono di democratizzare i dati, rendendoli accessibili a chi ne ha bisogno. Queste applicazioni sono dotate di una vasta scelta di tipi di grafico da implementare e hanno la possibilità di collegare logicamente le varie visualizzazioni tra di loro in modo da permettere un’esperienza di esplorazione guidata dei dati. Pur offrendo la possibilità di applicare algoritmi di machine learning all’interno delle dashboard, questi strumenti da soli non sono in grado di abilitare l’advanced analytics. Il loro punto di forza è sicuramente l’abilitazione della descriptive analytics e la possibilità di metterla a disposizione su vasta scala in azienda.
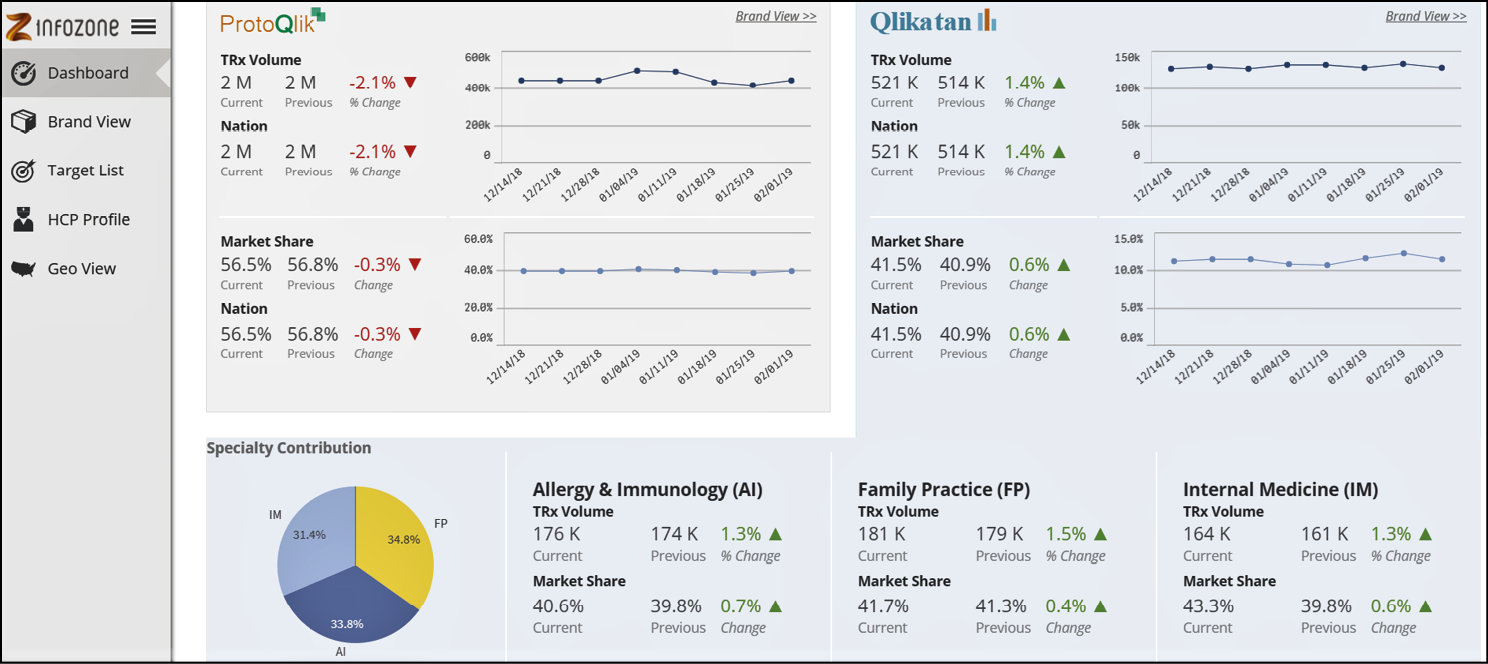
Una dashboard costruita con Qlik Sense: il pannello di navigazione a sinistra guida attraverso i diversi aspetti da visualizzare.
- Low-code analytics: questi strumenti consentono di costruire rapidamente soluzioni avanzate di data analytics senza dover scrivere codice (per questo si chiamano low-code o no-code), utilizzando il paradigma del visual programming, ovvero della programmazione visuale. Il loro segreto è l’interfaccia utente basata sul concetto di workflow: con questi strumenti possiamo assemblare un diagramma di flusso costituito dai vari passi di trasformazione dati di cui aabbiamo bisogno, ottenendo così un’applicazione di analytics completamente funzionante in tempi record. Grazie alla loro interfaccia intuitiva e al fatto che possano essere utilizzati senza essere esperti in un linguaggio di programmazione, applicazioni come KNIME, RapidMiner e Alteryx Designer possono essere utilizzate sia da professionisti esperti dei dati (come data scientist e business analyst, che ne fanno uso per prototipare velocemente soluzioni di advanced analytics) sia da business user che vogliano andare oltre Excel e semplificare il loro lavoro manuale (e spesso noioso) di pulizia, trasformazione e analisi dei dati.
