

Dettaglieremo tre diverse strategie per il data mining e della necessità di differenti strutture dati, processi computazionali, per soddisfare le utenze del tipico data warehouse.
Tempo addietro il data mining veniva considerato come un insieme di attività direttamente ricavabili da quelle associate ad un DW. Questa opinione non è più condivisa in generale, ed anzi i due ambienti tendono a divergere nettamente. Se un dw può essere una sorgente di dati per un’operazione di datamining, questa non è più considerata una costola computazionale di un dw. Si può dire di più, e cioè che addirittura, oltre all’indipendenza dal dw, il dataminig detta a volte le linee per l’implementazione di un dw di grosse dimensioni.
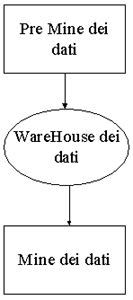
Il paradigma “prima costruisci un dw, poi scavi nelle informazioni” sembra essere stato soppiantato da un approccio che vede lo sforzo profuso per la costruzione di un dw calato in un contesto dove prima si comprende il dato e la sua natura, poi lo si immagazzina (fig.1)
Affinchè Warehouse e Mine lavorino insieme, i dati saranno posti in un repository coesistente o distinto dal DW, secondo un paradigma Sandwich.
Dati memorizzati, Analisi delle Informazioni
Lo scopo dei dw è quello di unire insieme grandi moli di dati storici da diverse sorgenti e usare successivamente i dati per processi che supportano le decisioni. La struttura di un sistema di supporto alle decisioni è mostrata in figura 2.
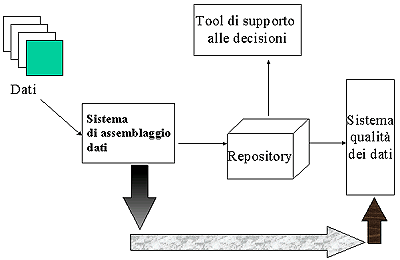
Éstato usato il termine repository piuttosto che warehouse in Figura 2, perché vedremo che il repository può avere componenti distinte come il warehouse ed il data mining. Le attività compiute su un repository sociale di grandi dimensioni sono di solito diverse, ma spesso includono compiti distinti come query e reporting, analisi multidimensionale ed estrazione del dati. Questi compiti naturalmente raggruppano separatamente gli utenti, anche a livello di processi computazionali.
Accessi ed analisi insistono su spazi computazionali diversi, ad esempio operazioni di query e reporting su spazi di dati, OLAP su spazi multidimensionali, data minig su spazi INFLUENCE. I quattro spazi che formano la base per il supporto alle decisioni sono evidenziati in fig.3. Un quinto spazio può sussistere quando esiste una necessità di particolari altre analisi, tipo quella geografica.
Un DW allora è sicuramente il posto fisico naturale per immagazzinare lo ‘spazio dati’. In esso memorizzeremo gli elementi di base utilizzati successivamente. E proprio come OLAP che non è considerato più come un puro sforzo computazionale diretto solo nel senso DW, un datamine è il luogo concettuale dove si elaborano analisi per trattare con lo spazio di INFLUENCE.
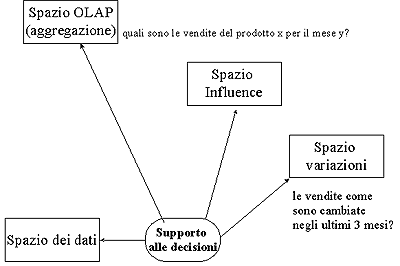
Le questioni poste per questi spazi sono differenti. Alcune come “che cosa influenza le vendite?” sono praticamente impossibili da risolvere direttamente dallo spazio dati. In più gli spazi derivati sono spesso così estesi che non possono essere pre computati e memorizzati come spazio dati; non di rado quindi, dobbiamo contare su una parziale pre computazione di questi spazi.
Lo spazio dati include tutte le informazioni contenute in altri spazi, ma meno definite di queste. Esso forma la base per la derivazione di altri spazi. Questi ultimi, comunque, una volta computati diventano reali a tutti gli effetti. Épossibile, allora, creare anche degli spazi ibridi come ad esempio lo spazio che permette analisi delle influenze su aggregazioni. Questi spazi ibridi forniscono dati molto più raffinati di quelli RAW che risiedono all’interno del DW.
Nel processo di analisi, lo spazio dei dati spesso necessità di ulteriori raffinamenti ottenibili ad esempio con gerarchie e comportamenti periodici. In generale questa aggiunta semantica non implica uno sforzo notevole dal punto di vista progettuale, e nello stesso tempo fornisce un valore aggiunto di fondamentale importanza per l’utente finale. L’esempio è quello classico della gerarchia temporale (anno mese giorno) e di quella geografica (città stato continente) che il modello relazionale non fornisce direttamente, ma che in ambito OLAP danno un aiuto sostanziale alle navigazioni dell’utente.
Mentre lo spazio OLAP tratta computazioni che sono prettamente valori numerici, lo spazio di influenza ha una natura logica. Esso tratta la particolare influenza che alcuni item hanno su altri item. Ciò che rende questo spazio molto interessante rispetto agli altri è la caratteristica di generalità che le sue informazioni hanno, a tal punto da poter essere definite conoscenza. Si comprende ancor di più la loro importanza se si pensa che oggi l’informazione è un patrimonio inestimabile vista la complessità della società contemporanea.
Si dovrebbe comunque notare che la taglia dello spazio di influenza e il numero di combinazioni logiche dei fattori di influenza può essere estremamente alto, rendendo improponibile un’attività di pre calcolo di tale spazio. Restringere troppo questo spazio non aiuterebbe in quanto lo scopo è quello di trovare particolari pattern inaspettati ed una riduzione degli spazi potrebbe compromettere tale ricerca. LA dinamicità è quindi una caratteristica di questo tipo di scoperta, ed inoltre ogni qual volta particolari item riescono ad essere evidenziati l’utente penserà immediatamente ad un nuovo item da ricercare e scoprire per i suoi scopi: ancora il dinamismo di ricerca in evidenza.
Analisi Esplorativa e Confermativa
Si definisce data mining (DM) un processo di supporto decisionale nel quale cerchiamo particolari pattern all’interno dei dati a disposizione. Tale ricerca può essere fatta dall’utente operando query oppure può essere assistita da programmi che automaticamente ricercano pattern significativi: tale processo è definito discovery. Quindi discovery vuol dire cercare un pattern in un data base senza avere una idea predeterminata o un’ipotesi circa la natura di quel pattern. In altri termini il programma ricerca quei pattern, secondo le impostazioni ricevute, che sono interessanti senza l’intervento dell’utente. In grandi data base esistono così tanti pattern che l’utente non potrà mai pensare alla query giusta per individuarli tutti. Da un punto di vista statistico esistono due tipi di analisi: Confermativa ed Esplorativa. Nella prima l’utente ha una serie di ipotesi che conferma o confuta attraverso una linea di ragionamento statistico deduttivo. Il collo di bottiglia per questo tipo di analisi è la scarsità di ipotesi da parte dell’analista. Nella seconda, invece, si cercano appropriate ipotesi per confutare o meno. La ricerca automatizzata permette ad analisti non appartenenti al settore specifica dell’analisi statistica di esplorare grandi moli di dati molto efficacemente. Il DW può essere un luogo dove poter operare analisi di tipo confermativo guardando allo spazio dei dati, e certamente non è il luogo dove operare un’analisi di tipo esplorativo per la difficile definizione della natura delle query fatte sui dati: il posto naturale dove fare un’analisi esplorativa è invece il datamine.
Il Paradosso dei pattern in un WareHouse
Il concetto di warehouse “grande” e di pattern “utili” spesso si relazionano in una maniera apparentemente paradossale. Ovviamente più grande è il DW più ricco è il suo contenuto di pattern. Del resto, però, ad un certo punto se analizziamo porzioni di DW troppo grandi i pattern in diversi segmenti di dati incominciano a sovrapporsi e consequenzialmente decrescono quelli utilizzabili.
