
A tutti noi, più o meno quotidianamente, capita di dover confermare la nostra identità di esseri umani.Per ora non siamo ancora al test di Voight-Kampff, che in Blade Runner distinguiva i replicanti dagli originali. Siamo però testati da molti siti che chiedono una conferma del fatto che una scheda, un’informazione, un commento siano stati compilati da uno di noi e non da un qualche tipo di software sospetto, tipicamente dedicato allo spamming. Molto spesso questa identificazione assume la forma di una serie di caratteri, scritti con un font improbabile e/o pesantemente deformato – basandosi sull’assunto che una macchina non riuscirebbe facilmente a identificare la lettera nascosta, mentre l’accoppiata occhio/cervello/essere umano sì. Non tutti sanno che questo tipo di applicazioni vengono definite captcha, acronimo di Completely Automated Public Turing Test To Tell Computers and Humans Apart, ovvero il test di Turing pubblico e completamente automatico per distinguere gli umani dai computer.
Questo test è stato inventato nel 2000 alla Carnegie Mellon University per essere incorporato in nuove applicazioni di Yahoo!. Da allora, ogni secondo, orde di persone si prendono il maldipancia di decrittare il codice (ne vengono risolti oltre 60 milioni al giorno) in un’operazione che i malvagi software Ocr-simili degli spammer fanno fatica a decrittare. Qualcuno però, al menzionare Ocr in associazione a captcha deve essere saltato sulla sedia, quando ha intravisto una potenzalità dagli incredibili effetti benefici per la libera cultura dell’umanità. Come sappiamo, molteplici progetti di cultura open source stanno lavorando per indicizzare e digitalizzare un po’ tutta la summa dello scibile umano – specialmente quello scibile forse più a rischio in quanto non elaborato originariamente in formato digitale (traduzione per chi ha passato i 40: i libri, e si veda questo link per chi non si ricordasse di cosa si tratta).
Una soluzione per informatizzare il contenuto di vecchie pubblicazioni e manoscritti è quella di usare lo strumento più digitale di tutti e digitare con le vostre manine sante il testo battendolo sulla tastiera di un computer. Con tutte le conseguenze del caso. Una soluzione sempre laboriosa ma più veloce, è quella di passare tutto allo scanner, e di avere un software di Ocr che traduca la scansione in testo. In teoria molto meglio, in pratica – vista la scarsa affidabilità di questi software, specialmente per testi vecchi e macchiati, magari stampati in caratteri un po’ desueti – si ripropone il problema del controllo ortografico del testo e della sua correzione. Tutte cose che rallentano il processo di messa a disposizione del testo e complicano enormemente il flusso.
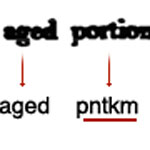
Ora, l’idea che ha dato origine al progetto ReCaptha è stata proprio questa. Se ci sono parole che gli Ocr fanno fatica a interpretare, queste sono ottime chiavi per proteggere la sicurezza dei siti. E se ci sono persone che decodificano correttamente queste chiavi, in realtà è come se stessero correggendo delle bozze. Per farla breve: ReCaptcha prende le parole che i computer fanno fatica a interpretare e le invia, come codice da risolvere, a quelle pagine che necessitano di un sistema di protezione – così invece di affrontare un termine generato casualmente, usate parole vere, tratte da chissà quali vecchi testi. La traduzione dell’utente abilitato, se considerata corretta, viene quindi inserita nel testo: in questo modo non solo abbiamo avuto il permesso di inserire un commento nel nostro blog preferito, ma abbiamo contribuito a validare un pezzetto di testo che domani sarà reso disponibile all’umanità. E considerando che si stima che gli Homo Sapiens dedichino ogni giorno 150.000 ore/uomo a risolvere quei benedetti puzzle identificativi, se anche solo una piccola parte di questo tempo venisse dedicata a tradurre antichi scritti l’acquisizione di materiali altrimenti difficilmente condivisibili farebbe un bel passo in avanti.
Ovviamente, sembra ci sia un grosso asino che stia per cadere, nel sistema. Se la parola criptata va decodificata, bisogna che il computer abbia la soluzione, in modo da decidere se la risposta è corretta o no. Ma se vi viene proposta la parola misteriosa che a messo in crisi l’Ocr, per definizione il computer la soluzione non la sa. In realtà, sveliamo il terribile segreto, vi fregano. A fin di bene, si intende: nel sistema Recaptcha dovete infatti tradurre due parole, non una. Una delle due (ma non sapete quale) è quella misteriosa. L’altra è generata dal computer con un sistema captcha. Se traducete correttamente quella generata, si presume abbiate fatto altrettanto per quella vera. E vi hanno così imbrogliato, trovando un pretesto per chiedervi di fare da traduttore per una parola scansionata male.
Così, se vi sentite magnanimi o socialmente committed e volete contribuire alla digitalizzazione dei testi analogici, potete dare un contributo e installare ReCaptcha nel vostro sito o blog. Il software viene offerto gratuitamente, si installa con quattro righe di codice e ha un’opzione di accessibilità incorporata – potendo recitare in audio le parole per tutti quelli che hanno problemi di visione. E sarà anche più piacevole per i vostri utenti accedere digitando termini come “lucerna cerulea” piuttosto che, come capita quotidianamente sul mio beneamato Blogger, YEPSPRURGW…
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo