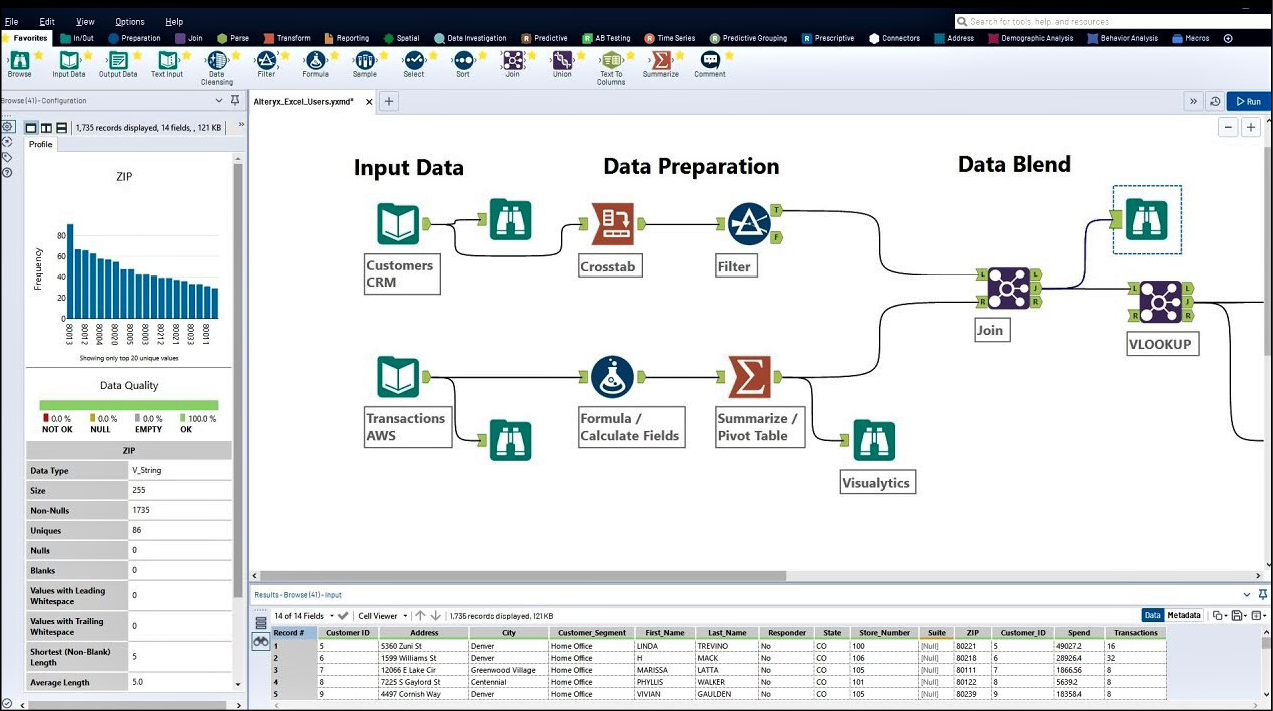
L’interfaccia utente di Alteryx Designer: ogni icona è un passo di trasformazione singolo, parte di un workflow più complesso.
- Code-based analytics: l’approccio più tradizionale per l’advanced analytics è scrivere codice usando linguaggi di programmazione particolarmente adatti per la data science come Python, R e Scala. Considerando la vasta disponibilità di librerie di machine learning scritte in questi linguaggi, un data scientist può usarli per costruire soluzioni di analisi altamente personalizzate ed efficienti. Queste soluzioni possono anche essere incorporate in applicazioni real-time, connesse con tutti gli altri sistemi del panorama IT aziendale. Per costruire applicazioni di analytics basate sul codice, i professionisti dei dati utilizzano ambienti di sviluppo integrati (o IDE, Integrated Development Environment) come Rstudio per R e Jupyter Notebook, Visual Studio o PyCharm per Python.
Come abbiamo già detto, una buona cassetta degli attrezzi per la data analytics avrà bisogno di diverse tipologie di strumenti. In effetti, non dobbiamo considerare questi quattro tipi di applicazioni come alternative tra cui scegliere. È proprio il contrario: i loro punti di forza e di debolezza sono complementari e si compensano appieno solo integrandone l’utilizzo.
Facciamo un esempio pratico che ci permetta di vedere questi strumenti in azione: Greta è la business analyst che focalizza il suo lavoro di analisi sulla supply chain di una casa automobilistica multinazionale. Greta ha bisogno di mettere in piedi rapidamente una data capability in grado di prevedere la domanda futura delle varie componenti necessarie alla produzione e di metterla a disposizione dei team di purchasing e dei direttori di stabilimento in tutto il mondo. Greta decide di costruire un workflow in KNIME che estrae lo storico delle richieste di componenti da alcuni database aziendali (purtroppo scollegati tra loro) e li integra con l’inventario corrente. Dopo una fase iniziale di esplorazione, Greta costruisce un modello predittivo della domanda utilizzando le funzionalità native di KNIME e, successivamente, lo ottimizza aggiungendo alcune linee personalizzate di codice Python direttamente in KNIME.
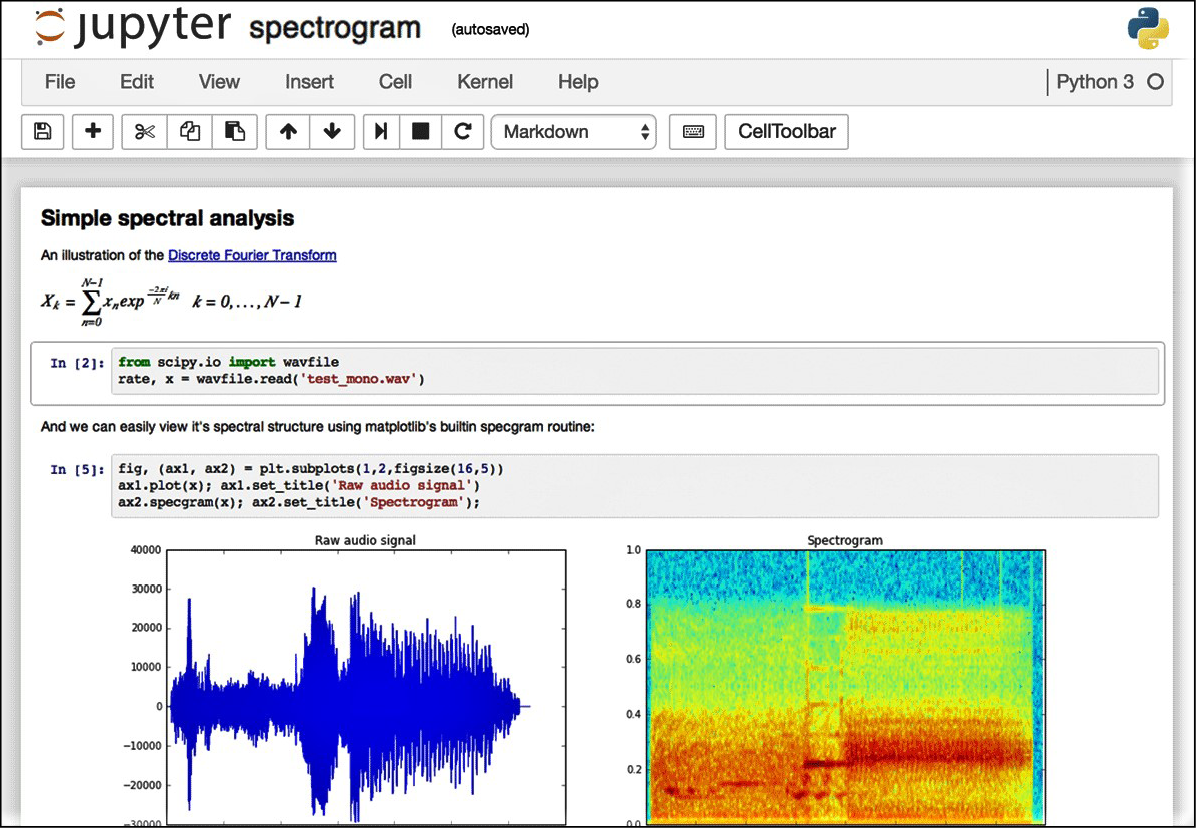
Una schermata di un Jupyter Notebook: grazie a questa applicazione si può scrivere ed eseguire codice Python dal browser, attraverso un’interfaccia web.