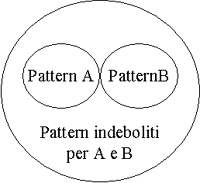
L’idea nodale, mostrata in fig.4, è esemplificata considerando quanto segue: consideriamo un DW che contiene informazioni relative ai conti dei clienti di un istituto bancario, promozioni di mercato, ecc; possono esserci diversi interessi legati a questi dati, come attività di risk management, campagne promozionali, segmentazione della clientela, ecc. Questi citati sono business task differenti e quindi non ha senso confondere le analisi, ma è necessario anzi separarle perché ognuna richiederà differenti strutture dati. Di solito, infatti, le analisi su campagne promozionali non coinvolgono l’intero DW e le banche hanno un certo numero di campagne che contemplano un certo numero di prodotti e che indirizzano un particolare target di clienti. Per capire quale cliente risponderà favorevolmente alle sollecitazioni della campagna propostagli, bisognerà analizzare ogni campagna separatamente perché ogni caso coinvolgerà differenti pattern con differenti impronte; un mix delle analisi dal punto di vista del DM smusserà le differenze tra impronte. Se sarà necessario bisognerà poi avere diverse sessioni di analisi per ogni gruppo di campagne perchè tra loro alcune campagne potrebbero risultare talmente differenti da invalidare la fase di mix per assenza di significato.
Per esempio, assumiamo che i quarantenni con più di due figli abbiano un favorevole impatto con campagne riguardanti la promozione di carte di credito. Assumiamo anche che quelli che hanno meno di quaranta anni con un solo figlio potrebbero aprire un nuovo conto bancario. Se noi combinassimo queste due campagne all’interno della stessa strategia di DM e guardassimo semplicemente ai clienti con un alto indice di accoglienza della campagna, questi due pattern sovrasterebbero qualsiasi altro pattern.
Certamente potremmo considerare una regola tale da separare queste campagne e visualizzare i pattern, ma in DW di grandi dimensioni tali regole potrebbero proliferare in maniera insostenibile.
Le necessità per la segmentazione sono più chiare quando consideriamo modelli predittivi. Quando si prova a predire un risultato legato ad una campagna promozionale non ha senso basare la previsione su tutte le campagne precedenti,ma solo su quelle campagne che sono più simile a quella considerata nella previsione. Per esempio, la campagna per un nuovo conto bancario può avere una certa attinenza sul responso per campagne per nuove carte di credito. In questo caso il paradosso prima descritto si evidenzia perché considerando più dati perdiamo di accuratezza; alcuni dati considerati certamente non interessano il tipo di analisi che stiamo facendo.
Cosa accade se esistono due o più indicatori che sono comuni a tutte le compagnie ? andranno persi se noi analizziamo la campagna un pòalla volta ? No, infatti, se un pattern è fortemente presente nell’intero db lo sarà anche nel segmento: ad esempio, il fatto che coloro che hanno più di cinque figli non rispondono mai alla campagna sarà contenuto anche nel segmento.
Come altro esempio consideriamo un db delle assicurazioni per veicoli. Per trovare pattern sulle richieste del cliente, è essenziale immagazzinare ogni dettaglio di richiesta in un DW. Évantaggioso analizzare tutto il DW nello stesso momento ? No, ogni vettura è di tipo diverso e costruita con parti diverse e nel tempo anche questi caratteri variano. In effetti analizzare tutto il DW non ci aiuta più che analizzare una delle sue parti. La migliore pratica è quella di analizzare le richieste del cliente per macchine di un certo modello costruite con un certo progetto in un dato anno, quindi una segmentazione.
Il più delle volte siamo avvantaggiati nel considerare un segmento estratto dalla totalità del DW (non un campione) che rispecchi l’obiettivo del business, quindi prepararlo per la fase di DM piuttosto che considerare l’interezza del DW nel quale i pattern interessanti risentono del paradosso del DW.
L'autore

Iscriviti alla newsletter
Novità, promozioni e approfondimenti per imparare sempre qualcosa di nuovo

Corsi che potrebbero interessarti

Big Data Analytics - Iniziare Bene
Libri che potrebbero interessarti