A questo punto, Greta completa il suo flusso di lavoro con le ultime fasi di pulizia ed esporta i risultati della previsione direttamente in un dataset di Power BI. Infine, Greta costruisce una semplice dashboard costituita da alcune tabelle e semplici grafici (per lo più diagrammi a barre) in Power BI. Nella sua semplicità, questa dashboard permette agli utenti finali di esplorare i dati, filtrarli per la loro area di interesse, ed esportarli in un pratico file Excel per ulteriori analisi e condivisioni.
Greta è stata in grado di eseguire rapidamente questo lavoro perché ha usato tutta la sua cassetta degli attrezzi per la data analytics, costituita nel suo caso da KNIME, Power BI, e un po’ di Python. Greta ha scelto molto bene quali strumenti utilizzare per ogni passaggio, sfruttando i loro punti di forza e adattandoli al business case specifico. Senza una cassetta degli attrezzi a portata di mano, Greta avrebbe fatto davvero molta fatica a soddisfare questa esigenza di business in un tempo così rapido.
La storia di Greta ci mostra con chiarezza la necessità di costruire una cassetta degli attrezzi versatile e completa per l’analisi dei dati. Qualunque sia il nostro ruolo in azienda, il mio consiglio è di fare come Greta e di dotarci di una selezione di strumenti complementari per trasformare, arricchire, modellare e visualizzare i dati, in modo da beneficiare appieno della data analytics anche nelle esigenze più semplici del lavoro quotidiano.
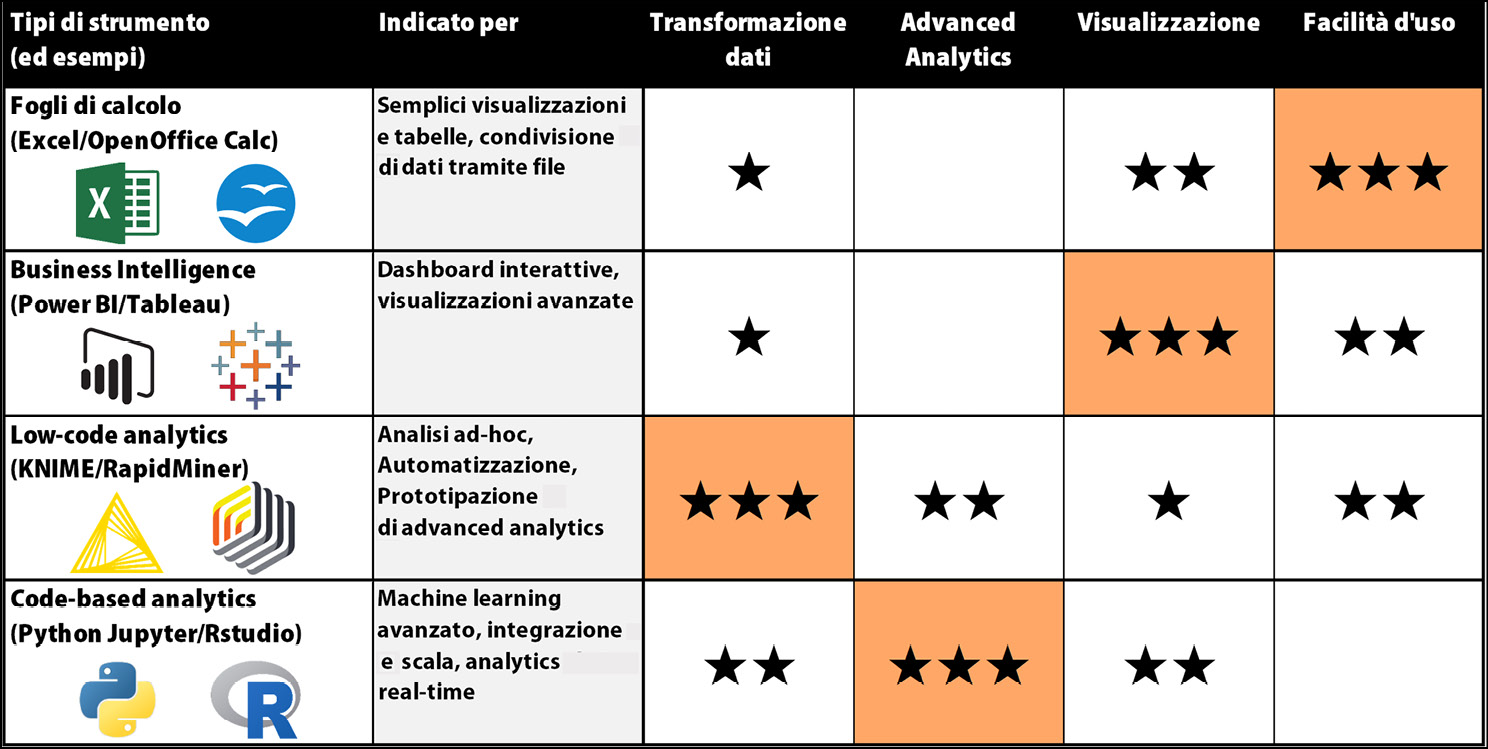
Un confronto tra i quattro tipi di strumenti per la data analytics: che cosa inseriremo nella nostra cassetta degli attrezzi?
Come fare business mediante la data analytics
I dati sono nulla senza la possibilità di essere trasformati in valore. Per quanto sofisticato e accurato sia il modello di machine learning che costruite, per quanto profondi siano gli insight che riuscite a svelare, i dati faranno la differenza solo nel momento in cui risultano in un’azione concreta che abbia un impatto positivo sul business.
La dura realtà delle nostre aziende è che sia molto più difficile ottenere un’azione, predisporre un cambio o far prendere una certa decisione di quanto non lo sia costruire una dashboard o sviluppare un’analisi avanzata. La buona notizia è che esistono non uno ma diversi modi alternativi per ottenere un impatto sul business con la data analytics: li chiameremo percorsi data-to-value, perché ci indicano delle possibili strade da seguire per creare valore in maniera sistematica. È importante ragionare su questi percorsi insieme prima di iniziare a lavorare sui dati, in modo da poter massimizzare fin da subito la rilevanza per il business di ciò che facciamo. I tre percorsi data-to-value più frequenti che si possono incontrare nel business sono i seguenti.
- Analisi ad-hoc: in questo caso si utilizzano i dati per influenzare una decisione specifica o per far luce su un’opportunità o una minaccia unica. Questo è il percorso più dispendioso in termini di tempo poiché richiede certamente molta interazione umana ma è, nel contempo, molto potente e gratificante. Attraverso l’esplorazione dei dati e, se necessario, facendo leva su alcuni algoritmi predittivi, si inizia il percorso identificando un insight, ovvero un’intuizione nascosta nei dati. Per massimizzare la sua possibilità di impatto, si costruisce poi una storia coinvolgente che sia in grado di portare i decisori a bordo con noi e renderli disposti a prendere la decisione che noi (e i dati) raccomandiamo. Solo quando (e se) questa decisione viene presa e messa in azione saremo nella posizione di rivendicare del valore economico dovuto alla data analytics. Molti insight, anche se di notevole interesse e novità, non hanno mai prodotto alcun valore in quanto questo percorso si è interrotto in una delle sue tappe. A volte la storia non è ben preparata e raccontata, così una buona raccomandazione finisce nella frustrante situazione di rimanere inascoltata. In altri casi, i piani raccomandati non vengono eseguiti perché non sono stati ben spiegati o non sono legati a modalità concrete di tracking ovvero di tracciamento del progresso.
- Business intelligence: quando si segue questo percorso, il nostro obiettivo è illuminare sistematicamente i colleghi con informazioni rilevanti. Questo garantirà loro di avere una marcia in più nell’esecuzione del loro lavoro e nella presa di decisioni regolari e ciò porterà, in definitiva a incrementare sistematicamente il valore prodotto dal loro lavoro. Per mezzo di strumenti di descriptive analytics e, quando necessario, utilizzando alcuni algoritmi che permettano di diagnosticare lo stato del business, faremo in modo che i dati parlino forte e chiaro attraverso chiare visualizzazioni e, talvolta, notifiche di business alert. Arricchendo gli altri attraverso l’analisi dei dati, si generano azioni migliori e, quindi, si aggiunge valore incrementale per il business il cui merito andrà indubbiamente assegnato alla data analytics e al nostro lavoro. Questo percorso data-to-value potrebbe apparire meno sofisticato degli altri (non meno complesso, data la difficoltà di organizzare sistematicamente i dati per poterli mettere a disposizione di tutti), ma racchiude indubbiamente un enorme potenziale di creazione di valore in quanto può incidere sul lavoro di molte persone e lo fa senza sosta.
- Ottimizzazione automatica: quando si prende questa strada, si usano gli strumenti di prescriptive analytics per ottenere un piano di azioni da intraprendere che viene anche eseguito in maniera automatica. In questo caso, i dati e gli algoritmi non stanno informando gli altri o raccomandando una linea d’azione: sono catapultati direttamente sul sedile del conducente e possono guidare autonomamente l’esecuzione dei processi aziendali. Il beneficio potenziale è vasto poiché gli algoritmi possono ottimizzare continuamente le prestazioni delle operazioni aziendali senza alcun intervento umano o, al massimo, con qualche supervisione di moderata entità.
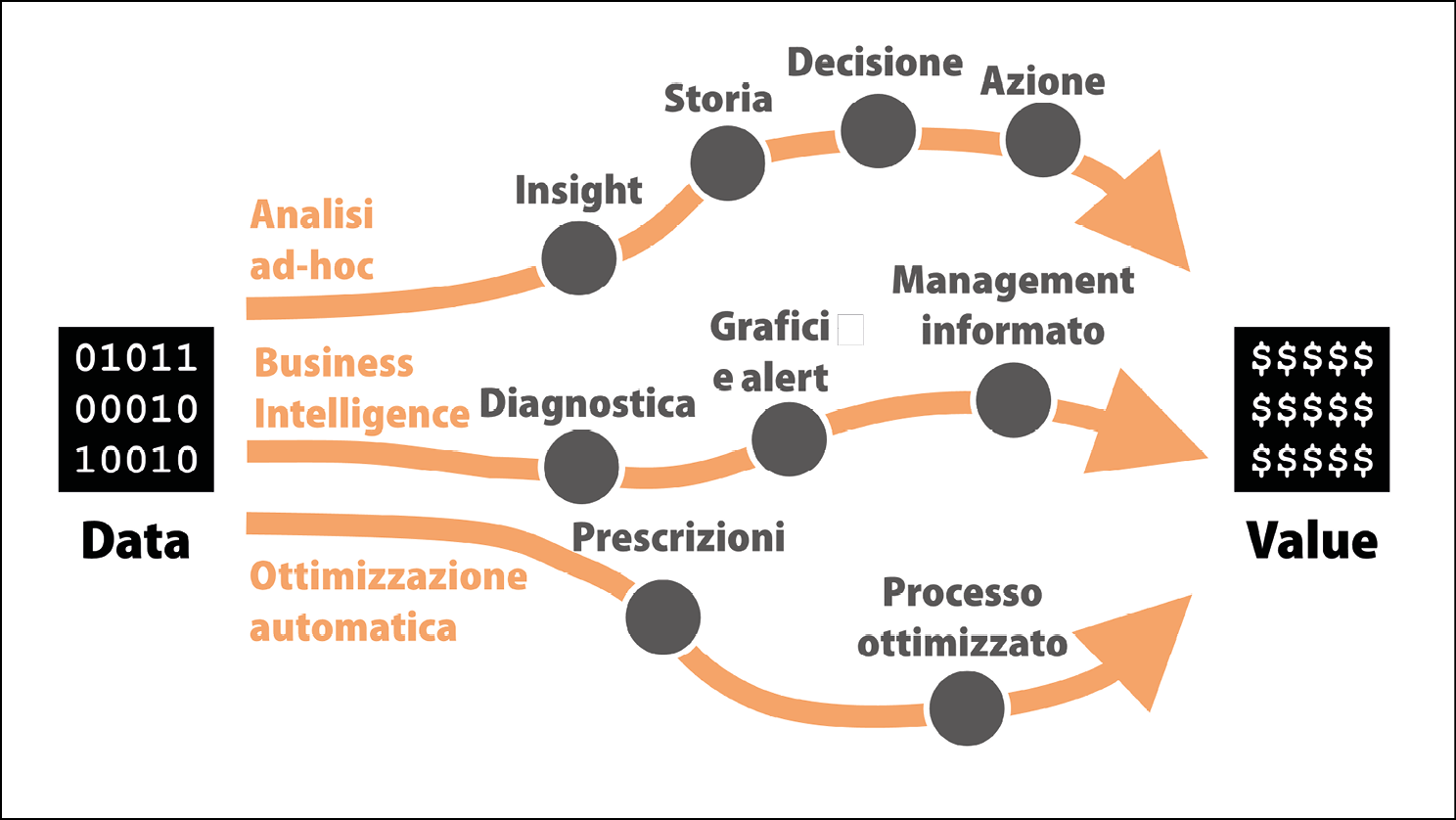
I tre percorsi data-to-value più frequenti: quale seguiremo per primo?
È importante tenere a mente questo semplice schema e identificare quale percorso data-to-value stiamo per affrontare, di volta in volta. A seconda del percorso che prendiamo, potremmo aver bisogno di implementare un certo tipo di data analytics e recuperare gli strumenti più opportuni dalla nostra cassetta degli attrezzi. In ogni caso, avere chiarezza su come vogliamo creare valore per un business massimizzerà le nostre possibilità di successo.
Come muoversi in KNIME
Entrando nel mondo di KNIME, ha senso familiarizzare prima con due parole chiave: nodi e workflow.
- Un nodo è l’unità base di computazione: un nodo implementa una specifica operazione sui dati ovvero un singolo passo in un processo più ampio. Ogni azione che si applica ai dati, come caricare un file, filtrare le righe, applicare una formula o costruire un modello di apprendimento automatico, è raffigurata in KNIME da un’icona quadrata che rappresenta un nodo.
- Un workflow, o flusso di lavoro, è l’intera sequenza di nodi che descrive ciò che vogliamo fare con i nostri dati, dall’inizio alla fine. Per costruire una procedura di data analytics in KNIME dovremo selezionare i nodi di cui abbiamo bisogno e collegarli nell’ordine desiderato.
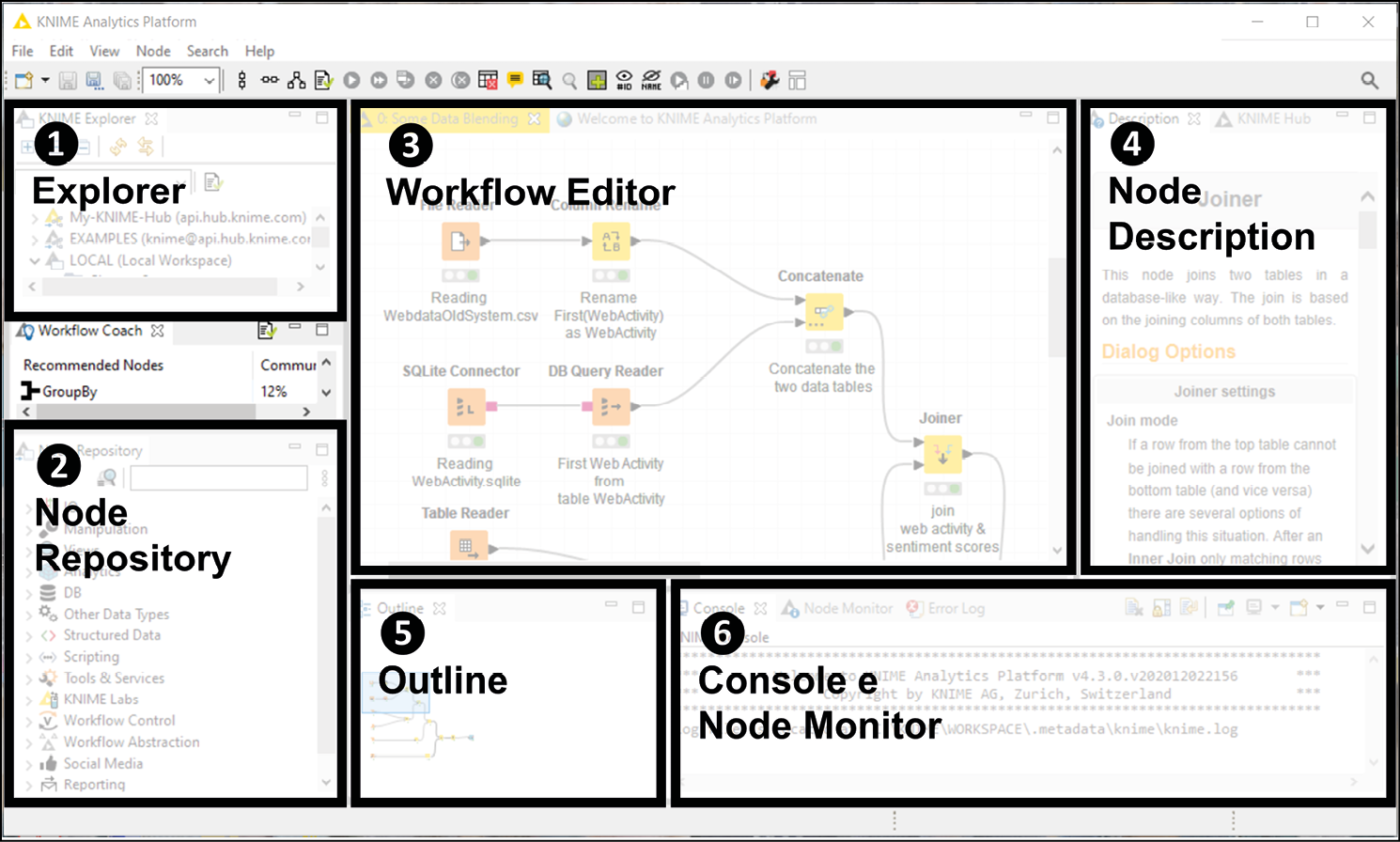
Interfaccia utente di KNIME: ecco il nostro banco di lavoro per fare analytics.
L’interfaccia utente di KNIME ci offre tutto ciò di cui abbiamo bisogno per scegliere i nodi che ci servono e combinarli adeguatamente in un workflow. Percorriamo le sei finestre principali dell’interfaccia utente (rappresentate nella figura qui sopra) che troveremo pronte ad accoglierci non appena avviamo l’applicazione.
- Explorer: qui è dove i workflow sono conservati e organizzati gerarchicamente in una struttura a cartelle. Tra le varie cartelle che troveremo nell’Explorer vi sono: lo spazio di lavoro locale (LOCAL), che contiene le cartelle memorizzate sul computer; il server pubblico KNIME, sul quale troveremo diversi workflow di esempio (EXAMPLES) organizzati per argomento, che possiamo usare per trarre ispirazione e riadattare al nostro bisogno; lo spazio My-KNIME-Hub, collegato al nostro spazio utente sulla piattaforma cloud chiamata KNIME Hub, sulla quale possiamo condividere privatamente o pubblicamente workflow e componenti riutilizzabili (possiamo creare gratuitamente il vostro spazio sull’hub registrandoci gratuitamente su KNIME Hub).
- Node Repository: in questo spazio troveremo il menu completo dei nodi KNIME a nostra disposizione, pronti per essere trascinati al momento del bisogno sui nostri workflow. I nodi sono organizzati in categorie gerarchiche: facendo clic sul segno > a sinistra di ogni intestazione procederemo al livello sottostante. Per esempio, la prima categoria del repository è IO (Input/Output): questa include a sua volta più sottocategorie, come Read, Write e Connectors. Potremo ricercare il nodo di cui abbiamo bisogno digitando alcune parole chiave nella casella di testo in alto a destra. Proviamo a inserire la parola Excel: otterremo tutti i nodi che permettono di importare ed esportare dati nei formati dei fogli di calcolo Microsoft, come
.xlse.xlsx. Così come un pittore ha a disposizione vari colori sulla sua tavolozza, il Node Repository offre l’accesso a tutti i nodi disponibili su KNIME: componendoli a dovere, dipingeremo il nostro workflow.
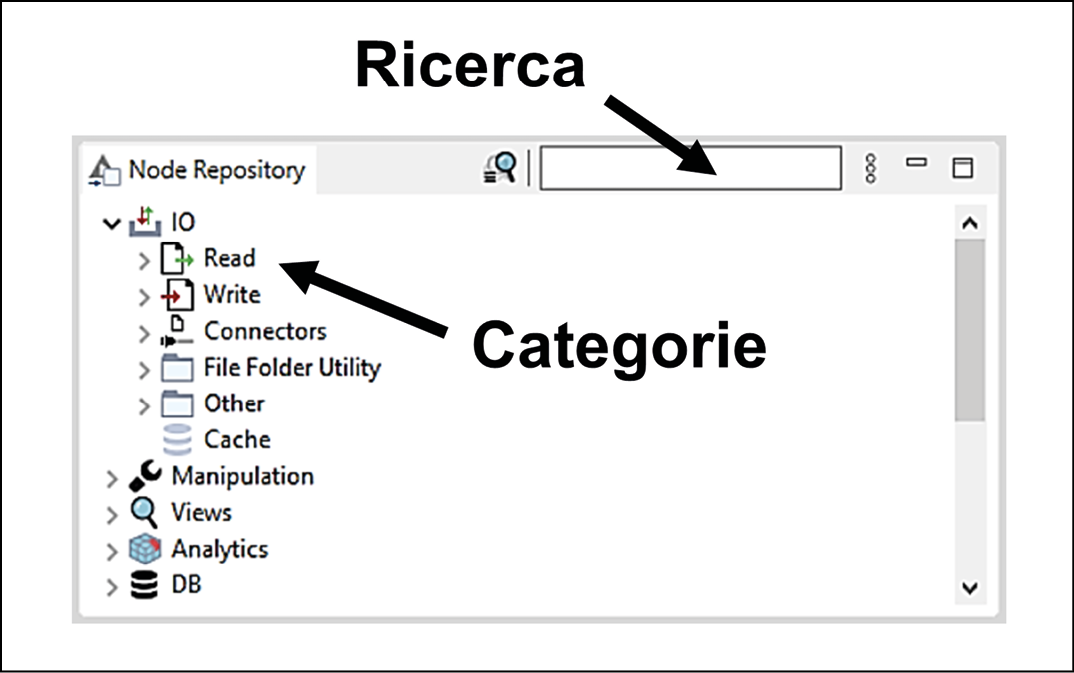
Il Node Repository: tutti i nodi a nostra disposizione ci aspettano qui.
- Workflow Editor: qui potremo dare spazio alla nostra creatività e collegare i nodi di cui necessitiamo per dare vita al workflow. Proseguendo lungo l’analogia che abbiamo iniziato sopra con la tavolozza dei colori, il Workflow Editor rappresenta la tela su cui dipingeremo il nostro capolavoro analitico.
- Node Description: questa finestra è utilissima in quanto offre una guida pratica per l’utilizzo di ciascun nodo in KNIME. Quando facciamo un clic su qualsiasi nodo, sia che si trovi ancora nel repository o già posizionato nel Workflow Editor, la finestra della Node Description presenterà tutto quello che c’è da sapere per usare al meglio il nodo. Tipicamente la descrizione include tre parti: un riassunto di che cosa fa e come funziona, un elenco dei vari passi necessari alla sua configurazione (Dialog Options) e, infine, una descrizione di quali dati ci si aspetta di avere alle porte di ingresso e di uscita del nodo (Ports).
- Outline: il nostro workflow potrà diventare così esteso da non riuscire a visualizzarlo interamente nella finestra del workflow editor. La finestra dell’Outline offre una vista a volo d’uccello del workflow e mostra quale sezione è attualmente visualizzata nell’editor. Trascinando con il mouse il rettangolo blu potremo facilmente spostarci sulla parte del workflow d’interesse.
- Console e Node Monitor: in questa sezione troveremo un paio di strumenti utili per capire se ci sono dei problemi nell’esecuzione del workflow ed eventualmente correggerli attraverso un’attività di debug. Nello specifico, la Console riporta la descrizione degli ultimi warning ed errori ottenuti eseguendo il workflow mentre il Node Monitor offre una vista sintetica dei dati disponibili sulle porte di uscita del nodo attualmente selezionato.
Malgrado queste sei finestre coprano tutte le necessità essenziali, l’interfaccia utente di KNIME mette a disposizione anche altre sezioni di potenziale utilità. Per esempio, sulla sinistra, il Workflow Coach suggerisce i nodi che più probabilmente sarebbe utile aggiungere a valle del nostro attuale workflow, sulla base di ciò che altri utenti di KNIME hanno fatto in passato. Inoltre, nella stessa finestra della Node Description, troveremo un pannello aggiuntivo (cercatene l’intestazione in alto) chiamato KNIME Hub: qui possiamo cercare workflow di esempio, pacchetti aggiuntivi e componenti con le quali arricchire il nostro lavoro, trascinandoli direttamente sul Workflow Editor, proprio come faremmo dal Node Repository.
Nodi
I nodi costituiscono la spina dorsale di KNIME: scopriamo come funzionano e quali tipi di nodi sono a nostra disposizione.
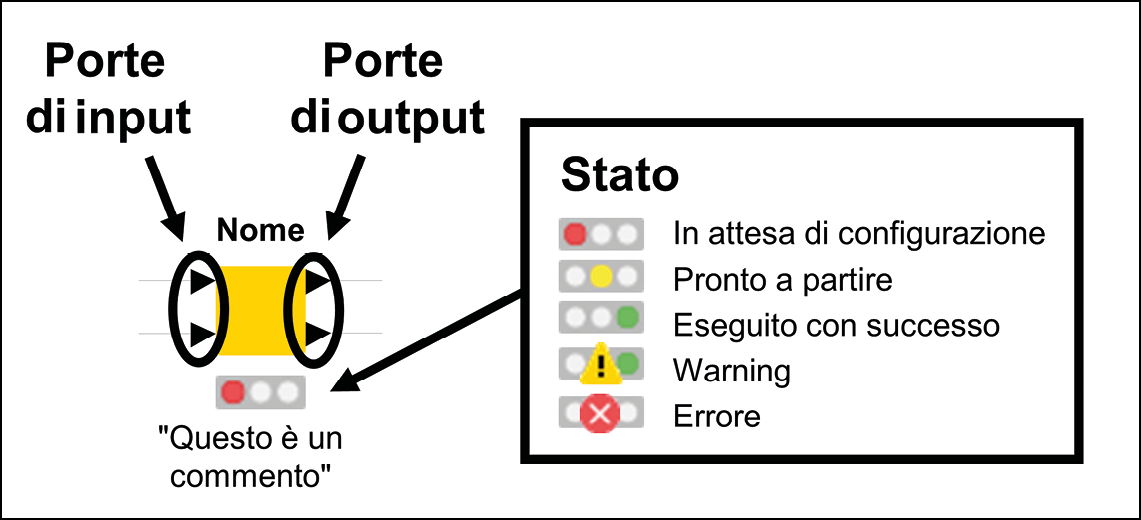
Anatomia di un nodo in KNIME: il semaforo ci dice lo stato attuale.
Come rappresentato nella figura precedente, i nodi sono rappresentati da un’icona quadrata con del testo e delle forme intorno.
- In cima al nodo, troviamo il suo nome in grassetto. Il nome sintetizza, in una manciata di parole, che cosa fa quel tipo di nodo. Per esempio, per rinominare alcune colonne in una tabella usiamo il nodo chiamato Column Rename.
- Nella parte inferiore del quadrato, troviamo un commento. Questa etichetta serve a spiegare il ruolo giocato da quel nodo specifico nell’ambito del workflow che stiamo costruendo. In maniera predefinita, KNIME assegna come commento di ogni nuovo nodo aggiunto al workflow un semplice contatore, come Node 1, Node 2 e così via. Possiamo modificare il commento semplicemente facendo doppio clic su esso.
- I nodi sono collegati attraverso connettori o porte, che si trovano a sinistra e a destra del quadrato. Per convenzione, i connettori a sinistra sono di input, in quanto portano dati nel nodo, mentre quelle a destra sono porte di output, che portano i risultati dell’esecuzione del nodo. Queste porte possono avere forme e colori diversi, a seconda del tipo di contenuto che le attraversa: la maggior parte delle porte è a forma di triangolo e trasporta tabelle di dati, o dataset, ma le porte potrebbero anche essere a forma di quadrato (quando trasportano modelli statistici, connessioni remote o immagini) o di cerchio (variabili).
- Nella parte inferiore di ogni nodo, si trova sempre un semaforo che segnala lo stato attuale del nodo. Se la luce rossa del semaforo è accesa, il nodo non è ancora pronto per fare il suo lavoro: potrebbe essere, infatti, che alcuni dati richiesti in input non siano disponibili o che sia necessario qualche ulteriore passo di configurazione. Quando la luce è invece gialla il nodo ha tutto ciò che gli serve ed è pronto per essere eseguito, non appena gli viene comandato di farlo. La luce verde, come in tutti i semafori che si rispettino, è associato a una buona notizia: significa infatti che il nodo è stato eseguito con successo e i risultati sono disponibili ai connettori di output. Potrebbe avvenire che altre icone appaiano sul semaforo, indice che qualcosa non stia andando per il verso giusto: un triangolo giallo con un punto esclamativo segnala un warning, avvisandoci che qualcosa di insolito e potenzialmente errato richiede la nostra attenzione. Il cerchio rosso con una croce annuncia invece un errore bloccante che non permette quindi al nodo di essere in alcun modo eseguito. In questi casi, è possibile saperne di più su ciò che è andato storto mantenendo il puntatore del mouse su queste icone per un secondo (apparirà un’etichetta) o dando un’occhiata ai messaggi apparsi nella Console.
Come abbiamo già iniziato a vedere nel Node Repository, vi sono diverse famiglie di nodi disponibili in KNIME, ognuna delle quali risponde a una diversa classe di esigenze di data analytics. Ecco di seguito i tipi di nodi più popolari.
- Input e output: questi nodi portano i dati dentro e fuori KNIME. Normalmente, i nodi di input sono all’inizio dei workflow e servono ad aprire file in diversi formati (CSV, Excel, immagini, pagine web, per citarne alcuni) o a connettersi a database remoti ed estrarre i dati di cui si ha bisogno. Come si può vedere dalla figura chge segue, i nodi di input hanno solo connettori di output sulla destra e non hanno porte di input sulla sinistra (a meno che non richiedano una connessione con un database). Questo ha senso perché questi nodi hanno il ruolo di iniziare un workflow portando al suo interno dei dati, dopo averli letti da qualche parte. Al contrario, i nodi di uscita tendono a essere utilizzati alla fine di un workflow in quanto possono salvare i dati su file locali o sul cloud. Raramente questi nodi di output hanno porte sulla loro destra in quanto chiudono la nostra catena di operazioni.
- Manipolazione: questi nodi sono in grado di maneggiare tabelle di dati e trasformarle secondo le nostre esigenze. Possono aggregare, combinare, ordinare, filtrare e rimodellare le tabelle, ma anche gestirne i valori mancanti, normalizzare le scale e convertire i tipi di dato. Questi nodi, insieme a quelli della famiglia precedente, sono praticamente immancabili in qualsiasi workflow di data analytics: possono pulire congiuntamente i dati e prepararli nel formato richiesto dai passi successivi, come la creazione di un modello statistico, un report o un grafico. Questi nodi possono avere una o più porte di ingresso e una o più porte di uscita, essendo in grado di fondere più tabelle insieme o di suddividerle in più parti.
- Analytics: questi sono i nodi più smart (e anche i più interessanti) in quanto sono in grado di generare modelli statistici e di implementare gli algoritmi di intelligenza artificiale. Come si evince dalla prossima figura, alcune delle porte dei nodi di analytics sono quadrate, in quanto trasportano modelli statistici invece che tabelle di dati.
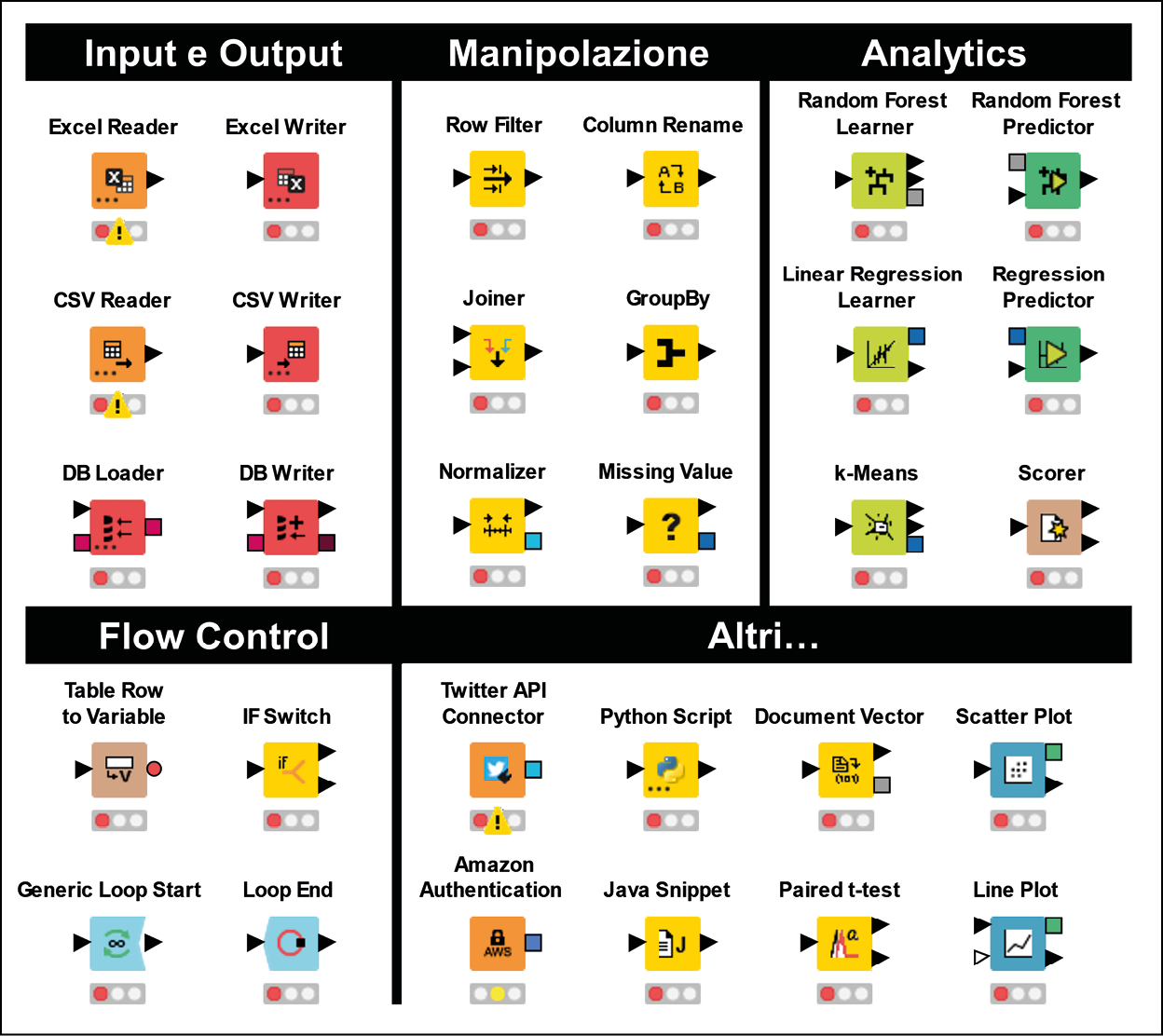
Una selezione di nodi KNIME per tipo: questi sono i mattoncini LEGO® del nostro flusso di analisi dei dati.
- Flow control: a volte, i nostri workflow avranno bisogno di andare oltre la semplice struttura lineare dove i dati scorrono seguendo una singola successione di nodi in serie. I nodi di questa categoria sono in grado di controllare il flusso di esecuzione del workflow implementando dei cicli (loop) in modo da poter ripetere dei passi più volte, come farebbe un programmatore utilizzando costrutti come
whileefor. In KNIME è possibile anche controllare dinamicamente il comportamento dei nodi, gestendone la configurazione attraverso variabili. I nodi di flow control ci permettono di gestire cicli e variabili e di implementare così logiche complesse: pur non avendone bisogno nella maggior parte dei casi, questi nodi sono una risorsa molto utile quando il gioco si fa duro. - Altri: oltre alle classi viste fino a questo punto, KNIME offre molti altri tipi di nodi che possono aiutarci nel gestire esigenze più specifiche. Alcuni nodi ci permettono per esempio di interagire sistematicamente con applicazioni terze attraverso interfacce di programmazione chiamate API (Application Programming Interfaces): per esempio, installando un’estensione chiamata KNIME Twitter Connectors, il repository si arricchirà di nodi che permettono di cercare tweet specifici o di scaricare in massa le informazioni pubbliche di una lista di utenti per poi analizzarle. Altre estensioni permettono di fondere KNIME con linguaggi di programmazione come Python e R in modo da introdurre frammenti di codice all’interno di un workflow in KNIME o, al contrario, di innestare i nostri workflow preparati in KNIME all’interno di un programma scritto in un altro linguaggio. Esistono anche nodi per eseguire test statistici e per costruire visualizzazioni o generare report complessi.
Mi auguro che il vedere il ventaglio così ampio di funzionalità implementate da tutti questi tipi di nodi abbia stuzzicato l’appetito per la data analytics!
Questo articolo richiama contenuti da Data Analytics per tutti.
Immagine di apertura di Joshua Sortino su Unsplash.
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Libri che potrebbero interessarti

Intelligenza Artificiale in pratica
Diventare maestri nell'utilizzo dei modelli OpenAI